现代大语言模型(Modern Large Language Models) #
预训练基础知识 #
⁉️ 什么是预训练?与传统监督学习的区别?
什么是预训练?与传统监督学习的区别?
预训练(Pretraining)是一种在大规模无标注数据(Unlabeled Data)上训练深度学习模型的技术,特别常用于自然语言处理(NLP)中的大规模语言模型。在预训练阶段,模型通常采用 自监督学习(Self-Supervised Learning)方法,通过预测被遮蔽的词(如 BERT 的掩码语言模型 Masked Language Model, MLM)或基于上下文预测下一个词(如 GPT 的自回归语言模型 Autoregressive Language Model, AR)来学习文本的统计特性和语义表示(Semantic Representation)。
相比传统的监督学习(Supervised Learning),预训练 不需要大量人工标注数据,而是利用大规模无标签语料,使模型具备广泛的语言理解能力。随后,模型可以通过 微调(Fine-Tuning)在小规模标注数据上进一步优化,以适应具体任务。这种方式相比传统监督学习更加高效,尤其适用于数据标注成本高的任务,同时提升模型的泛化能力(Generalization Ability)和适应性(Adaptability)。
Note:Pre-training 是在 大规模无监督数据上训练模型,而 Fine-tuning 是在 特定任务或数据集上对模型进行微调。
⁉️ LLM 的预训练流程通常涉及到哪些环节?
LLM 的预训练流程通常涉及到哪些环节?
在 大规模语言模型(LLM, Large Language Model) 的 预训练(Pretraining) 过程中,整个流程可以从宏观的角度划分为 数据收集与预处理、模型架构设计、训练目标设定、优化与梯度更新、以及分布式训练 五个关键部分,每一部分在模型能力的提升上都起着至关重要的作用。
- 数据收集与预处理(Data Collection & Preprocessing):预训练的第一步是收集大规模、高质量的数据集,通常包括 网络文本(web corpus)、书籍(books)、维基百科(Wikipedia)、代码数据(code repositories) 等多种来源。数据经过 去重(deduplication)、格式化(formatting)、分词(tokenization) 等预处理步骤,以确保输入的数据干净、标准化,并能有效地被神经网络处理。此外,还可能应用 文本过滤(text filtering) 和 去毒化(detoxification) 以减少偏见(bias mitigation)和不良内容。
- 模型架构设计(Model Architecture Design):现代 LLM 主要采用 Transformer 架构,其核心是 自注意力机制(Self-Attention Mechanism),能够有效建模长距离依赖(long-range dependencies)。具体的设计可能包括 解码器(Decoder-only, 如 GPT 系列) 或 编码器-解码器(Encoder-Decoder, 如 T5) 结构,参数规模从数亿到数千亿不等。此外,还涉及 层数(number of layers)、隐藏维度(hidden size)、多头注意力(multi-head attention)、前馈网络(feedforward network) 等关键超参数的选择。
- 训练目标设定(Training Objectives):LLM 的预训练目标通常基于 自监督学习(Self-Supervised Learning),主要分为:
- 自回归目标(Autoregressive Objective, AR):如 GPT 系列使用的 因果语言建模(Causal Language Modeling, CLM),即通过已知的上下文预测下一个单词。
- 自编码目标(Autoencoding Objective, AE):如 BERT 采用的 掩码语言建模(Masked Language Modeling, MLM),即在输入中随机掩盖(mask)部分单词,并让模型预测原始单词。
- 对比学习(Contrastive Learning) 和 指令调优(Instruction Tuning) 在部分预训练或微调阶段也会用到,以提升模型的表示能力。
- 优化与梯度更新(Optimization & Gradient Updates):预训练的核心是基于 梯度下降(Gradient Descent) 进行参数优化,具体采用 AdamW(带权重衰减的 Adam 优化器)来减少过拟合(overfitting)。此外,由于 LLM 训练涉及超大规模的参数,通常会使用:
- 混合精度训练(Mixed Precision Training, FP16/BF16) 降低计算成本。
- 梯度裁剪(Gradient Clipping) 解决梯度爆炸(Gradient Explosion)。
- 学习率调度(Learning Rate Scheduling, 如 Cosine Decay, Warmup) 提升收敛效率。
- 分布式训练(Distributed Training):由于 LLM 规模巨大,单机难以承载完整计算,因此需要分布式训练,包括:
- 数据并行(Data Parallelism, DP):多个 GPU 处理相同的模型,但分配不同的数据批次(batches)。
- 模型并行(Model Parallelism, MP):模型的不同部分分布在多个 GPU 计算,适用于超大参数模型。
- 流水线并行(Pipeline Parallelism) 和 张量并行(Tensor Parallelism) 结合使用,以提升大模型的计算效率。
⁉️ 解释Encoder-only,Encoder-Decoder,Decoder-only 三种模式的区别以及使用场景?
解释Encoder-only,Encoder-Decoder,Decoder-only 三种模式的区别以及使用场景?
Encoder-only 模式:在这种架构中,只有 编码器(Encoder) 部分用于处理输入数据,通常应用于 文本分类(Text Classification)、命名实体识别(Named Entity Recognition, NER) 和 情感分析(Sentiment Analysis) 等任务。该模式的主要任务是从输入序列中提取信息,生成固定长度的表示,适用于 需要理解输入而不生成输出 的任务。例如,BERT 就是一个典型的 Encoder-only 模型,通过 自注意力机制(Self-Attention) 学习输入文本的上下文信息并生成表示。
Encoder-Decoder 模式:这种架构包含一个 编码器(Encoder) 和一个 解码器(Decoder),用于从输入生成输出。输入通过编码器进行处理,得到一个上下文表示,然后解码器根据这个表示生成最终输出。这种结构非常适合 序列到序列任务(Sequence-to-Sequence Tasks),如 机器翻译(Machine Translation) 和 文本摘要(Text Summarization)。
Decoder-only 模式:这种架构仅包含 解码器(Decoder),通常用于 自回归生成任务(Autoregressive Generation Tasks),例如 文本生成(Text Generation) 和 语言建模(Language Modeling)。在这种模式下,模型根据前面的输入和已经生成的词预测下一个词。一个典型的例子是 GPT 系列模型,它基于 Decoder-only 架构,通过不断预测下一个词来生成连贯的文本。此模式非常适用于 需要根据上下文生成输出 的任务。
预训练细节 #
⁉️ 什么是参数初始化?有哪些适合 LLM 训练的参数初始化策略(Parameter Initialization)?
什么是参数初始化?有哪些适合 LLM 训练的参数初始化策略(Parameter Initialization)?
参数初始化(Parameter Initialization) 是神经网络训练中的一个关键步骤,旨在为 网络的权重(weights)和偏置(biases)赋予初始值。这些初始值对模型的训练收敛速度、稳定性及最终性能有着重要影响。合理的参数初始化策略能够避免梯度消失(Vanishing Gradient)或梯度爆炸(Exploding Gradient)等问题,进而提高训练效率。
对于 大规模语言模型(Large Language Models, LLM) 的训练,一些常见且适用的参数初始化策略包括:
- Xavier 初始化(Xavier Initialization):也叫做 Glorot 初始化,它通过考虑输入和输出的神经元数量来设置权重的方差。具体来说,权重的方差设置为:
其中 n_in 和 n_out 分别是当前层的输入和输出神经元数量。此策略通常用于 sigmoid 或 tanh 激活函数的网络,能够帮助缓解梯度消失问题。
Note:Xavier 初始化适用于激活函数是 sigmoid 或 tanh 的网络的原因是这些激活函数的导数容易趋于零,尤其是在输入值落入激活函数的饱和区(Sigmoid 的两侧平坦区域)。如果权重初始化过大,输入会快速进入饱和区,导致梯度消失。如果权重初始化过小,输出信号会逐层衰减,最终导致梯度消失。
Xavier 的初始化方法将权重分布限定在一个较小的范围内,使输入值主要分布在 Sigmoid 和 Tanh 的线性区,避免梯度消失。在较深的网络中,信号可能仍会因为层数的累积效应导致衰减或放大。
- He 初始化(He Initialization):类似于 Xavier 初始化,但特别适用于 ReLU 激活函数。它通过设置权重的方差,有效地解决了 ReLU 激活函数中常见的 dying ReLU 问题,即一些神经元始终不激活。
Note:He 初始化适用于激活函数是ReLU及其变种的原因是对于 ReLU,当输入为负时,输出恒为 0;当输入为正时,输出为原值。由于一部分神经元输出会被截断为 0,导致有效的参与计算的神经元数量减少(称为“稀疏激活”现象)。如果初始化权重过小,信号会迅速减弱,导致梯度消失;而如果权重过大,信号会迅速放大,导致梯度爆炸。
He 初始化通过设定较大的方差,补偿了 ReLU 截断负值导致的信号损失。这样可以让激活值的分布更均衡,避免信号快速衰减或放大。He 初始化根据输入层大小调整权重的方差,使每层的输出方差保持相对稳定,即使网络层数增加,信号也不会显著衰减或爆炸。
- Pretrained Initialization:对于 LLM,使用在大规模数据集上预训练的权重作为初始化参数(例如 BERT、GPT)是一种常见且有效的做法。通过 迁移学习(Transfer Learning),这种初始化策略能够显著加速训练过程,并提升模型的性能。
⁉️ LLM 预训练中为什么常用 Adam 或 AdamW 优化器?
LLM 预训练中为什么常用 Adam 或 AdamW 优化器?
在大规模语言模型(Large Language Model, LLM)预训练中,Adam 和 AdamW 优化器被广泛采用,主要是因为它们具备高效处理 非平稳目标函数(non-stationary objective functions)和稀疏梯度(sparse gradients) 的能力,并能显著 提升训练稳定性与收敛速度。
- Adam(Adaptive Moment Estimation) 优化器的核心思想是对每个参数维护一阶矩估计
m_t和二阶矩估计v_t,即梯度的一阶与二阶指数加权平均值,其更新公式如下:
在大规模模型训练中,Adam 的自适应性特别关键:它为每个参数独立调整学习率,使训练过程对初始学习率的选择更加鲁棒,尤其在 early training phase 能更快收敛;同时一阶与二阶动量估计也减缓了梯度震荡,稳定了训练轨迹。
- AdamW(Adam with decoupled weight decay) 是对 Adam 的一个重要改进。在原始 Adam 中引入 L2 正则项时,正则化项被错误地加入到了梯度更新路径中,违背了权重衰减(Weight Decay)应独立于梯度计算的原则。AdamW 正确地将权重衰减项从梯度更新中解耦出来:
这里 λ 是 weight decay 系数,直接对参数进行衰减,从而更有效地控制模型容量,减少过拟合。此策略被证明在 Transformer-based 模型(如 BERT、GPT、T5)预训练中效果更优,是现代预训练标准范式的一部分。
⁉️ 什么是 Gradient Clipping?在预训练中它通常怎么设置?
什么是 Gradient Clipping?在预训练中它通常怎么设置?
Gradient Clipping(梯度裁剪) 是一种用于稳定神经网络训练过程的技巧,尤其常用于训练大型模型如 Transformer 或 LLM(Large Language Models)。在深度网络中,尤其是带有大量参数和长序列依赖的模型中,反向传播过程中可能出现 梯度爆炸(Gradient Explosion) 的问题,即某些参数的梯度异常大,导致参数更新过猛,从而使 loss 发散甚至出现 NaN。Gradient Clipping 的作用就是在这种情况下对梯度进行限制,防止模型参数的更新幅度过大,从而提高训练的稳定性。
在数学上,假设当前参数 \theta 的总梯度向量是:
$$ g = \nabla_\theta \mathcal{L}(\theta) $$
我们可以计算它的 L2 范数(Euclidean norm)
$$ ||g||_2 = \sqrt{\sum_i g_i^2} $$
然后我们设置一个阈值 τ(通常是一个小正数,比如 1.0 或 0.5),当梯度范数超过阈值时,我们将梯度按比例缩放,使得其范数不超过 τ,公式如下:
\[ g{\prime} = \begin{cases} g & \text{if } \|g\|_2 \le \tau \\ \tau \cdot \frac{g}{\|g\|_2} & \text{if } \|g\|_2 > \tau \end{cases} \]也就是说,如果梯度“太大”,我们就把它整个向量缩放到阈值 τ 的长度。这样的缩放是向量级别的,不会改变方向,但会限制更新步长,从而避免模型训练时的不稳定震荡。
Note:在实际的 LLM 预训练中,Gradient Clipping 是一个非常常见的稳定技巧,尤其是在使用 mixed precision training(如 FP16)时,浮点数表示范围更窄,更容易发生梯度爆炸。通常的设置方式是:
- 使用 global norm clipping(全局范数裁剪),即不是每层单独裁剪,而是对所有参数梯度的联合向量做裁剪;
- 裁剪阈值设置为 1.0 是最常见的经验值;
- 在实现上,大多数框架(如 PyTorch)提供内置函数,如
torch.nn.utils.clip_grad_norm_()来自动完成这一操作;- 在 Transformer-based 模型(如 BERT、GPT、T5)的大规模预训练中,Gradient Clipping 常常与 learning rate scheduler、warm-up 策略等配合使用以确保训练稳定。
⁉️ 为什么大模型预训练时通常需要 Warmup 学习率策略?
为什么大模型预训练时通常需要 Warmup 学习率策略?
在大规模语言模型(Large Language Models, 简称 LLM)预训练的初期,通常会采用 Warmup 学习率策略(Warmup Learning Rate Strategy),其核心目的是为了防止训练初期参数剧烈震荡,提升模型稳定性和收敛速度。
具体来说,训练神经网络时,尤其是 Transformer 这类具有复杂残差结构(Residual Connections)和层归一化(Layer Normalization)的模型,如果在刚开始使用一个较大的学习率(Learning Rate),模型的参数尚未调整到合适的尺度,会导致梯度过大,引发梯度爆炸(Gradient Explosion)或者优化方向震荡,从而影响模型性能甚至训练失败。而 Warmup 策略通过在前若干步逐渐提升学习率,让网络在参数尚未稳定时“热启动”,逐步适应学习率的放大,从而缓解初期训练不稳定的问题。以 Transformer 原始论文中的学习率调度为例,其学习率调度公式如下:
\[ \text{lr}(t) = d_{\text{model}}^{-0.5} \cdot \min(t^{-0.5}, \ t \cdot \text{warmup\_steps}^{-1.5}) \]整个公式的含义是:前 warmup_steps 步中,学习率呈线性上升;之后则以 t^{-0.5} 的速度衰减。 这种策略结合了 Warmup + Inverse Square Root Decay 的优势,使得训练初期更加平稳,训练后期又具有良好的收敛性能。
⁉️ 如何理解训练中 Batch Size 和模型收敛的关系?
如何理解训练中 Batch Size 和模型收敛的关系?
在大型语言模型(LLM, Large Language Model)训练中,Batch Size(批大小)是影响模型收敛速度、性能表现和最终泛化能力的关键超参数之一。Batch Size 指的是 每次参数更新时使用的样本数量,它与 梯度估计的稳定性 和 优化路径的收敛特性 密切相关。
当使用较小的 batch size 时,梯度估计具有更高的方差(variance),训练过程较为“嘈杂”,这虽然可能导致训练过程不稳定,但也能更容易跳出局部最优,具有较强的正则化效果(即有助于泛化)。而使用较大的 batch size,梯度估计更加精确,训练曲线更平滑,可以更稳定地收敛,但也更容易陷入平稳鞍点(sharp minima),泛化能力下降。
一种常见的经验法则是:在扩大 batch size 的同时同步增大学习率(Learning Rate)。
在 LLM 训练中,batch size 越大,优化器状态(如梯度一阶和二阶动量) 的稳定性越好,同时训练可以更高效并行化。值得注意的是,large-batch training 面临“generalization gap”问题:在相同训练 loss 下,较大的 batch size 通常泛化误差更高(test loss 更大)。
⁉️ 为什么大模型会出现幻觉(Hallucination)?如何检测和减少?
为什么大模型会出现幻觉(Hallucination)?如何检测和减少?
大语言模型(LLM)产生幻觉(Hallucination)的本质原因,是它在生成内容时不依赖事实性记忆或知识库,而是基于训练过程中学到的统计相关性模式(statistical co-occurrence patterns)。语言模型通常使用 maximum likelihood estimation(MLE) 训练目标,即最大化下一个词的条件概率:
$$ \max_\theta \sum_{t=1}^{T} \log P_\theta(w_t \mid w_1, \ldots, w_{t-1}) $$
这种训练方式鼓励模型在给定上下文下生成最可能的词,而非最“正确”的词。如果训练数据中存在矛盾、虚假、或低质量内容,模型可能会学到错误相关性,并在推理时“自信地编造”不存在的事实,从而产生幻觉。
此外,当前主流的 LLM 如 GPT 系列是 decoder-only 架构,缺乏内建的知识查询机制(如检索模块),也缺少对事实一致性的显式建模能力(例如逻辑一致性、实体对齐)。当输入提示(prompt)模糊、开放性高,或涉及冷门事实时,模型只能根据相似上下文生成“可能对但未必正确”的输出,幻觉风险大幅增加。
减少幻觉的有效方法包括:
- 强化训练数据质量:使用高质量、事实一致的文本进行预训练和微调;避免使用社交媒体等噪声源。
- 加入外部知识源(Retrieval-Augmented Generation, RAG):通过检索模块提供支持内容,再交由生成器解码,形成“生成-检索耦合系统”。
- 后训练微调(Instruction tuning / RLHF):用人类标注反馈指导模型偏向真实、有用的回答,尤其强化“拒答能力(refusal when unsure)”。
⁉️ LLM 中有哪些常用的 Activation 函数
LLM 中有哪些常用的 Activation 函数?
在大规模语言模型(LLM, Large Language Models)中,激活函数(activation functions)主要用于前馈网络(FFN, Feed-Forward Network)中的非线性变换部分,对模型的训练稳定性、收敛速度、非线性表达能力等有重要影响。
- ReLU 是最经典的激活函数之一,定义为:
$$ \text{ReLU}(x) = \max(0, x) $$
它具有稀疏激活(sparse activation)和计算效率高的优点,但存在 dying ReLU 问题,即负值区域梯度恒为零,可能导致神经元在训练中永久失效。
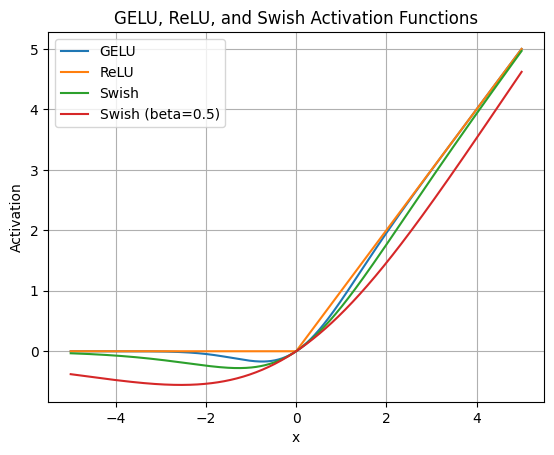
- 随后被广泛采用的是 GELU,它在 Transformer 模型中尤其常见(如 BERT 和 RoBERTa)。其定义是:
$$ \text{GELU}(x) = x \cdot \Phi(x) $$
其中 Φ(x) 是标准正态分布的累积分布函数(CDF)。GELU 具有平滑非线性特性,并且能够更细腻地处理输入,尤其在零附近不会像 ReLU 那样直接“截断”,而是引入一定的概率性,这被认为能提升表示能力和模型性能。其近似公式也常被使用:
$$ \text{GELU}(x) \approx 0.5x \left(1 + \tanh\left(\sqrt{\frac{2}{\pi}}(x + 0.044715x^3)\right)\right) $$
GELU 相较 ReLU 在大模型中表现更稳定,是当前 LLM 默认激活函数之一。
- SiLU(或称 Swish) 是 Google 提出的另一种平滑激活函数,其定义为:
$$ \text{SiLU}(x) = x \cdot \sigma(x) $$
其中 σ(x) 是 Sigmoid 函数。与 GELU 类似,SiLU 也在输入为负时保留部分梯度,不会像 ReLU 那样完全“关掉”,因此能减缓 dying neuron 问题。它的梯度连续,在某些任务中比 GELU 表现更好
模型评估与调优 #
⁉️ 困惑度(Perplexity)的物理意义是什么?为什么不能完全依赖它评估模型?
困惑度(Perplexity)的物理意义是什么?为什么不能完全依赖它评估模型?
困惑度(Perplexity)是衡量语言模型预测能力的经典指标,其物理意义可以理解为“模型在面对当前语言任务时的不确定性”或者“平均每一步预测所面临的选择数量”。数学上,如果一个模型对长度为 N 的真实序列 x_1, x_2, …, x_N 的联合概率为 P(x_1, …, x_N),那么困惑度定义为:
$$ \text{Perplexity} = P(x_1, x_2, …, x_N)^{-\frac{1}{N}} = \exp\left( -\frac{1}{N} \sum_{i=1}^N \log P(x_i | x_1, …, x_{i-1}) \right) $$
也就是说,困惑度本质上是平均负对数似然(Negative Log-Likelihood, NLL)的指数形式。困惑度越小,表示模型越“确信”自己的预测,说明语言建模能力越强。但在实际应用中,困惑度不能作为评估模型好坏的唯一标准,原因主要有以下几点:
首先,困惑度 只衡量了模型在训练集或验证集上的语言流畅性预测能力,它并不考虑任务完成度或输出的语义质量。比如一个困惑度很低的模型可能在生成对话时语法无误但语义空洞、脱离上下文,无法有效完成如问答、摘要等任务。
其次,困惑度具有不可跨模型或tokenizer比较的局限性。不同模型的词表(Vocabulary)大小不同,Tokenization策略不同(如BPE、WordPiece、SentencePiece),即使输入文本相同,模型面对的token序列结构也不同,导致困惑度不具备一致可比性。
⁉️ BLEU、ROUGE 等指标分别适用于哪些任务?各自的局限性是什么?
BLEU、ROUGE 等指标分别适用于哪些任务?各自的局限性是什么?
BLEU 是最早出现并被广泛采用的自动评估指标,主要用于机器翻译,它通过 计算生成文本与参考文本之间 n-gram 的精确匹配比例(Precision) 来打分,同时引入惩罚机制防止输出太短(brevity penalty)。公式如下:
$$ BLEU = BP \cdot \exp\left( \sum_{n=1}^N w_n \log p_n \right) $$
其中
p_n是 n-gram 的 precision,w_n是权重(常为均值),BP 是惩罚项。但 BLEU 的缺点是 对词序极其敏感,且无法处理同义词或语义相似句式,因而对开放式文本生成任务(如对话、写作)不够鲁棒。相比之下,ROUGE 常用于文本摘要(Summarization)等任务,尤其在评估生成文本能否覆盖参考答案的“内容片段”时更为有效。最常用的变体是 ROUGE-N(n-gram recall)、ROUGE-L(Longest Common Subsequence)和 ROUGE-W(加权 LCS)。ROUGE 更偏重 recall,尤其适合多参考、多摘要句的任务。它的优势是能够在一定程度上衡量覆盖度和冗余度,适合摘要、问答等任务。
- ROUGE-N 衡量的是模型生成文本中,有多少 n-gram 出现在参考文本中,强调召回率(recall)而不是精确率(precision),适用于摘要类任务。
$$ \text{ROUGE-N} = \frac{\sum_{S \in {\text{Reference Summaries}}} \sum_{\text{gram}n \in S} \text{Count}{\text{match}}(\text{gram}n)}{\sum{S \in {\text{Reference Summaries}}} \sum_{\text{gram}_n \in S} \text{Count}(\text{gram}_n)} $$
ROUGE-L 更关注生成文本与参考文本之间的“结构对齐”能力,使用 LCS 计算两个序列的重叠度。
$$ \text{ROUGE-L}{\text{recall}} = \frac{LCS(X, Y)}{\text{length}(X)} \qquad \text{ROUGE-L}{\text{precision}} = \frac{LCS(X, Y)}{\text{length}(Y)} $$
再结合 F1 得分表示:
$$ \text{ROUGE-L}_{F1} = \frac{(1 + \beta^2) \cdot \text{Precision} \cdot \text{Recall}}{\text{Recall} + \beta^2 \cdot \text{Precision}} $$
不过,ROUGE 也存在一些问题:它同样忽略语义、上下文,并且对于表达精炼或抽象的高质量生成内容,分数可能偏低。同时,当参考答案多样化时,ROUGE 和 BLEU 都无法覆盖所有“可能正确”的输出,限制了它们的普适性。因此,在实际工程中,这些指标往往需要配合人类评估(human evaluation)或更复杂的语义指标(如 BERTScore、BLEURT)来综合使用。
⁉️ 什么是 BERTScore、BLEURT?这些指标分别适用于哪些任务?
什么是 BERTScore、BLEURT?这些指标分别适用于哪些任务?
BERTScore 利用 BERT 等预训练模型的中间层表示,将参考文本(Reference)和生成文本(Candidate)中的每个 Token 表示为向量,通过余弦相似度(Cosine Similarity)进行对齐匹配,计算出三种统计量:Precision、Recall 和 F1 分数,其核心公式为:
\[ \text{Precision} = \frac{1}{|C|} \sum_{c \in C} \max_{r \in R} \cos(\vec{c}, \vec{r}) \\ \text{Recall} = \frac{1}{|R|} \sum_{r \in R} \max_{c \in C} \cos(\vec{r}, \vec{c}) \\ \text{F1} = \frac{2 \cdot \text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} \]其中 C 为生成文本的 Token 集合,R 为参考文本。由于它是基于上下文向量而非表层词面匹配,BERTScore 特别适用于语义重构明显的任务,如 abstractive summarization(抽象型摘要)或 paraphrase generation(复述生成),能较好捕捉同义表达。但其局限在于:1)对拼写错误、语法错乱较敏感;2)token 对齐基于贪心策略(greedy matching),可能忽略全局信息;3)无法区分 factuality(事实正确性)问题,即即使输出文本与参考在语义上相似,也可能是幻觉(hallucination)。
而 BLEURT(Bilingual Evaluation Understudy with Representations from Transformers) 是一种利用 BERT 的 fine-tuned regression 模型来模拟人类打分的 metric,它通过在大量含有人类标注分数的数据上监督训练,学习一个从文本对映射到 [0,1] 评分的函数,拟合人类的质量判断。BLEURT 更适用于评估自然语言生成质量的 overall 质量感知(perceived quality),尤其适合机器翻译(MT)等任务的自动打分,是一种 reference-based、regression-style metric。其优势在于:1)强大的泛化能力(fine-tuned on diverse MT corpora);2)可区分 fluent-but-wrong 与 accurate-but-awkward 输出。但它的劣势在于:1)对 domain shift 较敏感,可能无法泛化到摘要或对话等非翻译任务;2)计算开销较大;3)需引用参考答案,不能用作无参考(reference-free)评估。
⁉️ 总结对于不同LLM任务,最常见的评估方法?
总结对于不同LLM任务,最常见的评估方法?
在 分类任务(如情感分析、自然语言推断、实体识别) 中,最常见的评估指标包括 Accuracy(准确率)、Precision(精确率)、Recall(召回率)和 F1-score(F1 值)。当正负样本不平衡时,Accuracy 可能会失效,因此更推荐使用 F1-score 这一调和平均指标:
$$ \text{F1} = \frac{2 \cdot \text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} $$
对于 问答任务,评估方式依赖任务形式。如果是抽取式问答(Extractive QA,如 SQuAD),通常采用 Exact Match(EM)和 token-level F1-score 来衡量预测答案与标准答案的重叠程度。若是生成式问答(如开放领域问答或知识问答),则需采用 BLEU、ROUGE、BERTScore 或 GPTScore 等自动评估指标,其中:
- ROUGE 主要衡量召回(尤其适合摘要任务);
- BLEU 偏重精确率(适用于翻译);
- BERTScore 引入语义嵌入(semantic embeddings)比较句子层面的相似性,适用于多样化答案。
在 机器翻译(Machine Translation) 任务中,BLEU(Bilingual Evaluation Understudy)是历史最悠久的指标之一。它基于 n-gram 重叠,但忽略语义,容易对多样性模型不友好。近年来,COMET 和 BLEURT 等通过预训练语言模型打分,提供更强的参考相关性。
文本摘要任务(Text Summarization) 中,主流指标为 ROUGE-1(unigram)、ROUGE-2(bigram)和 ROUGE-L(最长公共子序列),但对于抽象式生成的质量仍有局限,因此常结合人类评价或使用 BERTScore、QAFactEval 等结构性指标衡量“事实一致性(factual consistency)”。
对于 对话系统,传统评估方式包括 Perplexity(困惑度)、BLEU、Distinct-1/2(多样性度量),但这些都不足以真实反映对话“合理性”。因此,越来越多系统使用人类打分(如自然性、连贯性、信息充实度)或采用基于 GPT 的自动评估(LLM-as-a-judge)。
⁉️ Grid search、random search 和 bayesian optimization 的区别?
Grid search、random search 和 bayesian optimization 的区别?
Grid Search 是最直观也最暴力的搜索方式:对每个超参数设定离散的候选值,然后在其笛卡尔积上进行穷举搜索。虽然简单易实现,但它的计算成本极高,尤其在高维空间中容易出现维度灾难(curse of dimensionality),而且它会浪费大量资源在不重要的超参数组合上。
相比之下,Random Search 不再对每一个超参数组合进行遍历,而是随机采样参数组合。这种方式虽然在形式上看似“不严谨”,但根据 Bergstra 等人在 2012 年的研究表明,对于多数实际任务,Random Search 往往能在相同计算预算下找到更优的解,因为它增加了在重要超参数维度上采样的多样性。
而真正具有“智能”的是 Bayesian Optimization(贝叶斯优化)。它将超参数优化视为一个黑箱函数最优化问题,设目标函数为 f(x),其中 x 是超参数组合。Bayesian Optimization 会构建一个代理模型(通常是 Gaussian Process,高斯过程)来估计 f(x) 的分布,然后通过采集函数(Acquisition Function)(如 Expected Improvement 或 Upper Confidence Bound)来选择下一个最值得评估的点,从而在探索(exploration)与利用(exploitation)之间取得平衡。它的优势是能在较少的迭代次数下快速找到接近最优的超参数组合,尤其适用于评估代价高昂的 LLM 微调任务。但劣势也存在,比如难以扩展到超过 20 个超参数的高维空间,或者在存在离散型/条件型超参结构(如 Transformer 层数和激活函数交叉耦合)时建模困难。
总之,在选择超参数优化方法时,Grid Search 适合低维、小搜索空间且资源充足的场景,Random Search 更适合中等维度、快速试错的实验,而 Bayesian Optimization 适合资源有限但评估代价昂贵、目标是寻找最优配置的复杂模型调优场景。
⁉️ 多目标超参优化如何权衡(比如准确率 vs. 推理时间)?
多目标超参优化如何权衡(比如准确率 vs. 推理时间)?
在大型语言模型(LLM)工程实践中,多目标超参数优化(Multi-objective Hyperparameter Optimization)是一个非常核心但又常被忽视的难题。它的目标不仅仅是最大化模型性能(如准确率 accuracy、F1-score、BLEU 等),还常常需要同时最小化计算资源消耗(如推理时间 inference latency、显存 memory footprint 或 FLOPs)。这种优化问题不再是一个单一目标的最优化,而是涉及多个互相冲突的目标函数,通常用数学形式表示为:
$$ \min_{\theta \in \Theta} \left[ -\text{Accuracy}(\theta), \ \text{Latency}(\theta) \right] $$
其中 \theta 表示超参数向量(如学习率、batch size、模型深度等),\Theta 是超参数空间。注意这里的准确率前加了负号,是因为我们希望最大化准确率,同时最小化延迟。这种形式会构成一个典型的 Pareto Optimization Problem,即不存在一个超参数组合可以在所有目标上都最优,我们只能找到一组 Pareto Optimal 的解集:每一个都代表了某种 trade-off,例如牺牲少许性能以换取显著推理加速。
在实际应用中,可以使用 Bayesian Optimization(贝叶斯优化) 扩展至多目标场景,例如通过 Expected Hypervolume Improvement (EHVI) 来搜索最大化整个 Pareto 曲线下方面积的超参配置。也可以用 基于演化算法的搜索(如 NSGA-II),逐步逼近 Pareto 前沿。此外,在工业部署中,很多时候我们并不直接优化某个指标,而是引入一个 目标加权函数:
$$ \mathcal{L}_{obj} = \lambda_1 \cdot (1 - \text{Accuracy}) + \lambda_2 \cdot \text{Latency} $$
其中 \lambda_1 和 \lambda_2 是人为设定的权重系数,用于表达性能与资源之间的相对重要性。不过,这种做法可能掩盖某些细节,不如 Pareto-based 方法解释性强。
工程实现上,像 Optuna、Ray Tune 都支持多目标优化接口,可以通过设定 direction=[“maximize”, “minimize”] 等参数启用,并用可视化方式(如 Plotly 或 Hypervolume Plot)展示 Pareto 前沿结果,供开发者在产品上线前选择最合适的方案。
⁉️ 什么是消融实验(Ablation Study)?如何设计?
什么是消融实验(Ablation Study)?如何设计?
在大语言模型(LLM)工程实践中,消融实验(Ablation Study) 是一种用于分析模型各组成部分对整体性能贡献的重要方法。其核心思想是在保持其他变量不变的前提下,有系统地移除或修改模型结构中的某个组件、输入特征、训练策略或超参数配置,以观察性能变化,从而判断该部分的实际效用。
举个例子,在一个包含多模块的 Transformer-based 模型中(如加入了额外的知识检索模块、结构化输入提示 Prompt Tuning 等),我们可以设计如下消融方式:
- 移除知识检索模块,观察模型是否仍能保持相似准确率(Accuracy)或语言理解能力(measured via F1, EM, etc);
- 将 Prompt 换为随机噪声或空白模板,分析输出是否出现显著退化;
- 把 Adapter 层设为恒等映射,评估其是否真的在 Fine-tuning 中起到“高效调参”的作用。
消融实验的设计需满足 可比性(comparability)与可解释性(interpretability) 两个基本原则。为确保结果有效,所有实验必须控制除被消融项外的所有变量(如随机种子、优化器参数、训练数据划分等)。因此,一般推荐使用相同的初始化、固定的 random_seed,并尽可能使用重复实验(例如运行3-5次取均值与标准差)以减小噪声影响。
数学上,假设模型整体结构为一个函数:
$$ f(x; \theta) = f_1(x; \theta_1) + f_2(x; \theta_2) + \dots + f_n(x; \theta_n) $$
我们在消融某个模块 f_k 时,将其设置为零或替代为简化版本 f_k’(x),并定义性能损失为:
$$ \Delta_k = \text{Metric}(f(x)) - \text{Metric}(f_{-k}(x)) $$
其中 f_{-k}(x) 表示去除或修改 f_k 后的模型输出。若 \Delta_k 很大,说明该模块对性能至关重要;反之则可考虑简化或优化。
⁉️ 什么是A/B Testing?
什么是A/B Testing?
A/B Testing(又称为“对照实验”) 在大型语言模型(LLM)部署阶段是评估不同模型版本(或配置)对实际用户效果差异的核心实验方法。其基本思想是将用户随机分配到两个组:A组使用现有的baseline模型(如当前线上版本),B组使用新模型(如fine-tuned模型或修改后的Prompt策略)。通过对两组用户在核心指标(如点击率CTR、用户满意度、人机对话评分、转化率Conversion Rate等)上的表现进行统计显著性检验(如t检验或Mann–Whitney U检验),判断新版本是否具备上线价值。
在设计A/B测试时,关键包括以下几个方面:1)指标选择(Metric Selection):需要区分主指标(Primary Metric)和次指标(Secondary Metric),前者用于判断是否上线,后者用于辅助解释。例如,在对话系统中,主指标可能是人工评分的语言流畅性,次指标可能包括Token重复率或回复延迟。2)分流策略(Traffic Allocation):在初期一般采用10%:90%的冷启动比例(new:model = 10:90),当观察到较大改进再逐步扩大流量。3)统计功效分析(Power Analysis):通过预估效果大小(effect size)、方差和样本数,计算达到p值<0.05所需的最小样本量。4)避免数据污染(Data Leakage):确保单个用户在一次实验中只暴露于一个实验组,避免跨组泄漏影响对比结果。5)实验维度控制(Covariate Balance):比如控制用户设备、地理位置、历史行为分布一致,避免非模型差异引入噪音。一个简化的效果检测可以通过如下统计公式完成差异显著性检验:
$$ Z = \frac{ \bar{X}_B - \bar{X}_A }{ \sqrt{ \frac{\sigma_A^2}{n_A} + \frac{\sigma_B^2}{n_B} } } $$
其中 \bar{X}_A, \bar{X}_B 是两组样本均值,\sigma^2 是样本方差,n 是样本数量。Z值用于在正态分布下计算p-value,决定是否拒绝原假设(即两组无显著差异)。
Encoder-Only #
⁉️ Encoder-Only 在架构上和 transformer 有什么区别?
Encoder-Only 在架构上和 transformer 有什么区别?
Encoder-Only 架构只保留了 Transformer 的 Encoder 部分,完全去掉了 Decoder,所以它 只能用于特征提取或上下文建模(Representation Learning),而不是生成任务(Generation Tasks)。它的训练目标通常是掩码语言模型(Masked Language Modeling, MLM),而不是自回归语言模型(Autoregressive Language Modeling, AR)。换句话说,Encoder-Only模型的输入和输出都是“同时存在的完整句子”,模型学习的是如何理解和表征输入,而不是如何生成新的输出。
和完整的Transformer结构相比,缺少了解码器的部分,因此结构上更简单,适用的任务也偏向于分类(Classification)、特征抽取(Feature Extraction)、检索(Retrieval)等理解类任务(Understanding Tasks),而非文本生成(Text Generation)。
⁉️ BERT 的预训练目标有哪些?什么是 MLM 和 NSP?具体如何实现?
BERT 的预训练目标有哪些?什么是 MLM 和 NSP?具体如何实现?
BERT(Bidirectional Encoder Representations from Transformers)的预训练目标主要包括 Masked Language Modeling(MLM) 和 Next Sentence Prediction(NSP)。
① Masked Language Modeling (MLM)
Masked Language Modeling 是 BERT 预训练的核心目标,目的是让模型通过理解上下文,预测被遮盖(Masked)的单词。相比 GPT 的自回归预测,MLM 允许模型在训练时同时观察整个输入句子的左右两侧信息,是一种双向语言建模(Bidirectional Language Modeling)。
在 MLM 任务 中,BERT 随机遮盖(mask) 输入文本中的部分词汇(通常为 15%),并通过 Transformer Encoder 预测这些被遮盖的词。具体实现时,80% 的被遮盖词替换为
[MASK],10% 保持不变,另 10% 替换为随机词,以增强模型的泛化能力。模型接收完整的句子(包括[MASK])作为输入,目标是在输出端预测这些被遮盖位置的原始 token。损失函数 通常使用 Cross-Entropy Loss,只对被 mask 的位置计算损失:
$$ L = - \sum_{i \in \text{Mask}} \log P_\theta (x_i | X_{\setminus i}) $$
② Next Sentence Prediction (NSP)
NSP 任务 旨在学习句子级别的关系,BERT 通过给定的两个句子 判断它们是否为原始文本中的连续句(IsNext)或随机拼接的无关句(NotNext)。输入格式为:
[CLS] Sentence A [SEP] Sentence B [SEP]训练时,BERT 以 50% 的概率选择相邻句子作为正样本,另 50% 选择无关句子作为负样本,并通过 二分类损失函数(Binary Cross-Entropy Loss) 进行优化。最后的输出
[CLS]位置的向量经过一个二分类器(通常是一个简单的全连接层+Softmax),预测 Sentence B 是否为 Sentence A 的下一个句子。损失函数 通常使用 二分类交叉熵损失(Binary Cross-Entropy):
$$ L = - [ y \log p + (1 - y) \log (1 - p) ] $$
MLM 使 BERT 能够学习上下文双向依赖关系,而 NSP 则有助于建模句子间的全局关系,这两个目标共同提升了 BERT 在 自然语言理解(Natural Language Understanding, NLU) 任务中的表现。BERT 原版是通过将这两个目标一起训练的,最终损失是:
$$ L_{\text{Total}} = L_{\text{MLM}} + L_{\text{NSP}} $$
Note: BERT 的 Masked Language Modeling 本质上就是在做“完形填空”:预训练时,先将一部分词随机地盖住,经过模型的拟合,如果能够很好地预测那些盖住的词,模型就学到了文本的内在逻辑。这部分的主要作用是让模型 学到词汇和语法规则,提高语言理解能力。
除了“完形填空”,BERT还需要做 Next Sentence Prediction 任务:预测句子B是否为句子A的下一句。Next Sentence Prediction有点像英语考试中的“段落排序”题,只不过简化到只考虑两句话。如果模型无法正确地基于当前句子预测 Next Sentence,而是生硬地把两个不相关的句子拼到一起,两个句子在语义上是毫不相关的,说明模型没有读懂文本背后的意思。 这部分的主要作用是让模型 学习句子级别的语义关系。
⁉️ 为什么 BERT 的输入需要添加 [CLS] 和 [SEP] 特殊标记?
为什么 BERT 的输入需要添加 [CLS] 和 [SEP] 特殊标记?
BERT 的输入需要添加 [CLS] 和 [SEP] 特殊标记,主要是用来表示 Next Sentence Prediction(NSP) 任务的输入格式,并增强模型的表示能力。例如:
[CLS] 句子A [SEP] 句子B [SEP]
[CLS](Classification Token):BERT 在输入序列的开头始终添加[CLS],它的最终隐藏状态(Hidden State)可以作为整个序列的表示,特别 适用于分类任务(如情感分析、自然语言推理 NLI)。即使不是分类任务,BERT 仍然会计算[CLS]的表示,因此它始终是输入的一部分。[SEP](Separator Token):BERT 采用双向 Transformer,因此需要区分单句和双句任务。在单句任务(如情感分析)中,输入序列结尾会加[SEP],而在双句任务(如问答 QA 或文本匹配),[SEP]用于分隔两个句子,帮助 BERT 处理跨句子的关系建模。
在 微调阶段(Fine-Tuning),不同任务对 [CLS] 和 [SEP] 的使用方式略有不同。例如:
- 文本分类(如情感分析):
[CLS]的最终表示输入到 Softmax 层进行分类。 - 问答(QA):
[SEP]作为问题和段落的分隔符,BERT 需要预测答案的起始和结束位置。 - 命名实体识别(NER):
[CLS]不是必须的,而是依赖 Token 级别的输出。
Note: 对比 BERT 的
[CLS]向量和平均池化获取句子表示的优缺点?
[CLS]向量的优缺点:
- 简洁性:只需要一个向量(即
[CLS]向量)来表示整个句子的语义,非常适用于分类任务,尤其是在输入句子较短时。- 端到端优化:由于 BERT 在预训练时优化了
[CLS]向量,使其能够有效地聚合句子的语义信息,且通常与下游任务紧密相关。- 可能信息丢失:
[CLS]向量是通过加权和整个输入的 token 嵌入得到的,可能导致一些细节信息丢失,特别是当句子较长或复杂时。- 平均池化(Mean Pooling)的优缺点:
- 信息保留:平均池化将所有 token 的表示进行平均,从而保留了句子中各个部分的信息,相比于
[CLS]向量,它能保留更多的语义信息。- 缺乏上下文关注:平均池化忽略了 token 之间的复杂依赖关系,简单的加权平均可能无法捕捉到句子中不同部分的关联性,尤其是在多义词或句子结构复杂时。
- 计算开销:对于长句子,平均池化需要计算所有 token 的平均值,可能增加计算开销,尤其在大规模数据集上。
⁉️ 为什么BERT使用双向自注意力机制?这种设计如何影响下游任务?
为什么BERT使用双向自注意力机制?这种设计如何影响下游任务?
BERT之所以采用 双向自注意力机制(Bidirectional Self-Attention),核心原因在于它 希望在预训练阶段同时捕捉上下文的完整信息(full context information)。在每一个Transformer层中,模型可以在同一时间考虑输入序列中 当前位置(current position)的左边和右边的所有词汇信息。这种设计通过 Masked Language Model(MLM) 的训练目标实现:随机遮挡输入中的一部分token,模型需要根据完整的上下文(包括被遮挡位置的左右两侧)去预测被遮挡的token,从而学到双向的信息整合能力。
这种机制对于下游任务的影响非常显著:
- 语义理解增强(Enhanced Semantic Understanding):双向结构让模型能更准确捕捉句子中词与词之间的相互关系,尤其在句子语序复杂或有歧义时,能够有效消除偏见并提升上下文理解能力。例如,在情感分析(Sentiment Analysis)任务中,句尾的否定词“but”对整句话的情感倾向至关重要,BERT的双向机制能捕捉到这种句子尾部的反转信息。
- 特征表达更加丰富(Richer Feature Representation):相较于单向模型,双向自注意力产生的上下文特征向量(contextual embeddings)包含了全局信息,使得微调(Fine-tuning)在分类、序列标注等任务时,模型更容易收敛且表现更优。
- 下游任务适配性更广(Better Downstream Adaptability):许多自然语言处理任务,比如问答系统(Question Answering)、文本蕴含识别(Natural Language Inference, NLI) 等,需要模型理解整段文本的完整含义,而不仅仅是基于局部信息的预测。BERT的双向特性正好契合这类需求,能在不修改架构的前提下,通过不同的微调头(Task-specific Heads)适配各种任务。
⁉️ BERT 微调的细节?
BERT 微调的细节?
BERT(Bidirectional Encoder Representations from Transformers)微调(Fine-tuning)通常是在预训练(Pre-training)后的基础上,将整个 BERT 模型与特定任务的分类头(Task-specific Head)一起训练,使其适应 下游任务(Downstream Task)。
在微调过程中,输入文本经过分词(Tokenization)后,会被转换为对应的词嵌入(Token Embeddings)、位置嵌入(Position Embeddings)和分段嵌入(Segment Embeddings),然后输入 BERT 的 Transformer 层。模型通过多层 双向自注意力(Bidirectional Self-Attention)计算上下文信息,并在最终的 [CLS](分类标记)或其他适当的标记上添加任务特定的层,如全连接层(Fully Connected Layer)或 CRF(Conditional Random Field),然后使用任务相关的损失函数(Loss Function)进行优化,如交叉熵损失(Cross-Entropy Loss)用于分类任务。
⁉️ RoBERTa 的技术细节?它相比 BERT 做了哪些改进(如动态掩码、移除 NSP 任务)?
RoBERTa 的技术细节?它相比 BERT 做了哪些改进(如动态掩码、移除 NSP 任务)?
RoBERTa(Robustly Optimized BERT Pretraining Approach) 在 BERT(Bidirectional Encoder Representations from Transformers)的基础上进行了多项优化,以提高模型的性能和泛化能力。
首先,RoBERTa 采用了 动态掩码(Dynamic Masking) 机制,即在每个训练 epoch 重新随机生成 Masked Language Model(MLM)掩码,而 BERT 仅在数据预处理阶段静态确定掩码。这种动态策略增加了模型学习的多样性,提高了其对不同掩码模式的适应能力。
Note:训练时使用的动态掩码(Dynamic Masking)与静态掩码有何区别?
BERT 原始论文使用的是 静态掩码,即在数据预处理阶段,对训练数据进行一次性 Mask 处理,并将其存储起来。在训练过程中,每次使用该数据时,Mask 位置都是固定的。假设文本是:
“The quick brown fox jumps over the lazy dog.”在静态掩码中,预处理时就选好了
fox和lazy被掩码,模型每次都看到:“The quick brown [MASK] jumps over the [MASK] dog.”RoBERTa 在 BERT 的基础上采用了 动态掩码,即在每次数据加载时,都会 随机重新选择 Mask 位置,确保同一输入文本在不同训练轮次中 Mask 位置不同。这提高了数据多样性,使得模型能够学习更丰富的上下文表示,而 不会过度拟合某些固定的 Mask 位置。每次训练时,模型可能看到不同的掩码版本,比如:
• 第一次训练:The quick brown fox jumps over the [MASK] dog. • 第二次训练:The quick [MASK] brown fox jumps over the lazy dog. • 第三次训练:The quick brown [MASK] jumps over the lazy dog.
其次,RoBERTa 移除了 NSP(Next Sentence Prediction)任务,BERT 在训练时采用了 NSP 任务以增强模型对句子关系的理解,但研究发现 NSP 任务并未显著提升下游任务的表现,甚至可能影响模型的学习效率。因此,RoBERTa 采用了更大规模的 连续文本(Longer Sequences of Text) 进行预训练,而不再强制区分句子关系。最后,RoBERTa 通过 增加 batch size 和训练数据量,并 采用更长的训练时间,进一步优化了 BERT 预训练过程,使模型能够更充分地学习语言特征。
⁉️ DeBERTa 的“解耦注意力”机制(Disentangled Attention)如何分离内容和位置信息?
DeBERTa 的“解耦注意力”机制(Disentangled Attention)如何分离内容和位置信息?
DeBERTa(Decoding-enhanced BERT with Disentangled Attention) 相较于 BERT 主要在 解耦注意力(Disentangled Attention) 和 相对位置编码(Relative Position Encoding) 方面进行了改进,以提升模型的语言理解能力。BERT 采用标准的 Transformer 注意力机制(Self-Attention),其中查询(Query)、键(Key)、值(Value)向量均是基于相同的嵌入(Embedding),这意味着 内容信息(Content Information) 和 位置信息(Positional Information) 混合在一起,限制了模型对句子结构的建模能力。而 DeBERTa 通过解耦注意力机制,对内容和位置信息分别编码,使得模型在计算注意力时能够更精确地理解不同词语之间的相对关系。
Note:Disentangled Attention 的设计,本质上是针对 BERT 系列所用的 absolute position embedding(绝对位置编码)问题提出的。 传统 BERT 的输入结构是: $$ h_i = x_i + p_i $$
注意力的打分计算是:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V $$
DeBERTa 将词的内容(content) 和 位置(position) 分开建模,注意力打分的计算方式改为:
$$ \alpha_{i,j} = \frac{(q_i^c)^T k_j^c + (q_i^c)^T r_{i-j}^p + (q_i^p)^T k_j^c}{\sqrt{d}} $$
具体来说,DeBERTa 在计算注意力权重时,不是直接基于词向量(Token Embedding),而是 分别计算基于内容(Content-based Attention)和基于位置(Position-based Attention)的注意力得分,然后再将两者加权合并。这种方式使得 DeBERTa 能够在更长的依赖关系建模上表现更好。此外,DeBERTa 还采用了 增强的相对位置编码(Enhanced Relative Position Encoding),相比 BERT 的绝对位置编码(Absolute Positional Encoding),能够更自然地处理长文本结构。
⁉️ ALBERT 如何通过参数共享降低模型参数量?
ALBERT 如何通过参数共享降低模型参数量?
ALBERT(A Lite BERT)是对 BERT 模型的轻量化改进,旨在通过降低模型参数量而不显著影响模型性能。其主要技术细节涉及两项关键的优化策略:参数分解嵌入(Factorized Embedding) 和 跨层参数共享(Cross-Layer Parameter Sharing)。
- 参数分解嵌入(Factorized Embedding):BERT 使用了一个巨大的词嵌入矩阵(embedding matrix),其大小通常是词汇表的大小与隐藏层维度(hidden size)的乘积。而 ALBERT 采用了参数分解方法,将词嵌入矩阵分解为两个低维矩阵,分别是一个较小的 词汇嵌入矩阵(Word Embedding Matrix) 和一个较小的 隐藏层嵌入矩阵(Hidden Layer Embedding Matrix)。具体来说,词嵌入矩阵被分解为两个矩阵,一个低维的嵌入矩阵和一个较小的输出矩阵,这样就显著减少了参数数量。例如,假设词嵌入矩阵的维度为 V x H(V 是词汇表大小,H 是隐藏层大小),通过分解成两个矩阵 V x E 和 E x H(E 为较小的维度),可以大幅度减少计算复杂度和存储需求。
- 跨层参数共享(Cross-Layer Parameter Sharing):在标准的 BERT 中,每一层 Transformer 都有一组独立的参数,而 ALBERT 通过跨层共享参数,减少了每一层的独立参数。具体来说,ALBERT 将模型中多个 Transformer 层 的参数进行共享,所有层都使用相同的权重。这样,尽管 ALBERT 保留了更多的层数(如 BERT 的 12 层改为 12 层的 ALBERT),但通过共享权重,整体的参数数量大幅度减少。参数共享的核心思想是:每一层 Transformer 的前向传播和反向传播使用相同的参数,从而减少了每层的权重数量,降低了内存消耗。
Note:ALBERT提出的方法就是跨层参数共享,核心思想:所有Transformer层的权重矩阵都可以复用同一组参数,居图来说 Attention 模块参数
$$ W_Q, W_K, W_V, W_O$$ 在模块内部共享。
FeedForward模块的参数
$$W_1, W_2$$
在模块内部共享。因为作者认为原版的 BERT中 每层都独立训练,虽然灵活,但造成了巨大的参数冗余,很多层其实在做非常相似的变换,浪费内存和计算资源。
Encoder-Decoder #
⁉️ Encoder-Decoder架构的核心设计目标是什么?适用于哪些任务场景?
Encoder-Decoder架构的核心设计目标是什么?适用于哪些任务场景?
Encoder-Decoder架构的 设计初衷 是解决 输入输出序列长度不对称、语义空间跨域映射的问题,确保模型能够有效压缩输入特征并有条件地生成目标序列,广泛应用于机器翻译、文本摘要、图像描述生成、跨模态问答等场景,尤其适合输入与输出的语义空间或结构不同的任务。
Encoder-Decoder模型同时具备了 理解(Encoder)和生成(Decoder) 的能力,因此它能够处理复杂的任务,如机器翻译、文本摘要、图像描述等。这类模型既能够通过 Encoder 理解输入,又能通过 Decoder 生成输出。Encoder–Decoder模型的好处有:
- 生成能力:Encoder–Decoder 架构能够生成任意长度的输出序列,而不是像Encoder-only模型那样只能生成固定长度的表示。它允许通过解码器(Decoder)逐步生成目标序列,非常适合像机器翻译和文本摘要等生成任务。
- 灵活的输入和输出:Encoder-only 模型和 Decoder-only 模型通常输入和输出的长度是固定的,而 Encoder–Decoder 模型能够灵活地处理不同长度的输入和输出。Decoder 可以根据输入序列生成任意长度的目标序列,从而适应更复杂的任务。
- 跨任务的预训练能力:Encoder–Decoder模型可以通过多任务学习提升模型的泛化能力。比如,T5模型通过将不同任务(如文本分类、文本生成等)统一为一个多任务预训练框架,从而增强了模型对不同任务的处理能力。
⁉️ T5 如何统一不同 NLP 任务的格式?其预训练任务(如 Span Corruption)具体如何实现?
T5 如何统一不同 NLP 任务的格式?其预训练任务(如 Span Corruption)具体如何实现?
T5(Text-to-Text Transfer Transformer)通过将所有 NLP 任务(如文本分类、机器翻译、问答、摘要生成等)统一转换为文本到文本(Text-to-Text)的格式,从而实现了一个通用的 NLP 框架。具体而言,无论是输入句子的分类任务还是填空任务,T5 都会将输入转换为文本序列,并要求模型生成相应的文本输出。例如,情感分析任务的输入可以是 "sentiment: I love this movie",输出则是 "positive",而机器翻译任务的输入可能是 "translate English to French: How are you?",输出为 "Comment ça va?"。
Note:Span Corruption(Span-Masked Language Modeling, SMLM)与 Masked Language Modeling(MLM)的核心区别在于 Mask 的方式和学习目标的不同。
- MLM(Masked Language Modeling,BERT 采用):
- MLM 主要是随机选择 单个 token 进行遮蔽,然后让模型预测被遮蔽的 token。例如:
Input: "I love [MASK] learning" Target: "deep"- 由于每次仅遮蔽少量 token,BERT 可能 无法学习到更长跨度的依赖关系,特别是对完整的子句或短语的理解较弱。
- SMLM(Span-Masked Language Modeling,T5 采用):
- SMLM 采用 Span Corruption,即 一次遮蔽连续的多个 token,并用特殊标记
<extra_id_0>来表示被遮蔽部分。例如:Input: "I <extra_id_0> deep <extra_id_1>." Target: "<extra_id_0> love <extra_id_1> learning"- 能够更好地 学习长距离的依赖关系,适用于生成式任务(如摘要、翻译)。训练难度更高。
T5 采用的主要预训练任务是 Span Corruption(Span-Masked Language Modeling, SMLM),这是一种变体的掩码语言建模(Masked Language Modeling, MLM)。具体来说,该任务会在输入文本中随机选择若干个 span(即连续的子序列),用特殊的 <extra_id_X> 令牌替换它们,并要求模型预测被遮蔽的内容。例如,原始文本 "The quick brown fox jumps over the lazy dog" 可能会被转换为 "The <extra_id_0> fox jumps over the <extra_id_1> dog",而模型需要输出 "quick brown" <extra_id_0> 和 “lazy” <extra_id_1>。这种方式比 BERT 的单词级别掩码更灵活,有助于学习更丰富的上下文信息,从而提升生成任务的能力。
Note:在 Span Corruption 预训练(Span Corruption Pretraining)中,被遮蔽的文本片段(Masked Span)的长度通常遵循 Zipf 分布(Zipf’s Law),即较短的片段更常见,而较长的片段较少,以模拟自然语言中的信息分布。具体而言,像 T5 这样的模型使用 几何分布(Geometric Distribution) 来采样 span 长度,以确保既有短范围的遮蔽,也有跨多个 token 的长范围遮蔽。
不同的遮蔽长度会影响模型的学习能力:较短的 span(例如 1-3 个 token)有助于模型学习局部语义填充能力(Local Context Understanding),而较长的 span(如 8-10 个 token 甚至更长)可以增强模型的全局推理能力(Global Reasoning)和段落级理解能力(Document-Level Comprehension)。如果 span 过短,模型可能更倾向于基于表面模式(Surface Patterns)预测,而非真正理解上下文;如果 span 过长,则可能导致学习任务过于困难,使得模型难以有效收敛。
| 任务类型 | 示例输入 | 示例输出 |
|---|---|---|
| 文本分类(Text Classification) | sst2 sentence: This movie is fantastic! | positive |
| 文本生成(Text Generation) | summarize: The article talks about … | The main idea is… |
| 机器翻译(Machine Translation) | translate English to German: How are you? | Wie geht es dir? |
| 文本补全(Text Completion) | fill_mask: I love to [MASK] pizza. | eat |
| 问答(Question Answering) | question: Who wrote Hamlet? context: Shakespeare wrote… | Shakespeare |
⁉️ 如何将预训练的 Encoder-Decoder 模型(如 T5)适配到具体下游任务?
如何将预训练的 Encoder-Decoder 模型(如 T5)适配到具体下游任务?
T5(Text-to-Text Transfer Transformer)模型与BERT相似,也需要通过在特定任务的数据上进行微调(fine-tuning)来完成下游任务。与BERT的微调有所不同,T5的主要特点包括:
- 任务描述(Task Prefix):T5 的输入不仅包含原始文本,还需要附加一个任务描述。例如,在文本摘要(Text Summarization)任务中,输入可以是 “summarize: 原文内容”,而在问答(Question Answering)任务中,输入可以是 “question: 问题内容 context: 相关文本”。这种设计使 T5 能够以统一的 文本到文本(Text-to-Text) 形式处理不同任务。
- 端到端序列生成(Sequence-to-Sequence Generation):与 BERT 仅能进行分类或填空任务不同,T5 依赖其 Transformer 解码器(Transformer Decoder) 来生成完整的输出序列,使其适用于文本生成任务,如自动摘要、数据到文本转换(Data-to-Text Generation)等。
- 无需额外层(No Task-Specific Layers):在 BERT 微调时,通常需要在其顶层添加特定的任务头(Task-Specific Head),如分类层(Classification Layer)或 CRF(Conditional Random Field)层,而 T5 直接将任务作为输入提示(Prompt),并使用相同的模型结构进行训练,无需修改额外的网络层。
⁉️ 什么是BART?BART 的预训练任务与 T5 有何异同?
什么是BART?BART 的预训练任务(如 Text Infilling、Sentence Permutation)与 T5 的 Span Corruption 有何异同?
BART(Bidirectional and Auto-Regressive Transformers) 是一种结合了 BERT(Bidirectional Encoder Representations from Transformers)和 GPT(Generative Pretrained Transformer)优点的生成模型。BART 在预训练过程中采用了 自编码器(Autoencoder) 结构,其编码器部分像 BERT 一样使用双向编码,能够捕捉上下文信息,而解码器则是像 GPT 一样用于生成任务,通过自回归方式生成文本。
| 任务类型 | 具体示例 | 输入 ➡️ 输出特征说明 |
|---|---|---|
| 机器翻译(Machine Translation) | 英语 ➡️ 法语 | 输入输出语言不同,长度不固定,语义需对应 |
| 文本摘要(Text Summarization) | 新闻文章 ➡️ 简短摘要 | 输入长文本,输出短摘要,结构压缩 |
| 图像描述生成(Image Captioning) | 图片特征向量 ➡️ 自然语言描述 | 输入非语言特征,输出自然语言,跨模态转换 |
| 文本生成(Text Generation) | Prompt ➡️ 自动补全文本 | 输入提示短语,输出完整文本,顺序自回归建模 |
| 语音转文本(Speech-to-Text) | 语音信号(波形或特征)➡️ 文字 | 输入连续音频流,输出离散文本序列,输入输出格式完全不同 |
| 多模态问答(VQA / Multimodal QA) | 图片 + 问题文本 ➡️ 答案文本 | 输入多模态,输出单模态文本,结构不对称 |
BART 的预训练任务包括 Text Infilling 和 Sentence Permutation:
- Text Infilling:在这一任务中,模型需要从一段被掩盖部分的文本中恢复出被移除的词或词组。具体来说,给定一个输入文本,部分单词或短语被替换为掩码(mask),然后模型的任务是预测这些被掩盖的内容。这一任务类似于 BERT 的 Masked Language Model(MLM),但区别在于,BART 不仅仅是根据上下文来填充单一词汇,它的目标是生成整个缺失的文本片段。
原始文本:“The quick brown fox jumps over the lazy dog in the park.” 掩盖后的文本:“The quick [MASK] jumps over the lazy dog in the park.”
Note:在 MLM 中,模型的目标是预测被随机掩盖的单个词(或子词)。虽然 Text Infilling 看起来类似于 MLM,但 BART 的 Text Infilling 中,掩盖的部分不仅限于单个词,而是可能是一个较大的片段或短语。通常,模型会随机选择一个较长的文本片段(如一个短语或句子的一部分)并用一个掩码标记替换,然后模型需要预测整个被掩盖的文本片段。
总结,MLM遮一个词,Text Infilling 遮一个片段,Span Corruption 遮多个片段。
- Sentence Permutation:在这一任务中,输入文本的句子顺序被打乱,模型的任务是根据上下文恢复正确的句子顺序。这个任务是为了帮助模型学习长文本的结构和上下文关系,使其能够生成连贯且符合语法规则的文本。它与 T5 中的 Span Corruption 有一定的相似性,因为两者都涉及对文本进行扰动,并要求模型根据扰动后的文本恢复原始文本。
原始文本: “The dog chased the ball. It was a sunny day.” 打乱顺序后的文本: “It was a sunny day. The dog chased the ball.”
Decoder-Only #
⁉️ Decoder-only 模型与 Encoder-Decoder 模型的核心区别是什么?
Decoder-only 模型与 Encoder-Decoder 模型的核心区别是什么?
Decoder-only(如GPT)仅保留解码器,通过自回归生成(逐词预测)完成任务。移除原始Transformer的编码器和交叉注意力层,保留掩码自注意力(Masked Self-Attention)与前馈网络(FFN)。输入处理时,文本序列添加特殊标记 <bos>(序列开始)和 <eos>(序列结束),目标序列为输入右移一位。适用任务主要为生成类任务(文本续写、对话、代码生成)。Encoder-Decoder(如原始Transformer、T5)分离编码器(理解输入)与解码器(生成输出),通过交叉注意力传递信息。适用任务主要为需严格分离输入理解与输出生成的任务(翻译、摘要、问答)。
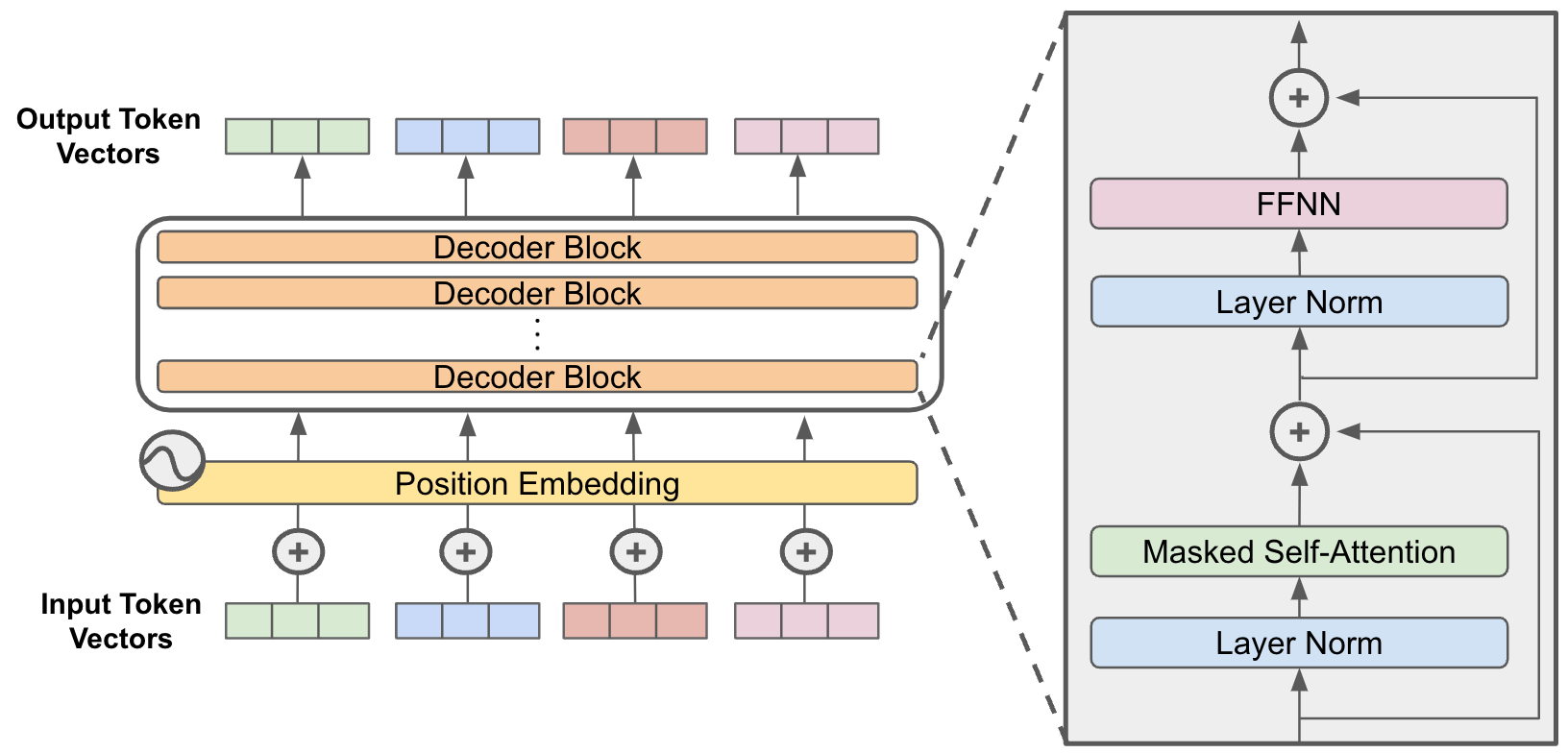
Decoder-only模型通过 上下文学习(In-Context Learning) 将任务隐式编码到输入中(如添加“Translate English to French:”前缀),利用生成能力模拟翻译,完成和 Encoder-Decoder 一样的工作。但是 Encoder-Decoder在以下场景更具优势:
- 输入与输出解耦的复杂任务(如翻译):Encoder-Decoder 模型的编码器可先提取完整语义,解码器再逐词生成,避免生成过程中的语义偏差,准确性更高。而Decoder-only模型(如GPT-3)需通过Prompt(如“Translate English to French: …”)隐式对齐输入输出,易受提示词设计影响。
- 长文本处理效率:Encoder-Decoder:编码器一次性压缩输入为固定长度表示,解码生成时无需重复处理长输入(节省计算资源)。Decoder-only:生成每个词时需重新处理整个输入序列(如输入1000词的文档),导致计算复杂度高。
总结来说
- Decoder-only:适合开放域生成任务,依赖生成连贯性与上下文学习,但对输入-输出结构复杂的任务效率较低。
- Encoder-Decoder:在需严格分离理解与生成、处理长输入、多任务统一的场景中更优,尤其适合翻译、摘要等结构化任务。
- 类比:Decoder-only像“自由创作的作家”,Encoder-Decoder像“严谨的翻译官”——前者更灵活,后者更精准。
⁉️ Decoder-only 模型的预训练任务通常是什么?
Decoder-only 模型的预训练任务通常是什么?
- 自回归语言建模(Autoregressive Language Modeling):这个任务的目标是通过给定一部分文本(如前面的词或字符),预测接下来的单词或字符。例如,给定输入
“The cat sat on the”, 模型的任务是预测下一个单词是“mat”。这个过程是自回归的,因为每次生成新的词都会基于模型已经生成的文本。自回归语言建模任务常见于 GPT(Generative Pre-trained Transformer) 等模型。 - 文本填充任务(Cloze Task):在这个任务中,模型的目标是根据上下文填充文本中的空白部分。例如,给定句子
“The cat sat on the ____”, 模型需要预测空白处应该填入的词“mat”。这种填空任务常见于 BERT(Bidirectional Encoder Representations from Transformers) 的变体,如 Masked Language Modeling (MLM)。尽管 BERT 是基于 编码器(Encoder) 架构,但类似的目标也可以应用于 Decoder-only 架构,通过在训练时将部分词语随机遮蔽(mask)并让模型预测被遮蔽的部分。
⁉️ 为什么 Decoder-only 模型通常采用自回归生成方式?因果掩码的作用及其实现方法。
为什么 Decoder-only 模型通常采用自回归生成方式?因果掩码的作用及其实现方法。
Decoder-only 模型通常采用自回归(Autoregressive)生成方式,因为这种方式能够通过模型已经生成的输出逐步生成下一个 token,从而形成连贯的序列。自回归生成方式使得每个步骤的生成依赖于前一步的生成结果,这种特性非常适合文本生成任务,如 语言建模(Language Modeling) 和 对话生成(Dialogue Generation)。通过这种方式,模型能够以逐词的方式生成文本,在每个步骤中利用之前的上下文信息预测下一个 token。即最大化序列联合概率,损失函数为交叉熵(Cross-Entropy):
\[ \begin{equation} \mathcal{L} = -\sum_{t=1}^{T} \log P(w_t | w_{1:t-1 }) \end{equation} \]在 Decoder-only 模型中,因果掩码(Causal Mask) 的作用是确保模型在生成时 仅依赖于已生成的部分,而不会看到未来的信息。具体来说,在训练时,因果掩码会屏蔽未来 token 的信息,使得模型只能访问当前位置及其之前的 token,这样保证了每个时间步的预测仅受历史信息的影响,而无法窥视未来的输出。实现方法通常是在注意力机制(Attention Mechanism)中,通过对自注意力矩阵应用一个上三角矩阵的掩码,将未来的 token 阻止在计算中。例如,如果在生成第 4 个 token 时,模型不允许访问第 5、6 个 token,掩码就会在这些位置设置为负无穷,从而避免信息泄漏。
⁉️ 解释 Teacher Forcing 在 Decoder-only 模型训练中的作用及其潜在缺陷。
解释 Teacher Forcing 在 Decoder-only 模型训练中的作用及其潜在缺陷。
Teacher Forcing 是一种在训练序列生成模型时常用的技术,尤其是在 Decoder-only 模型(如 GPT 等自回归语言模型)的训练过程中。在 Teacher Forcing 中,模型在 每个时间步的输入不依赖于前一步的预测输出,而是直接使用真实的目标词(Ground Truth)作为输入。这意味着,在训练过程中,Decoder 在每个时间步都接收的是当前时间步的真实标签,而不是模型自己预测的输出。
这种方法的主要作用是加速模型训练,因为它 避免了模型在每次预测时犯错后导致的错误传播。在传统的训练过程中,模型每一次的预测都可能受到前一步错误的影响,这样会使得训练变得更加困难且收敛速度变慢。而 Teacher Forcing 确保每个时间步的输入都是正确的,从而减少了梯度计算中的误差积累,加速了训练过程。
然而,Teacher Forcing 也存在潜在缺陷,特别是在 推理阶段(Inference)。在训练阶段,模型总是看到真实的目标词作为输入,但在推理时,它必须依赖于自己之前的预测。Teacher Forcing 可能导致 模型在训练和推理时的分布不匹配(Exposure Bias),即训练时的“理想环境”与实际推理时的“真实环境”不一致。若在训练中模型从未经历过自己预测错误的情况,它可能在推理时无法有效地纠正错误,从而影响生成的质量,导致 生成质量下降 或 无法适应真实环境中的错误传播。
为了缓解这个问题,一些方法如 Scheduled Sampling 被提出,它 逐渐减少训练时的 Teacher Forcing 比例,让模型在训练阶段逐步适应自己的预测输出,从而提高模型在推理时的稳定性和表现。
⁉️ 什么是 In-Context Learning?Decoder-only 模型如何实现零样本(Zero-Shot)推理能力?
什么是 In-Context Learning?Decoder-only 模型如何实现零样本(Zero-Shot)推理能力?
上下文学习(In-Context Learning) 是指在推理过程中,模型通过理解并利用输入文本中的上下文信息来做出预测,而无需对任务进行额外的训练或微调(fine-tuning)。在这种方法中,模型通过直接接收任务的描述和示例输入-输出对,在推理时依赖这些信息来预测结果。与传统的基于训练的学习方式不同,上下文学习使得模型可以灵活应对新任务,而无需重新训练。
Decoder-only 模型(例如 GPT-3)通过将 任务的描述、示例以及相关输入文本提供给模型,使得模型能够在上下文中推理并生成响应。具体而言,GPT-3 和类似的 Transformer 模型基于自回归生成(autoregressive generation)机制,通过逐步生成下一个词,结合前文的上下文信息来进行推理。在这种机制下,模型无需显式的监督学习或微调,只要给定足够的上下文(例如任务描述和输入示例),它就能根据这些信息来做出预测。
- Few-shot 示例:
Q: Capital of France? A: Paris Q: Capital of Japan? A: Tokyo Q: Capital of Brazil? A:
- 模型通过前两例学习“Q-A”模式,生成“Brasília”。
- Zero-shot 指令:
Please answer the following question: What is the boiling point of water? Answer:
- 模型根据指令词“Please answer”生成“100°C (212°F) at sea level”。
Zero-Shot 推理的实现方式在于 训练过程中接触了多种任务(如文本生成、问答、翻译、摘要等),使得模型能够在面对新任务时,依靠其通用语言理解能力完成推理,而无需重新训练或微调(Fine-tuning)。例如,假设我们要求模型完成一个数学问题,尽管模型未曾专门针对该任务训练,但它能依赖于其对语言的广泛理解,推断出合理的解答。大规模的训练数据为模型提供了更广泛的背景知识,使其能够在推理时利用丰富的上下文信息。
举个例子,当我们给出一个从未见过的任务,比如 “翻译以下文本成法语:‘I have a dream’”,GPT-3 可以准确地根据其训练数据中的语言模式生成翻译:“J’ai un rêve”。这是因为在其训练数据中,它已经接触过大量的文本翻译任务,并学会了如何根据提示进行推理。
⁉️ 对比 Greedy Search 与 Beam Search 在 Decoder-only 模型中的优缺点。
对比 Greedy Search 与 Beam Search 在 Decoder-only 模型中的优缺点。
Greedy Search 是一种简单的解码策略,它在 每个时间步(Time Step)选择概率最大的词作为输出。具体来说,对于每个生成步骤,模型会选择当前概率分布中 最大概率的词(Maximum Probability Word) 作为下一步的输出,并且该词会作为输入传递到下一个时间步。Greedy Search 的优点是 计算效率高(High Computational Efficiency),因为它只进行单一的选择和计算。然而,它的缺点是 局部最优问题(Local Optima),即每次选择最有可能的词,而没有考虑未来可能的其他选择,因此它容易陷入次优解,导致生成的序列质量不高。
Note: Greedy Search 每一步选择概率最大的一个 token(贪婪策略)。Beam Search 保留 N 个最优的候选序列,步步扩展(每次都在上一步的所有路径扩展出V个可能,再从中挑Top N),最终选整体概率最大的句子。
与此不同,Beam Search 是一种更加复杂的解码方法,它通过在每个时间步保留 多个候选序列(Multiple Candidate Sequences) 来进行搜索。具体来说,Beam Search 会在每个步骤保留 k个最优候选(Top-k Candidates),而不是仅仅选择概率最大的一个词。通过这种方式,Beam Search 允许模型探索更多的可能性,从而提高生成质量。Beam Search 的优点是能够生成更具多样性的序列,通常能避免 Greedy Search 的局部最优问题,生成的结果更具 全局最优性(Global Optimality)。然而,它的缺点是 计算开销较大(Higher Computational Cost),因为需要维护多个候选序列,尤其在长文本生成时,这种计算开销可能会显著增加。
⁉️ Top-k 采样 和 Top-p(Nucleus)采样 的核心区别是什么?各适用于什么场景?
Top-k 采样 和 Top-p(Nucleus)采样 的核心区别是什么?各适用于什么场景?
Top-k 采样、Top-p 采样和 Greedy Search 和 Beam Search 一样都是解码策略(decoding strategies),它们的目标是生成高质量的文本。
Notes:
推荐策略 适用场景 策略说明 ✅ Greedy / Beam Search 确定性生成(如机器翻译) 每步选择概率最大的Token(Beam则保留多个路径) ✅ Top-K / Top-P + Temperature 开放性生成(如对话、写作、小说) 限制候选集合后,按概率重新抽样,支持温度调节控制随机性
Top-k 采样 是一种基于概率分布的截断方法,在每次生成一个单词时,只从概率分布前 k 个最可能的词中选择一个进行生成,其他词的概率被截断为零。这种方法通过限制候选词的数量来控制生成文本的多样性,从而避免生成非常低概率的、不太合理的词汇。其公式可以表示为:
\[ P(w_i) = \begin{cases} P(w_i), & \text{if } w_i \in \text{Top-}k \\ 0, & \text{otherwise} \end{cases} \]Top-k 表示从前 k 个概率最高的词中进行选择。Top-k 采样适用于生成任务中需要平衡多样性和合理性,如 对话生成(Dialogue Generation) 和 文本创作(Text Generation) 等场景。
Top-p 采样(Nucleus Sampling) 则是一种基于 累积概率的采样方法。在每个时间步,Top-p 会选择一个最小的词集合,使得这些词的累积概率大于或等于 p。与 Top-k 采样固定候选词数不同,Top-p 采样动态调整候选词的数量,这使得它在生成过程中更加灵活和多样。其公式为:
\[ \sum_{i=1}^{n} P(w_i) \geq p \]P(w_i) 是每个候选词的概率,p 是预定的累积概率阈值。Top-p 采样适用于对生成多样性要求较高的任务,如 创意写作(Creative Writing) 或 开放域问答(Open-Domain QA),它能够灵活调整候选词的数量,从而在生成中加入更多的随机性。
Note: 无论是 Top-K 还是 Top-P,都分两步:
限制候选集合
- Top-K:截断概率分布,保留概率最高的 K 个 token;
- Top-P:累计概率到 p,保留使总和 ≥ p 的最小集合。
在候选集合中随机采样
- 不是选最大概率,而是根据保留下来的子集,重新归一化概率,再随机抽样。
- e.g. Top-K = 3 → 保留 A, B, C。重新归一化: $$ P_{\text{new}}(A) = \frac{0.35}{0.35+0.30+0.15} \approx 0.4375 $$
$$ P_{\text{new}}(B) = \frac{0.30}{0.80} = 0.375 $$
$$ P_{\text{new}}(C) = \frac{0.15}{0.80} = 0.1875 $$ 然后按照这个新概率随机选择。
⁉️ 温度参数(Temperature)如何影响 Decoder-only 模型的生成结果?
温度参数(Temperature)如何影响 Decoder-only 模型的生成结果?
温度参数(Temperature)在 Decoder-only 模型(如 GPT)中用于 控制生成文本的随机性或确定性。它的作用是在模型生成过程中对 输出概率分布(Output Probability Distribution)进行调整,从而影响模型的生成结果。温度的公式通常为:
\[ P(w) = \frac{e^{\frac{log(P(w))}{T}}}{\sum_{w{\prime}} e^{\frac{log(P(w{\prime}))}{T}}} \]其中,P(w) 是生成某个单词 w 的原始概率,T 是温度参数, w’ 是所有可能的单词。温度参数 T 控制了概率分布的平滑度。当 T = 1 时,模型按照正常的概率分布生成输出;当 T > 1 时,概率分布变得更加平缓,生成的结果会更加随机,可能导致较为多样化的输出;当 T < 1 时,概率分布变得更加陡峭,模型会更加倾向于选择概率较高的词语,从而生成更加确定性和保守的结果。
温度的调整作用于 softmax 函数(用于将模型的原始输出转换为概率分布)。通过改变温度值,模型可以控制生成内容的多样性和创造性。较高的温度通常会增加生成内容的创新性,但可能导致语法错误或不连贯的输出,而较低的温度则会使输出更加连贯和符合预期,但可能缺乏创意或多样性。
例如,在文本生成任务中,若我们将温度设为 1.0,则生成的文本遵循模型原本的概率分布;若我们将温度设为 0.5,生成的文本将更加趋向于模型最有可能生成的词,文本可能会变得单调和缺乏创意;若温度设为 1.5,则生成的文本可能会表现出更多的创造性,但也可能出现语法错误或不太连贯的部分。
⁉️ 什么是LLama?它有哪些技术特点?
什么是LLama?它有哪些技术特点?
LLaMA(Large Language Model Meta AI) 是由 Meta(前 Facebook)推出的大规模语言模型,旨在提供高效的文本生成和理解能力,同时优化计算资源的利用。它基于 Transformer 架构,并采用了一系列优化技术,使其在计算资源较低的情况下仍能达到或超过 GPT-3 级别的性能。LLaMA 主要基于 Decoder-Only Transformer,即 因果语言模型(Causal Language Model, CLM),用于自回归文本生成。LLaMA 在多个方面进行了优化,包括数据选择、模型架构调整、训练方法等,主要特点如下:
- 更高效的训练
- 数据优化:LLaMA 训练时使用了更高质量的文本数据,减少了低质量和冗余数据,从而提高了训练效率和泛化能力。
- 更少计算资源:相比 GPT-3(175B 参数),LLaMA 采用了更小规模的参数(如 LLaMA-7B、LLaMA-13B、LLaMA-65B),但在多个基准测试中仍能达到甚至超越 GPT-3 的效果。
- Transformer 架构优化
- RoPE(旋转位置编码,Rotary Position Embeddings):LLaMA 使用 RoPE 代替传统的 绝对位置编码(Absolute Positional Encoding),使得模型可以更好地处理长文本:
- SwiGLU 激活函数(Swish-Gated Linear Unit):LLaMA 采用 SwiGLU 代替 ReLU 或 GELU 作为激活函数,提高了模型的表示能力:
Note: LLaMA 选择 SwiGLU (Swish Gated Linear Unit) 作为激活函数,而非标准的 ReLU (Rectified Linear Unit) 或 GELU (Gaussian Error Linear Unit),主要是因为 SwiGLU 在大规模语言模型训练中的性能优势。首先,SwiGLU 结合了 Swish activation 和 Gated Linear Unit (GLU) 结构,使其能够 在非线性表达能力和计算效率之间取得平衡。相比于 ReLU,SwiGLU 避免了 dying ReLU problem(神经元输出恒为零的问题),并且减少了梯度消失现象。而相较于 GELU,SwiGLU 在实践中展现出了更优的梯度流动特性,并提高了训练稳定性。此外,SwiGLU 通过门控机制有效地增强了模型的表示能力,同时在 Transformer 结构中带来了更好的 parameter efficiency(参数效率),这对于大规模预训练模型至关重要。因此,LLaMA 采用 SwiGLU 作为激活函数,以提高整体的模型性能和训练效率。
- 不使用 Position Embedding Table:LLaMA 放弃了传统的 绝对位置编码,转而使用 RoPE,减少了额外的参数,同时增强了模型的泛化能力。
- Flash Attention 提高推理效率:LLaMA 可能使用 Flash Attention 进行加速,减少了传统 Transformer 中注意力计算的 时间复杂度: