感知机和神经网络(Perceptrons and Neural Network) #
感知机(Perceptron)是神经网络(Neural Network)的雏形,基于单个或多个 神经元(Neuron) 通过线性组合和简单的激活函数(如阶跃函数)实现输入数据的分类。神经元是感知机的基本组成单元,其功能是对输入特征进行加权、偏置调整并生成输出。随着任务复杂性的增加,感知机被扩展为 多层感知机(Multilayer Perceptron, MLP),通过堆叠多个隐藏层并引入非线性激活函数,使网络能够表达复杂的映射关系,解决非线性问题,是前馈神经网络(Feedforward Neural Network)的核心架构。
神经元(Neuron) #
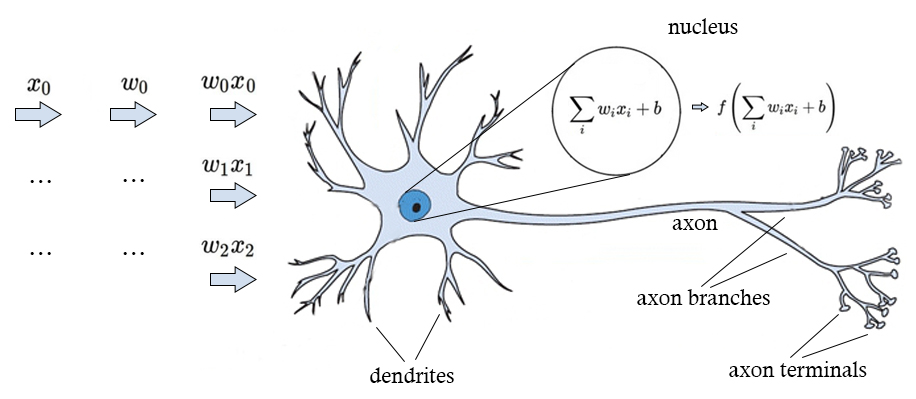
神经元(Neuron)是神经网络的最基本单元,模拟生物神经元的行为。它的主要功能是 接收输入、加权处理并通过激活函数生成输出。
\[ y = f\left(\sum_{i=1}^n w_i x_i + b\right) \]其中:
- \(x_i\) : 输入特征。
- \(w_i\) : 权重,衡量每个输入的影响程度。
- \(b\) : 偏置,用于调整输出的灵活性。
- \(f(\cdot)\)
: 激活函数,增加非线性能力(如
ReLU、Sigmoid)。 - \(y\) : 输出信号。
感知机(Perceptrons) #
感知器(Perceptrons)是一种执行 二元分类(binary classification) 的神经网络,它将输入特征映射到输出决策,通常将数据分为两个类别之一,例如 0 或 1。感知器由一层输入节点(input nodes)组成,这些节点与一层输出节点(output nodes)完全连接(fully connected)。感知子可以用图像表示为:
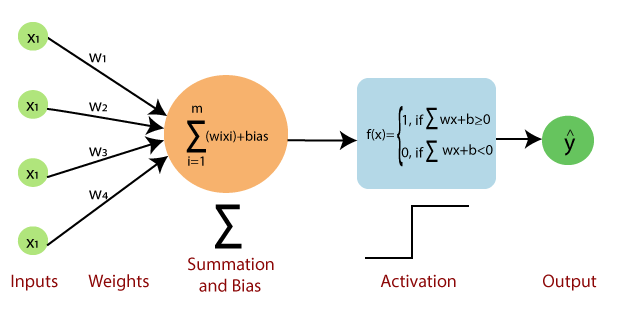
单个感知机可以看作是一个最简单的神经元,专注于实现线性分类任务。单个神经元是感知机的扩展形式,通过引入更灵活的激活函数和多层结构,可以应用于更复杂的问题。
模型结构 #
感知机的基本结构包括以下组成部分:
- 输入层(Input Layer):接收输入特征向量 \(x = [x_1, x_2, \dots, x_n]\) 。
- 权重向量(Weights):每个输入特征 \(x_i\) 对应的权重 \(w_i\) 。
- 偏置(Bias, b):平移决策边界,增强模型的灵活性。
- 线性组合: \[ z = W^T X + b = \sum_{i=1}^n w_i x_i + b \]
- 激活函数(Activation Function):通常为符号函数 \(\text{sign}(z)\)
,用于将加权和映射为输出标签。
- 输出结果: \[ y = \text{sign}(z) = \begin{cases} +1, & \text{if } z \geq 0 \\ -1, & \text{if } z < 0 \end{cases} \]
损失函数 #
感知机的损失函数本质上是用来惩罚误分类样本,从而引导模型学习到能够正确分类所有样本的权重参数。他的主要目标是找到一个超平面(hyperplane): \(w^T x + b = 0\) 。使得数据点能够被正确分类,即:
- 如果 \(y_i = +1\) ,那么希望 \(w^T x_i + b > 0\) ;
- 如果 \(y_i = -1\) ,那么希望 \(w^T x_i + b < 0\) 。
感知机的损失函数只关注那些被误分类的样本。对于误分类的样本,有: \[ y_i (w^T x_i + b) \leq 0 \]
损失函数定义为所有误分类样本的负边界距离的总和: \[ L(w, b) = -\sum_{i \in M} y_i (w^T x_i + b) \]
- \(M\) 表示所有被误分类的样本的集合;
- \(y_i (w^T x_i + b)\) 表示样本 \(x_i\) 到决策超平面的有符号距离。
更新规则 #
严格来说,感知机本身并不使用梯度下降法进行优化,因为感知机的损失函数是分段的、非连续的,无法直接对其求导。感知机的权重更新公式是: \[ \begin{align*} &w \leftarrow w + \eta \cdot y_i \cdot x_i \\ &b \leftarrow b + \eta \cdot y_i \\ \end{align*} \]
感知机的权重更新可以看作是一种离散化、非平滑的近似梯度下降过程:
- 每次只对一个误分类样本 \(x_i\) 更新权重和偏置;
- 更新方向为该样本的贡献( \(-y_i x_i\) 的负梯度方向);
从几何角度看:如果一个样本被误分类,更新方向是沿着样本 \(x_i\) 的方向,并且朝着正确分类 \(y_i\) 的方向推进决策边界。
感知机(Perceptrons)和逻辑回归(Logistic Regression)的区别 #
感知机(Perceptrons)和逻辑回归(Logistic Regression)在表面上确实有很多相似之处,因为它们都属于线性模型,但它们的核心区别在于损失函数和输出目标。
激活函数区别
- Perceptrons 使用符号函数(sign function)作为激活函数。这意味着感知机的输出是基于决策边界的二元结果,不提供概率信息。 \[ y = \text{sign}(w^T x + b) \]
- Logistic Regression 使用逻辑函数(sigmoid function)将线性组合结果映射到概率范围: \[ P(y=1|x) = \sigma(w^T x + b) = \frac{1}{1 + e^{-(w^T x + b)}} \]
损失函数区别
- Perceptrons 的学习目标是最小化误分类样本的数量,仅对被误分类的样本进行权重更新。 \[ L(w, b) = -\sum_{i \in M} y_i (w^T x_i + b) \]
- Logistic Regression 通过最大化条件概率 \(P(y|x)\) 的对数似然来优化参数: \[ L(w, b) = -\sum_{i=1}^N \left[y_i \log(\sigma(w^T x_i + b)) + (1 - y_i) \log(1 - \sigma(w^T x_i + b)) \right] \]
决策边界区别
感知机和逻辑回归都假设数据是线性可分的,因此其决策边界都是一个超平面:
- Perceptrons 直接依赖超平面将数据划分为两个类别,但没有提供关于样本距离边界的任何信息。
- Logistic Regression 利用概率信息描述样本在边界两侧的信心度,决策边界定义为 \(P(y=1|x) = 0.5\) 。
Note: Perceptrons 通常仅适用于线性可分的数据。算法在数据线性可分时会收敛;但如果数据线性不可分,则会陷入无限循环。Logistic Regression 可处理线性不可分数据,即使数据线性不可分,也能找到最优的权重(通过拟合概率分布)。
感知机代码实现 #
# <--- From scratch --->
import numpy as np
def Perceptrons(X, y, lr, max_iter):
n_samples, n_features = X.shape
weights = np.zeros(n_features)
bias = 0
for _ in range(max_iter):
for i in range(n_samples):
# 计算线性输出
linear_output = np.dot(X[i], weights) + bias
# 如果预测错误,则更新权重和偏置
if y[i] * linear_output <= 0:
weights += lr * y[i] * X[i]
bias += lr * y[i]
return weights, bias
# 模型预测
def predict(X, weights, bias):
linear_output = np.dot(X, weights) + bias
return np.where(linear_output >= 0, 1, -1)
# 数据示例
X = np.array([[1, 1], [2, 1], [1, 2], [-1, -1], [-2, -1], [-1, -2]])
y = np.array([1, 1, 1, -1, -1, -1])
# 模型训练
weights, bias = Perceptrons(X, y, lr=0.1, max_iter=10)
# 输出结果
print("学习到的权重:", weights)
print("学习到的偏置:", bias)
# 进行预测
predictions = predict(X, weights, bias)
print("预测结果:", predictions)
多层感知机(Multilayer Perceptron,MLP) #
多层感知机(MLP)是最常见的前馈神经网络(Feedforward Networks)之一,由多个全连接层组成。它是神经网络的基础结构,广泛用于分类、回归等任务。MLP的核心思想是通过隐藏层和非线性激活函数,提取输入数据的特征并映射到目标输出。
输入层(Input Layer) #
输入层是多层感知机(MLP)的第一部分,用于接收外部输入数据并将其传递给网络的隐藏层。输入层的设计直接决定了模型对数据的适配能力。输入层可以视为数据和网络之间的接口:
- 数据接受:接收外部特征输入,通常以向量或矩阵的形式表示。
- 维度映射:将原始数据的特征维度( \(d\) )映射到神经网络的内部表示维度。输入数据的特征维度需与输入层的线性变换参数兼容。
- 数据传递:输入层通过线性变换(如 \(xW + b\) )将输入映射到第一个隐藏层的维度。它仅负责将输入数据直接传递到隐藏层。
神经元(Neuron)数量:输入层的神经元数量等于第一个隐藏层的神经元数量,即输入层通过线性变换将输入特征映射到第一个隐藏层的维度。输入数据的特征数量( \(d\) )决定了输入层每个神经元的权重数量:
- 对于输入维度为 \(d\) 的数据,每个神经元会有 \(d\) 个权重加上一个偏置项。
- 示例: 如果输入数据具有 4 个特征(如 \([x_1, x_2, x_3, x_4]\)
),且第一个隐藏层包含 10 个神经元,则输入层需要:
- 10 个神经元(每个神经元与隐藏层的每个神经元一一对应)。
- 每个神经元包含 4 个权重(分别对应 4 个输入特征)和 1 个偏置项。
输入数据格式:输入数据通常为一个向量或矩阵:
- 单样本输入: 向量形式,如 \([x_1, x_2, …, x_d]\) 。
- 批量输入: 矩阵形式,形状为 \((\text{batch size}, d)\) ,其中 \( \text{batch size} \) 为每次输入的样本数, \(d\) 为特征数。
- 代码示例:
class SimpleInputLayer(nn.Module): def __init__(self, input_dim, hidden_dim): super(SimpleInputLayer, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) # 从输入层到第一个隐藏层的线性变换 self.relu = nn.ReLU() # 激活函数(ReLU) def forward(self, x): x = self.fc1(x) # 输入数据经过线性变换 x = self.relu(x) # 使用 ReLU 激活函数 return x
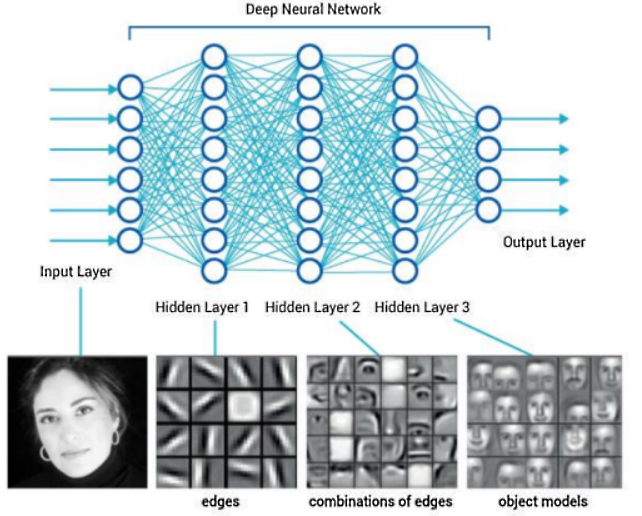
隐藏层(Hidden Layer) #
隐藏层是神经网络中介于输入层和输出层之间的层,它是神经网络学习和表示复杂映射关系的关键部分。隐藏层通过层叠的神经元以及非线性激活函数,能够从数据中提取特征和学习模式,是深度学习的核心。隐藏层的主要功能有:
- 特征提取:隐藏层负责从输入数据中提取有用的特征,形成更高维、更抽象的表示。
- 非线性映射:通过非线性激活函数(如
ReLU、Sigmoid、Tanh),隐藏层能够学习复杂的非线性关系,而非仅仅是简单的线性变换。 - 数据处理:每个隐藏层接收上一个层的输出,经过线性变换和激活函数处理后,传递到下一层。
每个隐藏层由以下三部分组成:
- 神经元:
- 每个神经元代表一个计算单元,接收来自上一层所有神经元的输入,加权求和后进行激活函数变换。
- 隐藏层的神经元数量是一个超参数,需要根据具体问题进行选择。
- 权重(Weights)和偏置(Biases):
- 权重:连接两层之间的神经元,并决定输入的重要性。
- 偏置:用于调整激活函数的输出,增加模型的表达能力。
- 公式: \(z = xW + b\) ,其中 \(x\) 是输入, \(W\) 是权重矩阵, \(b\) 是偏置向量。
- 激活函数:
激活函数引入非线性,使神经网络能够学习复杂的非线性映射。
常见激活函数:
ReLU (Rectified Linear Unit)
\[ f(x) = \max(0, x) \]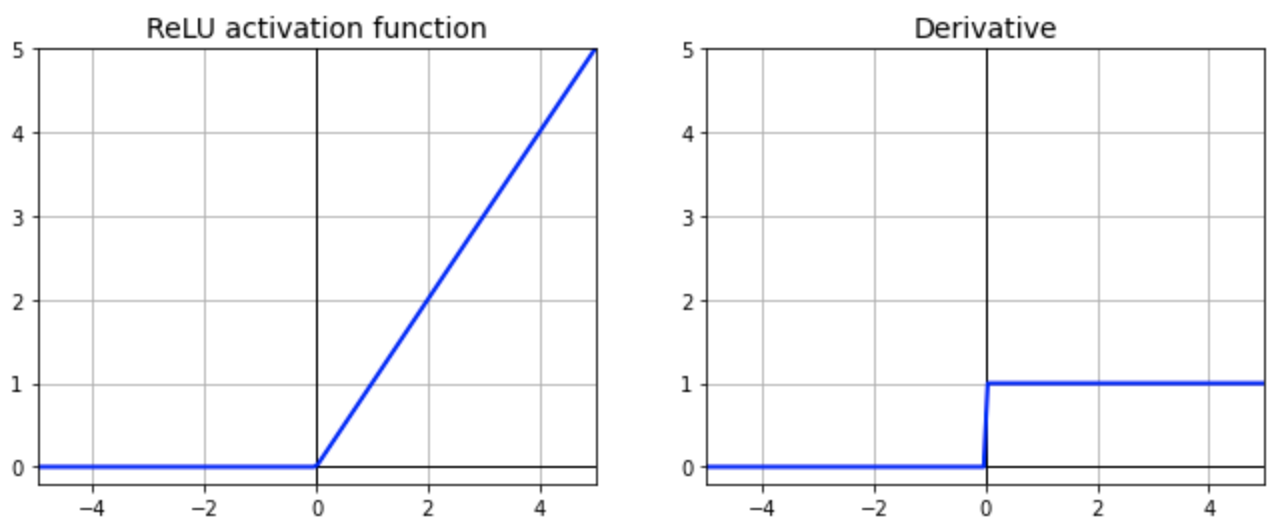
- 计算简单:仅比较输入值是否大于 0,操作速度快。
- 非线性:尽管形式简单,但 ReLU 是非线性的,可帮助网络学习复杂特征。
- 稀疏性:当输入小于 0 时,输出为 0,相当于让部分神经元不激活,提升模型稀疏性。
- 问题:可能导致“神经元死亡”(当许多权重使输入始终小于 0,导致该神经元永不更新)。
- ReLU 广泛应用于深层神经网络,一般情况下是默认选择,适合大多数场景。
Sigmoid
\[ f(x) = \frac{1}{1 + e^{-x}} \]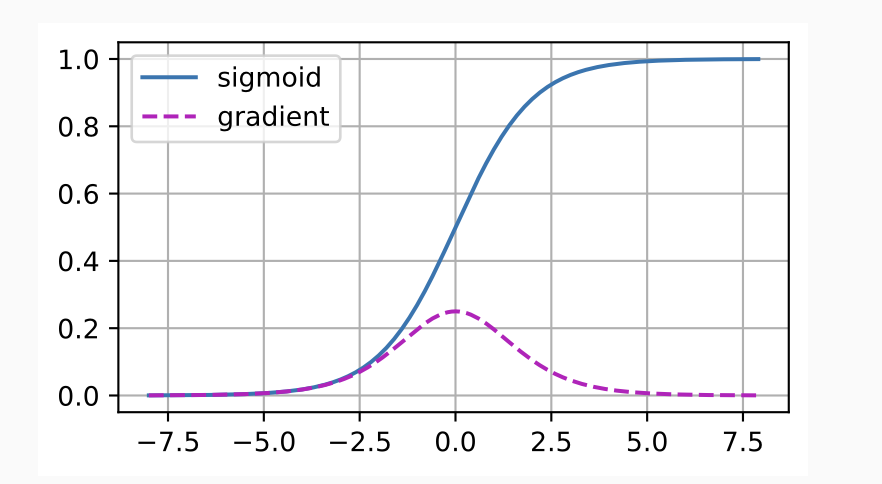
- 输出范围: \([0, 1]\) ,适合表示概率值。
- 单调性:对于输入增大,输出逐渐趋近于 1,但变化减缓。
- 梯度消失问题:当 \(x\) 的绝对值较大时,函数的梯度趋近于 0,导致反向传播时权重更新困难。
Tanh (双曲正切函数)
\[ f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} \]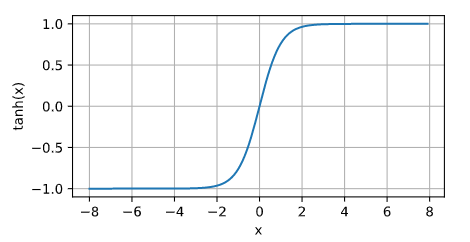
- 输出范围: \([-1, 1]\) ,比 Sigmoid 更对称,适合隐藏层激活函数。
- 对称性:中心对称于原点,有助于加速收敛。
- 梯度消失问题:与 Sigmoid 类似,当 \(x\) 的绝对值较大时,梯度会趋近于 0。
关于非线性
- 线性关系:一个函数是线性的,如果它满足叠加性和齐次性,即: \(f(ax + by) = a \cdot f(x) + b \cdot f(y)\) 例如: \(y = 2x + 3\) 是线性函数。它的图形是一直线。
- 非线性关系:非线性函数不满足上述性质。例如: \(y = x^2\) 或 \(y = \sin(x)\) 是非线性的。它的图形可能是弯曲的、不规则的。
Note: 如果神经网络的每一层都只包含线性变换,那么即使增加多层隐藏层,整个网络仍然是一个线性函数的组合。非线性让网络能够学习复杂的映射关系,如分类非线性可分的数据、逼近复杂函数等。
激活函数的形状的确会影响它的性能,但并非关键因素。重要的是它能够引入 非线性特性,打破线性关系的局限性。
激活函数通常是 element-wise(逐元素)操作,逐元素操作不改变张量的形状,只改变其值,适合深度学习网络中逐层特征变换的需要。他的作用是提取特征和表示,而不是直接产生概率分布。
Note: 神经网络的目标 不是直接寻找一个显式的数学公式(如通用曲线),而是构建一种复杂的非线性映射,将输入特征与输出目标连接起来。这种映射是通过网络参数的学习过程(如权重和偏置的调整)隐式表达的。虽然网络可以实现“圆形”或“复杂形状”的决策边界,但这不是通过显式地拟合一个圆的方程,而是通过层层线性变换与非线性激活的组合自动得出的结果。
隐藏层理解
隐藏层的作用可以类比为数据的逐步“翻译”或“加工”:
- 低层特征提取:第一层隐藏层处理输入数据的基本特征(如简单的边缘、颜色或频率等)。
- 中层特征组合:中间层将低层特征组合成更高阶的特征(如形状、局部模式或局部结构)。
- 高层特征整合:更深层次的隐藏层进一步整合复杂特征,用于最终分类或预测任务。
每一层将数据映射到新的特征空间中,这种映射使得神经网络能够捕获从简单到复杂的模式。隐藏层维度的设计通常遵循“逐步扩展—再收缩”的模式:
- 增加维度:扩展特征空间
- 增加维度可以让模型在更高维的特征空间中提取更加复杂和细粒度的模式。
- 例如,输入层可能包含较少的原始特征(如像素、频谱或特定数值),但这些特征经过线性变换和激活后,隐藏层可以生成更多维度的“隐含特征”。
- 扩展特征空间类似于“打开数据的潜力”,为网络提供更丰富的信息处理能力。
- 减少维度:聚合有用信息
- 在后续隐藏层中减少维度是为了压缩特征表示,去除冗余信息,仅保留与任务相关的高质量特征。
- 这一过程可以防止模型过拟合,同时提高计算效率和泛化能力。
- 减少维度还可以实现对数据的进一步“压缩”,形成对输入数据的简洁而有力的表示。
Note: 为什么逐步增加维度(e.g. dim4 -> dim128 -> dim256 -> dim512)而不是直接扩展到高维(e.g. dim4 -> dim512)?
直接扩展到高维,模型可能无法有效捕获特征层次,会使学习过程更加困难。需要的权重参数过多,特别是在数据量不足时效果较差。同时由于缺少逐步提取特征的过程,模型可能过于依赖输入数据的特定模式。
- 代码示例:
import torch
import torch.nn as nn
class SimpleHiddenLayer(nn.Module):
def __init__(self, input_dim, hidden_dims):
super(SimpleHiddenLayer, self).__init__()
layers = []
for i in range(len(hidden_dims)):
in_dim = input_dim if i == 0 else hidden_dims[i - 1]
out_dim = hidden_dims[i]
layers.append(nn.Linear(in_dim, out_dim)) # 线性变换
layers.append(nn.ReLU()) # ReLU 激活函数
self.hidden_layers = nn.Sequential(*layers) # 将所有隐藏层组合为一个模块
def forward(self, x):
return self.hidden_layers(x) # 输入依次通过所有隐藏层
输出层(Output Layer) #
输出层是神经网络的最后一部分,其核心职责是根据模型的目标任务(Cost function),生成适合应用场景的输出。不同任务对输出层的设计要求不同,例如分类、回归或生成任务等。输出层的实现通常结合特定的单元(如线性、Sigmoid、Softmax)和损失函数,以适应不同类型的数据分布和学习目标。
- 线性单元(Linear Units)
- 适用场景: 连续型输出(如回归任务)。
- 数学表达式: 输出值 \(y = xW + b\) (无激活函数)。
- 解释:
- 线性单元生成实值输出,不引入非线性变换。
- 损失函数通常为均方误差(MSE): \(L = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2\) ,其中 \(\hat{y}_i\) 是预测值。
- 代码示例:
class LinearOutputLayer(nn.Module): def __init__(self, input_dim): super(LinearOutputLayer, self).__init__() self.fc = nn.Linear(input_dim, 1) # 线性变换(输出一个数值) def forward(self, x): x = self.fc(x) # 线性变换 return x
- Sigmoid 单元
- 适用场景: 二分类任务。
- 数学表达式: \(y = \sigma(xW + b) = \frac{1}{1 + e^{-(xW + b)}}\) 。
- 解释:
- Sigmoid 单元将输出值压缩到区间 \((0, 1)\) ,解释为正样本的概率 \(P(y=1|x)\) 。
- 损失函数通常为二元交叉熵损失(Binary Cross-Entropy Loss): \(L = - \frac{1}{n} \sum_{i=1}^n [y_i \log(\hat{y}_i) + (1-y_i)\log(1-\hat{y}_i)]\) ,其中 \(\hat{y}_i\) 是预测的概率值。
- 代码示例:
class BinaryOutputLayer(nn.Module): def __init__(self, input_dim): super(BinaryOutputLayer, self).__init__() self.fc = nn.Linear(input_dim, 1) # 线性层,将输入映射到 1 个输出(概率) self.sigmoid = nn.Sigmoid() # Sigmoid 激活函数 def forward(self, x): x = self.fc(x) # 线性变换 x = self.sigmoid(x) # Sigmoid 激活函数 return x
- Softmax 单元
- 适用场景: 多分类任务。
- 数学表达式: \(y_j = \frac{e^{z_j}}{\sum_{k=1}^K e^{z_k}}\) ,其中 \(z_j\) 是第 \(j\) 类的得分。
- 解释:
- Softmax 单元将多个输出值转换为概率分布,保证 \(\sum_{j=1}^K y_j = 1\) ,每个 \(y_j\) 表示属于第 \(j\) 类的概率。
- 损失函数通常为多分类交叉熵损失(Categorical Cross-Entropy Loss): \(L = - \sum_{i=1}^n \sum_{j=1}^K y_{ij} \log(\hat{y}_{ij})\) ,其中 \(y_{ij}\) 是真实标签, \(\hat{y}_{ij}\) 是预测概率。
- 代码示例:
class MultiClassOutputLayer(nn.Module): def __init__(self, input_dim, num_classes): super(MultiClassOutputLayer, self).__init__() self.fc = nn.Linear(input_dim, num_classes) # 输出类别数个神经元 self.softmax = nn.Softmax(dim=1) # Softmax 激活函数 def forward(self, x): x = self.fc(x) # 线性变换 x = self.softmax(x) # Softmax 激活函数 return x
神经网络运行流程和原理 #
向前传播 (Forward Propagation) #
向前传播 (Forward Propagation) 通过网络层层传递数据,逐步对输入进行线性变换和非线性映射,提取特征并输出预测结果。

输入层到隐藏层: 假设输入层的输入为 \( x \) ,第一个隐藏层的权重矩阵为 \( W^{(1)} \) ,偏置为 \( b^{(1)} \) 。计算该层的线性变换:
- 线性变换: \( z^{(1)} = W^{(1)} x + b^{(1)} \) 其中, \( z^{(1)} \) 是第一个隐藏层的线性变换输出。
- 激活函数: 经过激活函数 \( \varphi(\cdot) \) 后得到隐藏层的输出: \( h^{(1)} = \varphi(z^{(1)}) = \varphi(W^{(1)} x + b^{(1)}) \) 其中, \( \varphi(\cdot) \) 可以是常见的激活函数,如 ReLU 或 Sigmoid,具体的形式取决于任务需求。
隐藏层到输出层: 假设输出层的权重矩阵为 \( W^{(2)} \) ,偏置为 \( b^{(2)} \) 。该层的输出经过线性变换并得到最终的输出。
- 线性变换: \( z^{(2)} = W^{(2)} h^{(1)} + b^{(2)} \) 其中, \( h^{(1)} \) 是上一层的输出, \( z^{(2)} \) 是当前层的线性变换输出。
- 激活函数: 直接得到预测值(例如在回归问题中,输出层可能不使用激活函数)。
- 如果是分类问题: \( \hat{y} = \varphi(z^{(2)}) = \varphi(W^{(2)} h^{(1)} + b^{(2)}) \)
- 如果是回归问题(没有激活函数): \( \hat{y} = W^{(2)} h^{(1)} + b^{(2)} \) 其中, \( \hat{y} \) 是最终输出。
损失函数的计算: 最终,我们计算输出与真实标签之间的损失,通常使用损失函数 \( L = l(\hat{y} , y) \) ,其中 \( \hat{y} \) 是网络的预测输出, \( y \) 是实际标签。
完整流程: \[ z^{(1)} = W^{(1)} x + b^{(1)} → h^{(1)} = \varphi(z^{(1)}) → z^{(2)} = W^{(2)}h^{(1)} + b^{(2)}→ \hat{y} = \varphi(z^{(2)}) → L = l(\hat{y}, y) \]
向后传播 (Backward Propagation) #
向后传播是计算梯度并调整模型参数的过程,用于优化神经网络。通过链式法则,逐层计算损失函数对每个参数的偏导数。我们在向后传播中关注的重点在于计算权重(weight)和偏置(bias)的梯度。
链式法则的数学公式: 设有复合函数: \( y = f(g(h(x))) \) 展开形式: \( \frac{dy}{dx} = \frac{dy}{dg} \cdot \frac{dg}{dh} \cdot \frac{dh}{dx} \)
损失函数对输出的梯度: 首先,从损失函数出发,计算损失函数对输出层的梯度。
- 损失函数: \( L = l(\hat{y}, y) \) 其中, \( \hat{y} \) 是模型的输出, \( y \) 是真实标签。
- 损失函数关于输出层的梯度是: \[ \frac{\partial L}{\partial \hat{y}} = \frac{\partial l(\hat{y}, y)}{\partial \hat{y}} \]
输出层到隐藏层的梯度: 接下来,我们需要计算损失函数对第二层权重矩阵 \( W^{(2)} \) 和偏置项 \( b^{(2)} \) 的梯度 (i.e. \( \frac{\partial L}{\partial W^{(2)}}\) , \( \frac{\partial L}{\partial b^{(2)}}\) )。
- 我们有 \(\hat{y} = \varphi(z^{(2)})\) ,由此可得输出层的梯度对第二层的加权输入 \( z^{(2)} \) 的偏导数: \[ \frac{\partial L}{\partial z^{(2)}} = \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z^{(2)}} \]
- 我们有 \(z^{(2)} = W^{(2)}h^{(1)} + b^{(2)}\) ,然后计算损失函数对第二层权重矩阵 \( W^{(2)} \) 和偏置项 \( b^{(2)}\) 的梯度: \[ \frac{\partial L}{\partial W^{(2)}} = \frac{\partial L}{\partial z^{(2)}} \cdot \frac{\partial z^{(2)}}{\partial W^{(2)}} = \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z^{(2)}} \cdot \frac{\partial z^{(2)}}{\partial W^{(2)}} \] 以及 \( \frac{\partial L}{\partial b^{(2)}} = \frac{\partial L}{\partial z^{(2)}} \cdot \frac{\partial z^{(2)}}{\partial b^{(2)}} = \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z^{(2)}} \cdot \frac{\partial z^{(2)}}{\partial b^{(2)}} \)
隐藏层到输入层的梯度: 接着,我们需要计算损失函数对第一层的权重矩阵 \( W^{(1)} \) 和偏置项 \( b^{(1)} \) 的梯度。
- 从 \(z^{(2)} = W^{(2)}h^{(1)} + b^{(2)}\) 和 \(h^{(1)} = \varphi(z^{(1)})\) 我们可以得到: \[ \frac{\partial L}{\partial z^{(1)}} = \frac{\partial L}{\partial h^{(1)}} \cdot \frac{\partial h^{(1)}}{\partial z^{(1)}} = \frac{\partial L}{\partial z^{(2)}} \cdot \frac{\partial z^{(2)}}{\partial h^{(1)}} \cdot \frac{\partial h^{(1)}}{\partial z^{(1)}} \]
- 然后从 \(z^{(1)} = W^{(1)} x + b^{(1)}\) ,计算损失函数对第一层权重矩阵 \( W^{(1)} \) 和偏置项 \( b^{(1)}\) 的梯度: \[ \frac{\partial L}{\partial W^{(1)}} = \frac{\partial L}{\partial z^{(1)}} \cdot \frac{\partial z^{(1)}}{\partial W^{(1)}}=\frac{\partial L}{\partial z^{(2)}} \cdot \frac{\partial z^{(2)}}{\partial h^{(1)}} \cdot \frac{\partial h^{(1)}}{\partial z^{(1)}} \cdot \frac{\partial z^{(1)}}{\partial W^{(1)}} \]
以及 \( \frac{\partial L}{\partial b^{(1)}} = \frac{\partial L}{\partial z^{(1)}} \cdot \frac{\partial z^{(1)}}{\partial b^{(1)}}=\frac{\partial L}{\partial z^{(2)}} \cdot \frac{\partial z^{(2)}}{\partial h^{(1)}} \cdot \frac{\partial h^{(1)}}{\partial z^{(1)}} \cdot \frac{\partial z^{(1)}}{\partial b^{(1)}} \)
参数更新: 在向后传播过程中,我们计算出了所有需要的梯度,接下来进行参数更新。在每次迭代中,通过梯度下降更新每个权重和偏置项:
- 更新权重: \( W^{(1)} = W^{(1)} - \eta \frac{\partial L}{\partial W^{(1)}} \) , \( W^{(2)} = W^{(2)} - \eta \frac{\partial L}{\partial W^{(2)}} \)
- 更新偏置: \( b^{(1)} = b^{(1)} - \eta \frac{\partial L}{\partial b^{(1)}} \) , \( b^{(2)} = b^{(2)} - \eta \frac{\partial L}{\partial b^{(2)}} \)
Note:激活值本身并不会直接被用于反向传播,而是激活值的导数和前一层的梯度共同作用于权重的更新。在反向传播中,计算每一层的梯度时需要用到激活函数的导数,而不是激活值本身。
简单神经网络代码实现 #
# <--- From scratch --->
import numpy as np
def ReLu(x):
return np.maximum(0, x)
def ReLU_derivative(z):
return (z > 0).astype(float)
def Softmax(x):
exp_x = np.exp(x - np.max(x, axis=1, keepdims=True)) # 防止溢出
return exp_x / np.sum(exp_x, axis=1, keepdims=True)
# 损失函数和其导数
def Cross_entropy_loss(y_hat, y):
m = y.shape[0]
return -np.sum(y * np.log(y_hat + 1e-15)) / m
def Cross_entropy_loss_derivative(y_hat, y):
return y_hat - y
def MLP(X, y, max_iter, learning_rate):
input_dim = 3
hidden_dim = 5
output_dim = 1
W1 = np.random.randn(hidden_dim, input_dim) * 0.01
b1 = np.zeros((hidden_dim, 1))
W2 = np.random.randn(output_dim, hidden_dim) * 0.01
b2 = np.zeros((output_dim, 1))
def Forward_Propagation(X, W1, b1, W2, b2):
z1 = np.dot(W1, X.T) + b1
h1 = ReLu(z1)
z2 = np.dot(W2, h1.T) + b2
y_hat = Softmax(z2.T)
return z1, h1, z2, y_hat
def Backward_Propagation(X, y, z1, h1, z2, y_hat, W1, W2):
m = X.shape[0]
dz2 = cross_entropy_loss_derivative(y_hat, y)
dW2 = np.dot(dz2.T, h1.T) / m
db2 = np.sum(dz2.T, axis=1, keepdims=True) / m
dh1 = np.dot(W2.T, dz2.T)
dz1 = dh1 * relu_derivative(z1)
dW1 = np.dot(dz1, X) / m
db1 = np.sum(dz1, axis=1, keepdims=True) / m
return dW1, db1, dW2, db2
for i in range(max_iter):
z1, h1, z2, y_hat = Forward_Propagation(X, W1, b1, W2, b2)
loss = Cross_entropy_loss(y_hat, y)
dW1, db1, dW2, db2 = Backward_Propagation(X, y, z1, h1, z2, y_hat, W1, W2)
W1 -= learning_rate * dW1
b1 -= learning_rate * db1
W2 -= learning_rate * dW2
b2 -= learning_rate * db2
return W1, b1, W2, b2
# <--- From pytorch --->
import torch
import torch.nn as nn
import torch.optim as optim
class MLP(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super().__init__()
self.layer1 = nn.Linear(input_dim, hidden_dim)
self.layer2 = nn.Linear(hidden_dim, output_dim)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.layer1(x))
x = self.layer2(x)
return x
torch.manual_seed(42)
X = torch.randn(100, 4) # 输入特征
y = torch.randint(0, 3, (100,)) # 3 类标签
# 模型初始化
input_dim = X.shape[1]
hidden_dim = 10
output_dim = 3
max_iter = 1000
model = MLP(input_dim, hidden_dim, output_dim)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
for epoch in range(max_iter):
y_hat = model(X)
loss = criterion(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")