面试准备大纲 #
基础理论 #
数学与统计学 #
- ✅ 线性代数(矩阵运算、特征值分解)
- ✅ 概率论与统计(贝叶斯定理、分布、假设检验)
- ✅ 优化方法(梯度下降、Adam、学习率调度)
机器学习基础 #
- ✅ 监督学习(线性回归、决策树、SVM、集成学习)
- ✅ 评估指标(准确率、召回率、F1、AUC-ROC)
- ✅ 过拟合与正则化(L1/L2、Dropout)
深度学习基础 #
- ⭐ 神经网络(前向传播、反向传播、激活函数)
⭐ RNN(序列建模、自回归、语言模型)
⁉️ 序列模型(Sequence Models)和传统模型有什么区别?
序列模型(Sequence Models)和传统模型有什么区别?
序列模型(Sequence Models)和传统模型的主要区别在于它们处理数据的方式。传统模型,如线性回归(Linear Regression),通常 假设输入数据是独立同分布(i.i.d., independent and identically distributed)的,即每个输入数据点的顺序不影响其他数据点。在这些模型中,数据被处理为独立的特征向量,通常是静态的,缺乏时间或顺序的关联。
序列模型,尤其是在自然语言处理领域,强调对数据中 时间或顺序信息的建模。他们往往能够通过其递归结构捕捉序列中前后数据点之间的依赖关系。序列模型在处理时考虑到顺序,因此它们在语言建模(Language Modeling)、语音识别(Speech Recognition)等任务中表现优异,因为这些任务 依赖于上下文信息和时间序列的动态变化。
⁉️ 什么是自回归(Autoregression)和自回归模型?
什么是自回归(Autoregression)和自回归模型?
自回归(Autoregression)是一种统计模型,用于预测时间序列数据中的未来值。它基于一个假设:当前的观测值(或输出)与过去的观测值有直接关系。自回归模型通过 使用历史数据点作为输入,预测下一个时间步的值。在这种模型中,当前的输出是历史数据的线性组合,具体来说,当前的值是由过去若干个数据点的加权和构成。
在自然语言处理(NLP)中的生成式语言模型(如自回归语言模型)中,自回归模型的原理类似于时间序列分析。自回归语言模型在生成文本时,将每个词作为输入,并依赖于已经生成的词序列来预测下一个词。在这种情况下,模型的预测依赖于前一个或前几个词,因此可以用自回归模型的框架来描述这一过程。它通过逐步生成下一个输出(例如,词或值)并基于之前的生成结果来调整预测,确保每一步都与前面的步骤密切相关。
⁉️ 如何定义语言模型?统计角度在解决的问题?什么是 n-gram模型?
如何定义语言模型?统计角度在解决的问题?什么是 n-gram模型?
在自然语言处理(NLP)中,语言模型(Language Model, LM) 是一种用于预测句子或文本中单词序列的模型。语言模型的核心目标是 估计一个给定单词序列出现的概率。具体来说,对于一个给定的单词序列,语言模型的任务是计算该序列的联合概率:
\[ P(x_1, \ldots, x_T) \]我们可以通过链式法则将序列的联合概率分解成条件概率的乘积,从而将问题转化为自回归预测(autoregressive prediction):
\[ P(x_1, \ldots, x_T) = P(x_1) \prod_{t=2}^T P(x_t \mid x_{t-1}, \ldots, x_1) \]在语言模型中,最常见的假设是 马尔科夫假设(Markov Assumption),即 当前单词的出现只依赖于前一个或前几个单词。基于这一假设,n-gram模型(n-gram model) 是一种常见的语言模型,它通过计算某个单词在给定其前 n-1 个单词的条件下出现的概率来进行预测。例如:
\[ P(x_1, \ldots, x_T) = P(x_1) \prod_{t=2}^T P(x_t \mid x_{t-1}) \]⁉️ 如何衡量语言模型质量?什么是困惑度(Perplexity)?
什么是困惑度(Perplexity)?
衡量语言模型质量的一种方法是评估其对文本的预测能力。一个好的语言模型 能够以较高的准确性预测下一个词(token)。
\[ P(x_1, \ldots, x_T) = P(x_1) \prod_{t=2}^T P(x_t \mid x_{t-1}, \ldots, x_1) \]为了量化模型质量,可以通过计算序列的似然(likelihood)。然而,直接比较似然值并不直观,因为较短的序列通常有更高的似然值。例如我们用交叉熵(cross-entropy)衡量模型对序列的预测能力。
\[ \frac{1}{n} \sum_{t=1}^n -\log P(x_t \mid x_{t-1}, \ldots, x_1) \]为了解决:“较短的序列通常有更高的似然值”,自然语言处理领域通常使用困惑度(Perplexity) 作为评价标准,它是交叉熵损失的指数形式:
\[ \text{Perplexity} = \exp\left(-\frac{1}{n} \sum_{t=1}^n \log P(x_t \mid x_{t-1}, \ldots, x_1)\right) \]困惑度可以理解为我们在选择下一个词时平均可用的真实选项数的倒数。困惑度越低,模型质量越高,表明其对文本序列的预测能力越强。
⁉️ 在 RNN 中是如何读取长序列数据(Partitioning Sequences)的?
在 RNN 中是如何读取长序列数据(Partitioning Sequences)的?
由于序列数据本质上是连续的,因此我们在处理数据时需要解决这个问题。为了高效处理数据,模型通常以固定长度的序列小批量(minibatch)为单位进行训练。一个关键问题是 如何从数据集中随机读取输入序列和目标序列的小批量。处理长序列数据时,常用的 Partitioning Sequences 方法主要包括以下几种:
- 固定长度切分(Fixed-length Splitting) 是最常见的方法之一,其中将长序列分割成固定大小的子序列。这种方法简单且易于实现,但可能会丢失跨子序列的上下文信息。
- 滑动窗口(Sliding Window) 方法通过定义一个窗口大小并在长序列中滑动该窗口来划分数据。每次滑动时,窗口会覆盖一定数量的词汇,并且每次滑动的步长通常为窗口大小的一部分,确保子序列之间有重叠,从而保持一定的上下文信息。
⁉️ 什么是RNN?描述RNN的基本结构??
什么是RNN?描述RNN的基本结构??
在用马尔可夫模型和n-gram模型用于语言建模时,这些模型中某一时刻的词(token)只依赖于前 n 个词。如果我们希望将更早时间步的词对当前词的影响考虑进来,就需要增加 n 的值。然而,随着 n 增加,模型参数的数量也会呈指数级增长,因为需要为词汇表中的每个词存储对应的参数。因此, 因此与其将历史信息模型化,不如使用隐变量模型(latent variable model):
\[ P(x_t \mid x_{t-1}, \ldots, x_1) \approx P(x_t \mid h_{t-1}) \]潜在变量模型的核心思想是通过 引入一个隐藏状态(hidden state),它保存了直到当前时间步的序列信息。具体来说,隐藏状态在任意时间步可以通过 当前输入 和 上一个隐藏状态 来计算:
\[ h_t = f(x_{t}, h_{t-1}) \]循环神经网络(RNN) 就是通过隐藏状态来建模序列数据的神经网络。RNN 由三个主要部分组成:
- 输入层(Input layer):接收序列数据,通常表示为词向量(word embeddings)或特征向量(feature vectors)。
- 隐藏层(Hidden layer):核心部分,由 隐藏状态(hidden state) 组成,每个时间步的隐藏状态不仅依赖于当前输入 x_t ,还依赖于前一个时间步的隐藏状态 h_{t-1} 。隐藏状态就是网络当前时刻的”记忆”。更新公式如下:
- 输出层(Output layer):用于预测目标值 y_t ,通常通过 全连接层(fully connected layer) 和 Softmax 激活函数(Softmax activation function) 计算类别概率:
在标准的RNN模型中,隐藏单元(hidden state)的权重是共享的,即相同的权重矩阵 W_xh(从输入到隐藏状态的权重)和 W_hh(从上一个时间步的隐藏状态到当前隐藏状态的权重)在每个时间步都会被复用。这意味着,RNN通过不断更新隐藏状态,并依赖同一组权重来捕捉序列中的时序信息。尽管RNN在每个时间步都会计算新的隐藏状态,但在基础模型中没有涉及多层结构的概念。
⁉️ RNN 在 inference 阶段的解码 (Decoding) 是怎么实现的?
RNN 在 inference 阶段的解码 (Decoding) 是怎么实现的?
在训练好语言模型后,模型不仅可以预测下一个 token,还可以通过将前一个预测的 token 作为输入,连续地预测后续的 token。标准的 RNN 解码过程的步骤可以总结为:
- Warm-up阶段:
- 解码开始时,将输入序列(已知 token )输入到模型中,不输出任何结果。
- 目的是通过传递隐藏状态(hidden state),初始化模型内部状态以适应上下文。
- 续写生成:
- 在输入完前缀后,模型开始生成后续字符。
- 每次生成一个字符,将其作为下一个时间步的输入,依次循环生成目标长度的文本。
- 输入和输出映射:
- 通过输出层预测字符分布,并选择概率最大的字符作为结果。
⁉️ RNN训练时的主要挑战是什么?
RNN训练时的主要挑战是什么?
在训练 循环神经网络(Recurrent Neural Network, RNN) 时,主要面临以下几个挑战:
- 梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient):由于 RNN 依赖于 时间步(time step)上的递归计算,在反向传播(Backpropagation Through Time, BPTT) 时,梯度会随着时间步数的增加不断衰减或增长。如果梯度值指数级减小,会导致模型在长序列上的学习能力受限,难以捕捉远距离依赖(long-range dependencies);如果梯度值指数级增大,则会导致梯度爆炸,使得模型参数更新过大,训练变得不稳定。
- 长期依赖问题(Long-Term Dependency Problem):RNN 通过隐藏状态(hidden state) 传递信息,但当序列较长时,早期输入的信息会逐渐被后续时间步的信息覆盖,导致模型难以捕获远距离的上下文关系。
- 计算效率低(Sequential Computation Bottleneck):RNN 的计算是顺序的(sequential),即当前时间步的计算依赖于前一个时间步的计算结果,因此难以并行化。这使得 RNN 的训练和推理速度远低于 Transformer 这种可以全并行计算的架构。
⁉️ 什么是梯度裁剪(Gradient Clipping)?为什么它被运用在 RNN 训练过程中?
什么是梯度裁剪(Gradient Clipping)?为什么它被运用在 RNN 训练过程中?
梯度裁剪(Gradient Clipping) 是一种用于 防止梯度爆炸(Gradient Explosion) 的技术,主要在训练 循环神经网络(Recurrent Neural Networks, RNNs) 时使用。由于 RNN 需要进行反向传播,当序列较长时,梯度可能会在传播过程中指数级增长,导致 参数更新过大,进而影响模型的稳定性。
梯度裁剪的核心思想是在反向传播时,如果梯度的范数(Norm)超过了某个预设阈值(Threshold),则对梯度进行缩放(Scaling),限制梯度范数不超过一定范围,即:
\[ \mathbf{g} \leftarrow \min\left(1, \frac{\theta}{\|\mathbf{g}\|}\right) \mathbf{g} \]⭐ 经典序列模型(LSTM、GRU、Seq2Seq)
⁉️ LSTM(Long Short-Term Memory)的核心架构和原理是什么?
LSTM 的核心架构和原理是什么?
LSTM(Long Short-Term Memory)相比于传统 RNN 的主要改进在于它引入了 门控机制(Gating Mechanism),有效缓解了 梯度消失(Gradient Vanishing) 和 梯度爆炸(Gradient Explosion) 问题,使得模型能够捕捉长期依赖信息(Long-Term Dependencies)。
LSTM 由 遗忘门(Forget Gate)、输入门(Input Gate) 和 输出门(Output Gate) 组成,每个时间步通过这些门控单元来控制信息的流动。其中,遗忘门 负责决定遗忘多少过去的信息,输入门 控制新信息的写入,输出门 影响隐藏状态(Hidden State)的更新。
\[ \begin{split}\begin{aligned} \mathbf{I}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xi} + \mathbf{H}_{t-1} \mathbf{W}_{hi} + \mathbf{b}_i),\\ \mathbf{F}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xf} + \mathbf{H}_{t-1} \mathbf{W}_{hf} + \mathbf{b}_f),\\ \mathbf{O}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xo} + \mathbf{H}_{t-1} \mathbf{W}_{ho} + \mathbf{b}_o), \end{aligned}\end{split} \]Note: 尽管公式形式类似,LSTM 中的门和一般 RNN 中的 Hidden state 的核心作用完全不同:
- 门的作用是“控制流动”:
- 门本质上是一种控制开关,它的输出必须在 [0, 1] 之间,这样才能直观地表示“通过的信息比例”。所以门的激活函数使用的是 Sigmoid。
- 它们主要用于调节信息的流动,而不是直接参与信息存储。
- Hidden State 的作用是“存储和传递信息”:
- 而 Hidden state 的激活函数使用的是 tanh,其范围为 [-1, 1],更适合表示信息本身的动态特征。
- 它不仅受门控机制影响,还通过非线性变换从记忆单元中提取信息。
此外,LSTM 还维护了一个额外的 细胞状态(Cell State, C_t),用于长期存储信息。它可以被视为截止至当前时刻 t 的综合记忆信息。
新输入数据结合了当前时刻的输入 X 和上一个时间步的 Hidden State,可以被表示为:
\[ \tilde{\mathbf{C}}_t = \textrm{tanh}(\mathbf{X}_t \mathbf{W}_{\textrm{xc}} + \mathbf{H}_{t-1} \mathbf{W}_{\textrm{hc}} + \mathbf{b}_\textrm{c}), \]输入门控制我们在多大程度上考虑新输入数据,而遗忘门则决定了我们保留多少旧的记忆单元内部状态。通过使用Hadamard 积逐元素相乘)运算符,LSTM 的记忆单元内部状态的更新方程为:
\[ \mathbf{C}_t = \mathbf{F}_t \odot \mathbf{C}_{t-1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t \]最后,隐藏状态(Hidden State)定义了记忆单元的输出方式,它由输出门(Output Gate)控制。具体计算步骤如下:首先,对记忆单元的内部状态 应用 tanh 函数,使其值被规范化到 (-1, 1) 区间内。然后,将这一结果与输出门的值逐元素相乘,计算得到隐藏状态:
输出门(Output Gate) 的主要作用是控制 当前时刻的隐藏状态的输出 内容,从而决定 LSTM 的对外信息传递。Cell State 是 LSTM 的内部长期记忆,但它并不直接对外输出。输出门通过选择性地提取 Cell State 中的信息,并结合门控机制生成 新的Hidden State(短期记忆的表达),作为当前时间步的隐藏状态对外输出。这种机制确保 LSTM 在对外传递信息时,不会将 Cell State 中的所有内容暴露出去,避免噪声干扰,同时保留最相关的信息。
⁉️ LSTM 解决的问题和原因?
LSTM解决的问题和原因?
LSTM(Long Short-Term Memory)主要解决了标准RNN在处理长序列时的 梯度消失(vanishing gradients)和梯度爆炸(exploding gradients) 问题。 这些问题导致普通RNN在处理长期依赖(long-term dependencies)时性能较差,无法有效捕获长时间跨度的信息。
- 细胞状态(Cell State)作为长期记忆的载体
- LSTM引入了一个额外的细胞状态,它可以通过直通路径(“constant error carousel”)跨时间步传播信息,几乎不受梯度消失或梯度爆炸的影响。
- 梯度传播更稳定
- 普通RNN的梯度通过时间步传播时,会被反复乘以隐状态的权重矩阵。当权重矩阵的特征值远离 1 时,梯度会出现指数增长(梯度爆炸)或指数衰减(梯度消失)。
- 在LSTM中,细胞状态通过线性加权方式更新(不直接经过激活函数的非线性变换),从而避免了梯度的剧烈变化。门机制确保了信息流动的可控性,进一步减轻了梯度不稳定的问题。
- 更强的记忆能力
- LSTM能同时捕获短期依赖和长期依赖(通过细胞状态)。在长时间序列中,它可以动态调整对不同时间跨度的信息的关注程度,使其既能够记住长期信息,又不会因记忆过多导致模型过载。
⁉️ 解释 GRU(Gated Recurrent Unit)的核心架构和原理?
解释 GRU 的核心架构和原理?
GRU(门控循环单元)是 LSTM记忆单元的简化版本 并保留内部状态和乘法门控机制的核心思想。相比LSTM,GRU在很多任务中可以达到相似的性能,但由于结构更加简单,计算速度更快。
在GRU(Gated Recurrent Unit)中,LSTM的三个门被替换为两个门:重置门(Reset Gate) 和 更新门(Update Gate)。这两个门使用了 Sigmoid 激活函数,输出值限制在区间 [0, 1] 内。
- 重置门:决定了当前状态需要记住多少之前隐藏状态的信息。
- 更新门:控制新状态有多少是继承自旧状态的。
重置门(reset gate)与标准更新机制相结合,生成时间步 t 的 **候选隐藏状态(candidate hidden state),公式如下:
\[ \tilde{\mathbf{H}}_t = \tanh(\mathbf{X}_t \mathbf{W}_{xh} + \left(\mathbf{R}_t \odot \mathbf{H}_{t-1}\right) \mathbf{W}_{hh} + \mathbf{b}_h), \]Note: 重置门主要是对长期记忆进行筛选,在计算候选隐藏状态时,抑制过去隐藏状态中的某些部分,使得模型更多地依赖当前输入。这种机制让模型能够专注于短期依赖,通过结合当前输入产生一个更符合短期记忆的候选状态。
更新门(Update gate)决定了新隐藏状态 在多大程度上保留旧状态与新候选状态的信息。具体而言,控制了二者的加权组合,公式如下:
\[ \mathbf{H}_t = \mathbf{Z}_t \odot \mathbf{H}_{t-1} + (1 - \mathbf{Z}_t) \odot \tilde{\mathbf{H}}_t. \]Note: 更新门(update gate) 则决定 当前时刻的隐藏状态是由之前的隐藏状态(长期记忆)和当前输入(短期信息)以何种比例组合而成。更新门的值接近 1 时,模型保留大部分的长期记忆,接近 0 时则依赖更多的当前输入。这种机制帮助 GRU 捕捉长期依赖关系,因为更新门可以调节模型在序列中如何传递和利用过去的记忆。
⁉️ 什么是深层 RNN(Deep RNNs),它与普通 RNN 有什么区别?
什么是深层 RNN(Deep RNNs),它与普通 RNN 有什么区别?
深层循环神经网络(Deep Recurrent Neural Networks, DRNN)是通过 堆叠多个RNN层 实现的。单隐藏层的RNN网络结构在捕捉时间步内部输入与输出之间复杂关系时存在局限。因此,为了同时增强 模型对时间依赖(temporal dependency) 和 时间步内部输入与输出关系 的建模能力,常会构造在时间方向和输入输出方向上都更深的RNN网络。这种深度的概念类似于在多层感知机(MLP)和深度卷积神经网络(CNN)中见到的层级加深方法。
在深层RNN中,每一时间步的隐藏单元 不仅依赖于同层前一个时间步的隐藏状态,还依赖于 前一层相同时间步的隐藏状态。这种结构使得深层RNN能够 同时捕获长期依赖关系(long-term dependency)和复杂的输入-输出关系。
在深层RNN的第l(l=1,…,L)个隐藏层Hidden state可以表示为:
\[ \mathbf{H}_t^{(l)} = \phi_l(\mathbf{H}_t^{(l-1)} \mathbf{W}_{xh}^{(l)} + \mathbf{H}_{t-1}^{(l)} \mathbf{W}_{hh}^{(l)} + \mathbf{b}_h^{(l)}), \]最后,输出层的计算仅基于第 (l) 个隐藏层最终的隐状态:
\[ \mathbf{O}_t = \mathbf{H}_t^{(L)} \mathbf{W}_{hq} + \mathbf{b}_q, \]⁉️ 什么是双向循环神经网络(BiRNN)?为什么在某些任务中它的的效果优于RNN?
什么是双向循环神经网络(BiRNN)?为什么在某些任务中它的的效果优于RNN?
双向循环神经网络(Bidirectional Recurrent Neural Network, BiRNN)是一种扩展传统循环神经网络(Recurrent Neural Network, RNN) 的方法。与单向 RNN 仅从过去到未来处理序列数据不同,BiRNN 在每个时间步(Timestep)中同时计算两个方向的信息流:一个从前向后(Forward Direction),另一个从后向前(Backward Direction)。这种结构通过两个独立的隐藏层(Hidden Layers)分别处理时间序列的正向和反向信息,并在输出层(Output Layer)结合这两个隐藏状态(Hidden States),从而获得更丰富的上下文信息。前向和反向隐状态的更新如下:
\[ \begin{split}\begin{aligned} \overrightarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(f)} + \overrightarrow{\mathbf{H}}_{t-1} \mathbf{W}_{hh}^{(f)} + \mathbf{b}_h^{(f)}),\\ \overleftarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(b)} + \overleftarrow{\mathbf{H}}_{t+1} \mathbf{W}_{hh}^{(b)} + \mathbf{b}_h^{(b)}), \end{aligned}\end{split} \]接下来,将前向隐状态和反向隐状态连接起来,获得需要送入输出层的隐状态。在具有多个隐藏层的深度双向循环神经网络中,该信息作为输入传递到下一个双向层。
\[ \mathbf{H}_t = \begin{bmatrix} \overrightarrow{\mathbf{H}}_t \\ \overleftarrow{\mathbf{H}}_t \end{bmatrix} \]最后,输出层计算得到的输出为:
\[ \mathbf{O}_t = \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_q. \]在某些任务中,BiRNN 的效果优于单向 RNN,主要是因为它能够利用未来和过去的信息,而不仅仅依赖于当前时间步之前的历史数据。BiRNN 适用于 需要充分利用上下文信息的序列任务,特别是在 NLP 领域。具体来说,文本分类(Text Classification)、情感分析(Sentiment Analysis)、语音识别(Automatic Speech Recognition, ASR)等任务都可以从 BiRNN 的双向信息流中获益。
⁉️ 什么是 Encoder-Decoder 结构?它是如何工作的?
什么是 Encoder-Decoder 结构?它是如何工作的?
在序列到序列(sequence-to-sequence)问题中(如机器翻译),输入和输出通常具有不同的长度,且无法直接对齐。为了解决这一问题,通常采用编码器-解码器(encoder-decoder)架构。这个架构包括两个主要组件:
编码器(Encoder)的作用是处理输入序列并将其转化为一个固定大小的表示(通常是一个向量,也叫做上下文向量(Context Vector))。在传统的 RNN(Recurrent Neural Network)或 LSTM(Long Short-Term Memory)网络中,编码器逐步读取输入序列的每个元素(如单词或字符),并通过递归地更新其隐藏状态(Hidden State)来捕捉输入的语义信息。最终,编码器输出的隐藏状态或最后一个时间步的隐藏状态(在一些变体中是所有时间步的隐藏状态)作为对输入序列的总结。
解码器(Decoder)则是基于编码器的输出生成目标序列。解码器通常也是一个RNN或LSTM,它的工作方式是逐步预测输出序列中的每个元素。解码器首先接受编码器生成的上下文向量作为初始的隐藏状态,然后在生成每个目标词时,它根据当前隐藏状态以及之前生成的输出(或在训练时,使用教师强迫(Teacher Forcing),即真实的标签作为输入)来预测下一个词。这个过程一直持续到生成完整的目标序列。
⁉️ 什么是 seq2seq 模型?
什么是 seq2seq 模型?
序列到序列(Sequence-to-Sequence, Seq2Seq)模型是一种用于处理输入序列(Input Sequence)到输出序列(Output Sequence)转换的深度学习架构(输入和输出都是变长的、未对齐的序列)。Seq2Seq 模型的核心结构是 编码器-解码器(Encoder-Decoder)架构,其中编码器(Encoder)的主要作用是将一个 长度可变的输入序列 转换为 固定形状的上下文变量(context variable)。这一过程可表示为:
\[ \mathbf{h}_t = f(\mathbf{x}_t, \mathbf{h}_{t-1}). \]Encoder 会利用自定义的函数 g 将所有时间步的隐藏状态转换为一个固定形状的上下文变量:
\[ \mathbf{c} = q(\mathbf{h}_1, \ldots, \mathbf{h}_T). \]Note: Encoder 的设计目的:
- 压缩输入信息:将输入序列的所有信息压缩到一个低维表示中,确保模型能够以固定大小的特征表示处理任意长度的输入。
- 捕捉序列的全局语义: Encoder 会通过递归网络(如 RNN、GRU 或 LSTM)处理输入序列,将序列中的时序依赖关系和语义信息编码到隐藏状态中。
- 作为中间表示: Encoder 的输出(隐藏状态或上下文变量)提供了一种抽象的、高效的输入表示,适合传递给其他模块(如 Decoder)或用于分类、翻译等下游任务。
解码器(decoder)负责根据目标输出序列,在每个时间步 t 预测下一步的输出。解码器的核心是基于目标序列中前一时间步的输出、前一时间步的隐藏状态和上下文变量来计算当前时间步的隐藏状态。公式如下:
\[ \mathbf{s}_{t} = g(y_{t}, \mathbf{c}, \mathbf{s}_{t}). \]在得到当前时间步的隐藏状态 (\mathbf{s}_t) 后,通过输出层和 softmax 操作计算下一步的输出 (y_t) 的概率分布:
\[ P(y_{t} \mid y_1, \ldots, y_{t}, \mathbf{c}) \]Note: 在 seq2seq 中,特定的
<eos>表示序列结束词元。 一旦输出序列生成此词元,模型就会停止预测。在设计中,通常有两个特别的设计决策:首先,每个输入序列开始时都会有一个特殊的序列开始标记(<bos>),它是解码器的输入序列的第一个词元;其次,使用循环神经网络编码器 最终的隐状态来初始化解码器的隐状态。
⁉️ 为什么解码器在训练时需要强制教学(teacher forcing)?
为什么解码器在训练时需要强制教学(teacher forcing)?
强制教学(Teacher Forcing) 是一种用于 序列到序列(Seq2Seq) 任务的训练技巧,主要应用于 递归神经网络(RNN) 及其变体。在标准的 Seq2Seq 训练过程中,解码器(Decoder)需要根据之前的输出逐步预测下一个单词,而 强制教学(Teacher Forcing) 的核心思想是在训练时,不使用解码器自身的预测结果作为下一步的输入,而是直接使用真实的目标序列(Ground Truth)作为输入,从而减少误差的累积。
在这种方法中,解码器的 输入使用的是目标序列 (target sequence) 的原始标签。具体来说,解码器的输入由特殊的起始标记 <bos> 和目标序列(去掉最后一个标记)拼接而成,而解码器的输出(用于训练的标签)是原始目标序列 向右偏移一个标记。例如:
- 输入:
<bos>, “Ils”, “regardent”, “.” - 输出: “Ils”, “regardent”, “.”,
<eos>
解码器在训练时需要 强制教学(Teacher Forcing),主要是为了 加速收敛并稳定训练过程。在没有 强制教学(Teacher Forcing) 的情况下,如果解码器的某一步预测错误,那么错误的输出会被作为下一步的输入,这可能导致错误被进一步放大,从而使整个序列的预测质量下降。通过使用真实目标序列作为输入,解码器可以更快学习到正确的模式,并减少梯度传播中的误差累积问题。
相比之下,编码器(Encoder) 并不需要 强制教学(Teacher Forcing),因为编码器的作用是将整个输入序列编码成一个固定长度的隐状态(Hidden State),然后传递给解码器。编码器的输入是完整的源语言序列,因此它的计算不涉及前一步的预测误差传播。
⁉️ 在解码阶段如何进行 Greedy Search 和 Beam Search?两者的优缺点是什么?
在解码阶段如何进行 Greedy Search 和 Beam Search?两者的优缺点是什么?
Greedy Search 是一种简单但次优的解码方法,每一步都选择当前概率最高的词作为输出,而不考虑全局最优。例如,在翻译任务中,若模型预测 “I love deep learning” 时,Greedy Search 可能会选择最高概率的词 “love” 作为第二个词,而不会评估其他可能的组合。这种方法的优势是计算速度快、实现简单,但容易陷入局部最优(Local Optimum),导致整体生成结果质量不佳。
Beam Search 是 Greedy Search 的改进方法,它在解码过程中维护 K(Beam Width) 个最优候选序列,而不是仅选择概率最高的词。例如,若 K=3,模型会同时跟踪三个最可能的翻译路径,在每个时间步计算所有可能扩展的概率,并仅保留 K 个最高概率的候选路径。Beam Search 能有效避免局部最优,并提高序列生成质量。然而,它的计算复杂度较高,较大的 K 值会显著增加计算量。此外,Beam Search 仍然无法保证找到全局最优解,并且可能导致重复生成(Repetitive Generation)的问题。
在实际应用中,Greedy Search 适用于低计算资源的环境,如实时应用(Real-time Applications),而 Beam Search 在机器翻译(Machine Translation)、文本摘要(Text Summarization)等任务中更常见,以提高生成文本的连贯性和流畅性。
⁉️ 如何使用 BLEU 进行预测序列的评估 ?
如何使用 BLEU 进行预测序列的评估 ?
在自然语言生成任务(Natural Language Generation, NLG)中,预测序列的评估通常使用自动化指标来衡量 生成文本与参考文本(Ground Truth)之间的相似度,其中 BLEU(Bilingual Evaluation Understudy) 是最常用的指标之一。BLEU 主要用于机器翻译(Machine Translation, MT)等任务,通过计算 n-gram 之间的匹配度来评估生成文本的质量。
BLEU 的核心思想是计算 预测文本(Hypothesis) 和 参考文本(Reference) 之间的 n-gram 精确匹配率(n-gram Precision),并结合 惩罚因子(Brevity Penalty, BP) 以防止模型生成过短的句子。其计算过程如下:
\[ \exp\left(\min\left(0, 1 - \frac{\mathrm{len}_{\text{label}}}{\mathrm{len}_{\text{pred}}}\right)\right) \prod_{n=1}^k p_n^{1/2^n},\]- n-gram 精确匹配(n-gram Precision): 计算预测文本中的 1-gram, 2-gram, 3-gram, 4-gram 等短语,在参考文本中是否出现,并计算匹配比例。
- 惩罚因子(Brevity Penalty, BP): 当预测文本过短(即比参考文本短)时,BLEU 会施加惩罚,避免通过只生成短而匹配的文本来提高得分。
BLEU 的优点是计算简单,适用于大规模评测,并且与人类评分有一定相关性。然而,它的缺点是 缺乏语义理解(Semantic Understanding),无法衡量文本的可读性和流畅性。
✅ 强化学习(Monte Carlo,TD,Policy Gradient)
⁉️ 什么是在线学习(Online-Learning)和离线学习(Offline-Learning)?有什么区别?
什么是在线学习(Online-Learning)和离线学习(Offline-Learning)?有什么区别?
在线学习(Online Learning) 是一种机器学习(Machine Learning)范式,其中模型在数据流(Data Stream)到达时逐步更新,而无需存储所有历史数据。常见的在线学习算法包括随机梯度下降(Stochastic Gradient Descent, SGD)、在线感知机(Online Perceptron)。强化学习就是一种在线学习(Online Learning)的一种方式。
相比之下,离线学习(Offline Learning) 是一种批量学习(Batch Learning)方式,即模型在训练阶段获取固定的数据集(Fixed Dataset),进行训练和优化后再进行推理(Inference)。常见的离线学习方法包括传统的监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning)等。
两者的主要区别在于数据获取方式和模型更新方式:在线学习在数据流到达时进行增量更新(Incremental Update),而离线学习基于 静态数据集进行一次性训练(One-time Training)。在线学习通常适用于需要实时适应新数据的场景,而离线学习适用于数据相对稳定、不需要频繁更新的任务。
⁉️ 什么是强化学习?有哪些基础组建和公式?
什么是强化学习?有哪些基础组建和公式?
强化学习(Reinforcement Learning, RL) 是一种机器学习(Machine Learning, ML)方法,旨在通过智能体(Agent)与环境(Environment)的交互,使智能体在不断试探和学习的过程中最大化累积奖励(Cumulative Reward)。强化学习的核心思想是通过试错(Trial-and-Error)和奖励机制(Reward Mechanism)来优化决策策略(Policy)。强化学习的基本组成部分包括:
- 状态(State, s ):描述环境在某一时刻的特征信息,通常表示为 s_t 。一般有离散状态(Discrete State)和 连续状态(Continuous State)
- 动作(Action, a ):智能体在给定状态 s_t 下可以执行的操作,表示为 a_t 。
- 奖励(Reward, r ):智能体执行动作后环境给予的反馈信号,记为 r_t ,用于衡量该动作的好坏。
- 策略(Policy, pi ):决定智能体在某一状态下如何选择动作的规则,通常表示为 pi(a | s) ,可以是确定性(Deterministic)或随机性(Stochastic)的。
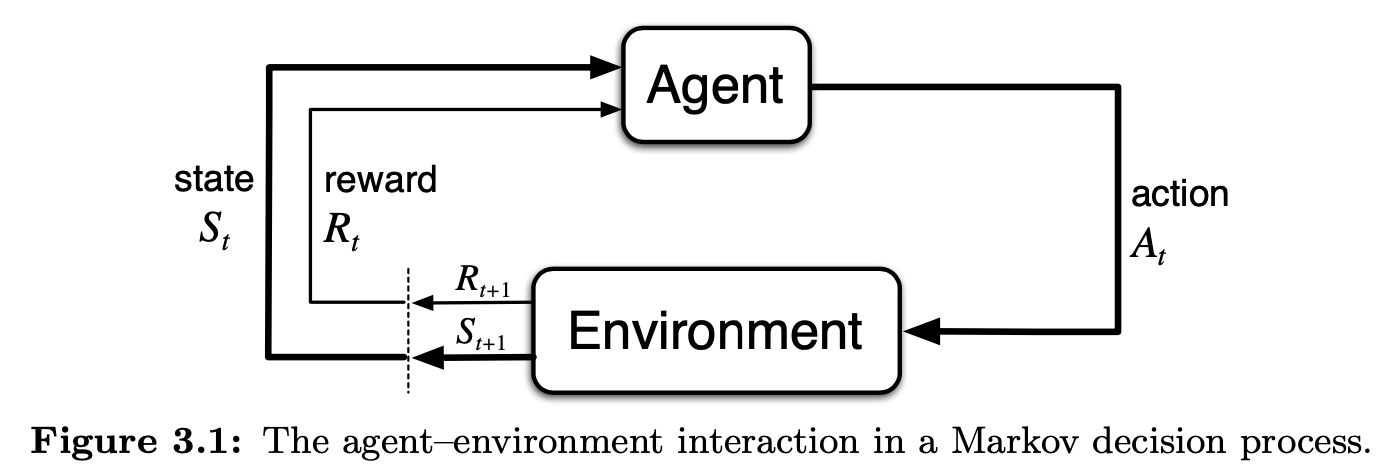
- 环境(The Environment) 在强化学习(Reinforcement Learning, RL)中指的是智能体(Agent)与之交互的外部系统,它决定了在某个状态(State, s)下,当智能体选择某个动作(Action, a)后,环境如何转移到下一个状态(Next State, s’)并返回相应的奖励(Reward, r)。即在当前状态 s 下,采取动作 a,会转移到不同的 s’ 并获得不同的奖励 r 的所有可能的 (s’, r) 组合的概率分布。
- 策略(Policy, pi) 是强化学习中的核心概念,它定义了智能体在每个状态下选择各个可能动作的概率分布,即在状态 s 下,智能体选择动作 a 的概率。
- 离散动作空间(Discrete Action Space) policy 通常是一个二维矩阵:每一行是一个状态,每一列是一个可能的动作,对应的值是执行该动作的概率。对于确定性策略(deterministic policy),每个状态只对应一个固定的动作,矩阵的每一行只有一个 1,其余是 0。对于随机策略(stochastic policy),矩阵的每一行是一个概率分布,所有值的和等于 1。
- 连续动作空间(Continuous Action Space) policy 通常是一个 神经网络参数化的函数,它输入状态 s ,输出一个连续动作的分布参数。对于确定性策略:直接输出一个动作值。对于随机策略:输出高斯分布的参数,然后采样。
- 回报 是智能体从时间步 t 开始累积的折扣奖励之和,其中,gamma 控制智能体对未来奖励的重视程度,当 gamma->0 时,智能体更关注即时奖励(Myopic behavior);当 gamma->1 时,智能体更关注长期回报(Far-sighted behavior)。
- 状态值函数 表示在策略 pi 下,智能体从状态 s 开始执行策略 pi 所能获得的期望回报(即确定状态 s 计算根据 策略 pi 执行 不同动作 a 获得的收益的合)。根据 贝尔曼方程(Bellman Equation),它可以递归表示为:
- 动作值函数 表示在策略 pi 下,智能体在状态 s 执行动作 a 后,接下来按照策略 pi 选择动作所能获得的期望回报。(即确定状态 s 和 执行动作 a 计算根据 策略 pi 执行获得的收益的合):
⁉️ 什么是动态规划(DP)?
什么是动态规划(DP)?
动态规划主要用于求解有限马尔可夫决策过程(Finite Markov Decision Process, MDP),假设状态空间 S、动作空间 A 和奖励 R 是有限的,并且环境的动态是由状态转移概率 p(s’,r|s,a) 决定的。DP 依赖环境的转移模型 p(s’,r|s,a) 来解决预测问题(Prediction Problem),计算策略 pi 下的状态值函数和动作值函数。在获得值函数后,可以改进策略,使其向最优策略收敛。
Note:现实世界中,通常无法直接获得状态转移概率 p(s’,r|s,a),LLM环境(文本生成)通常未知且复杂。并且对于大规模 MDP(如 Atari 游戏或机器人控制),DP 方法计算成本过高,难以直接应用。
策略迭代(Policy Iteration)
- 策略评估 的目标是给定策略 pi ,计算其对应的值函数( v_{pi} 或 q_{pi} )。通常采用 贝尔曼方程(Bellman Equation) 进行迭代更新,直至收敛到固定点。
- 策略改进(Policy Improvement) 是指根据当前的值函数 v_{pi} 或 q_{pi} 生成更优的策略:
- 策略迭代交替执行 策略评估 和 策略改进,直到策略稳定:
- 策略评估: 计算当前策略 pi_k 的状态值函数 V_{pi_k}(s) 。
- 策略改进: 依据 V_{pi_k}(s) 选择新的策略,使其期望回报最大化。
- 迭代至收敛: 直到新策略与旧策略相同,即达到最优策略。
Note:广义策略迭代(Generalized Policy Iteration, GPI) 是指策略评估(Policy Evaluation)和策略改进(Policy Improvement)过程相互作用的一个通用思想。如果评估过程和改进过程都稳定,即不再产生变化,那么值函数和策略就必定是最优的。
- 策略评估(Policy Evaluation,也称为预测,Prediction):给定一个策略 pi ,通过计算得到其关联的值函数(即 v_{pi} 或 q_{pi}(s, a) )。
- 策略改进(Policy Improvement):给定一个策略 pi_k,根据 pi_k 的值函数合成一个新的策略 \pi_{k+1} ,使得新的策略的值函数优于旧的策略值函数。

价值迭代(Value Iteration)
价值迭代通过直接迭代贝尔曼最优方程来求解最优值函数:
\[ v_{k+1}(s) = \max_a \sum_{s^{\prime},r} p(s^{\prime},r|s,a) [r + \gamma v_k(s^{\prime})] \]不同于策略迭代,价值迭代在每次迭代中仅进行一次 Bellman 备份,并直接更新值函数,而不是执行完整的策略评估过程。

Note:假设我们有一个网格世界(Grid World),机器人可以选择 上、下、左、右 四个动作。目标是从起点到终点,并最大化奖励。
- 价值迭代 会先计算每个状态的最优值,然后得到最优策略。
- 我们先初始化所有状态的值为 0,除了终点格子(G),它的值为 0,因为到达终点后没有更多的奖励。
- 每一轮迭代,我们都会检查每个状态,并用其邻近状态的值来更新当前状态的值。不断地进行迭代,直到所有状态的值函数不再改变为止。最终,值函数的更新会导致 每个状态的最优值函数。
- 我们可以根据值函数来提取最优策略。对于每个状态,选择带来最大值的动作。
- 策略迭代 先随机初始化策略,然后不断改进,直到得到最优策略。
- 随机初始化策略,我们首先为每个状态随机选择一个动作。
- 我们通过策略评估来计算在当前策略下的每个状态的值函数。使用贝尔曼方程进行计算,但这次是基于当前策略来计算每个状态的期望值。
- 通过计算值函数后,我们可以更新当前策略,选择在每个状态下使得值函数最大的动作。例如,对于 (0, 0),我们计算四个可能的动作的期望值,选择能带来最大值的动作。
- 一旦策略改进后,我们再进行策略评估,计算更新后的值函数,然后继续进行策略改进。这个过程会一直进行,直到策略不再变化为止。
⁉️ 什么是蒙特卡洛方法(Monte Carlo Methods)?它和 DP 有什么不同?
什么是蒙特卡洛方法(Monte Carlo Methods)?它和 DP 有什么不同?
蒙特卡洛方法(Monte Carlo Methods) 是一类通过随机采样来估计问题解的方法。在强化学习(Reinforcement Learning)中,蒙特卡洛方法用于通过 直接从环境中获取一系列的回报(rewards)来估计状态值(state value)或动作值(action value)。这意味着蒙特卡洛方法是基于 完整的回合(episode) 来更新状态或动作的价值。具体而言,它通过多个回合的样本估计每个状态或状态-动作对的期望回报,并通过这些样本平均值来更新价值函数(value function)。
与动态规划(Dynamic Programming, DP)不同,蒙特卡洛方法不需要环境的完整模型(模型自由),只要求环境满足马尔可夫性质(Markov Property),即状态由当前状态决定,而不依赖历史状态。动态规划方法依赖于环境的完整状态转移模型和奖励函数,通过贝尔曼方程(Bellman Equation)递归地更新状态值函数。在DP中,所有的状态转移和奖励都被精确计算,因此DP方法需要对整个状态空间进行遍历,通常需要环境的完全知识,并且不涉及探索(exploration)。相比之下,蒙特卡洛方法通过实际的交互数据,逐步估计期望回报,适用于未知或不完全模型的情况。蒙特卡洛方法中,探索至关重要,因为它依赖采样来估计值函数,具体来说:
- 需要充分探索状态-动作空间( S x A )以确保 Q 值的完备性。
- 可以使用探索起点(Exploring Starts, ES)在模拟环境中遍历所有可能的状态-动作对,以获得完整的信息。
- 在真实环境中,探索必须由策略(policy)来实现,以确保广义策略迭代(Generalized Policy Iteration, GPI)能够产生高质量的值函数近似。
在环境完全已知的情况下,状态值函数 V(s) 或动作值函数 Q(s,a) 可以直接被计算。而蒙特卡洛方法的基本思想是 通过多次采样来估计 V(s) 或 Q(s, a) ,然后 求取期望值 来近似这些值函数。
蒙特卡洛预测(Monte Carlo Prediction) #
蒙特卡洛方法用于策略评估(policy evaluation),即在给定策略 pi 的情况下,估计状态值函数 V(s) 或动作值函数 Q(s, a) 。
- 首次访问蒙特卡洛(First-Visit MC) 在一次完整回合(episode)中,假设访问了多个状态-动作对 (s, a),First-Visit MC 方法只在 该状态首次出现时 计算其回报,并用它来更新状态值或动作值。

Note:虽然我们是从某个特定的起点 S_x 出发执行 episode,但 Monte Carlo 方法更新的是所有首次访问到的状态 S_t 或状态-动作对 (S_t, A_t) 的回报信息,而不仅仅是起点的值函数。我们会 先采样一整个 episode,然后 倒着回溯计算回报并更新状态价值。最终,通过多次 episode 的更新,状态价值 V(S) 会逼近真实的期望回报。
- 每次访问蒙特卡洛(Every-Visit MC) 每次访问状态 S_t = s 都计算回报,求取均值。两者的主要区别在于,首次访问方法仅使用每个回合中对某状态的第一次访问,而每次访问方法会使用所有访问。
Example:假设我们有如下回合:(S_0, A_0), (S_1, A_1), (S_2, A_2), (S_1, A_3), (S_3, A_4)
- 如果 使用 First-Visit MC:
- 只在 S_1 第一次访问(即 S_1, A_1 )时计算回报
- 忽略 S_1, A_3 处的计算
- 这与 Every-Visit MC(每次访问 MC) 不同,后者会在 每次访问 时都计算回报并更新值函数。
- 如果 使用 First-Visit MC:
如何确保蒙特卡洛方法覆盖所有状态-动作对?
- 探索起点(Exploring Starts)
- 指定回合从特定状态-动作对开始,确保每个对都有非零概率被选中。
- 但在实际环境中难以实现,仅适用于可控制的模拟环境。
- 随机策略(Stochastic Policy)
- 规定策略必须为随机策略。
- ε-贪心策略(ε-Greedy Policy) 确保所有动作都有非零概率被选择。
- 探索起点(Exploring Starts)
蒙特卡洛控制(Monte Carlo Control) #
蒙特卡洛控制旨在找到最优策略 pi^* 以最大化累积回报。其核心是 广义策略迭代(Generalized Policy Iteration, GPI),即:
- 策略评估(Policy Evaluation):使用蒙特卡洛方法估计 Q(s, a)
- 策略改进(Policy Improvement):根据 Q(s, a) 更新策略 pi
探索问题(Exploration)
由于蒙特卡洛方法基于采样,因此需要确保所有状态-动作对都有非零概率被访问,否则 Q(s, a) 可能无法收敛。因此需要 探索(exploration),常见策略有:
- 探索起点(Exploring Starts):强制所有状态-动作对都能被访问(通常在模拟环境中使用)
- ϵ-贪心策略(ϵ-greedy policy):
该策略 大部分时间 选择当前最优动作 argmax Q(s,a) ,但以概率 epsilon 随机选择任意动作,从而确保足够的探索。
基于策略的蒙特卡洛控制(On-Policy MC Control)
On-policy 方法在学习过程中 直接使用当前策略(behavior policy) 生成的数据来更新该策略本身(target policy)。典型的 on-policy 方法是 SARSA(State-Action-Reward-State-Action),它根据当前策略选择的动作来估计 Q 值(Action-value function),并用该策略的更新规则进行优化。这种方法的主要限制是 它只能优化自己采样到的数据,不能利用历史数据或其他策略生成的数据。

离策略蒙特卡洛控制(Off-Policy MC Control)
Off-policy 方法在学习过程中 使用一个不同的行为策略(behavior policy)来生成数据,但 优化的是另一个目标策略(target policy)。使用历史经验或其他探索策略(如 ε-greedy)生成的数据进行学习,而目标策略则是贪心策略(greedy policy)。这种方法的一个重要特性是可以利用过去的经验数据(replay buffer),并能有效学习最优策略。

其中 W (Weight)是累积重要性权重,C(s, a) 是累积重要性采样因子。
Note:在强化学习(Reinforcement Learning, RL)中,我们需要off-policy方法(Off-Policy Methods)的主要原因在于评估(Evaluation, Eval)和广义策略迭代(Generalized Policy Iteration, GPI)之间存在一个 根本性的冲突(Fundamental Conflict)。
具体来说,Eval 的目标是估计状态-动作值函数 Q(s, a) ,从而使得策略改进(Improvement, Impr) 可以利用 Q 来合成一个更优的策略。而 GPI 的目标是找到最优策略 pi^* ,并为此交替执行 Eval 和 Impr。然而,这两个过程在策略选择上存在矛盾:
- Eval 需要进行 充分的探索(Exploration),即需要采样整个状态-动作空间,以确保 Q(s, a) 的估计是充分的。这意味着 需要执行一些次优的动作(Suboptimal Actions)。
- Impr 需要 趋向最优(Greedy),即在给定的 Q(s, a) 估计下,始终选择当前最优动作,以最大化累积回报。
然而,在on-policy方法(如 SARSA)中,Eval 和 Impr 共享同一策略 pi ,导致 Eval 过程中无法进行足够的探索,因为 Impr 迫使策略趋向最优。这种情况下, Q(s, a) 可能会由于采样不足而估计不准确,从而影响最终策略的优化。
Off-policy方法通过 分离行为策略(Behavior Policy, b)和目标策略(Target Policy, π) 来解决这一冲突。即:
- 行为策略 b 负责生成经验样本,它可以是一个更具探索性的策略。
- 目标策略 π 由 GPI 进行优化,以收敛到最优策略。
通过使用 重要性采样(Importance Sampling) 等技术,我们可以从行为策略 b 采样的数据中,估计目标策略 π 的值函数 Q^π(s, a) ,从而保证 Eval 过程的充分探索,同时不影响 Impr 过程的最优性。
⁉️ 解释 Temporal-Difference Learning(时序差分学习)?什么是 SARSA 和 Q-Learning?
解释 Temporal-Difference Learning(时序差分学习)?什么是 SARSA 和 Q-Learning?
TD学习(Temporal-Difference Learning) 结合了 Monte Carlo(MC)方法 和 动态规划(Dynamic Programming, DP) 的思想。与MC方法类似,TD学习可以直接从原始经验中学习,而不需要环境的动态模型。与DP类似,TD学习基于当前的估计值进行更新(bootstrap),而不必等到最终结果。
MC方法依赖完整的轨迹(episode),在一些情况下存在以下问题:
- 可能违反实时性要求,必须等到整个episode结束才能进行更新。
- 假设环境是 stationary(平稳的),但现实中的环境往往是 non-stationary(非平稳的)。
为了解决非平稳环境的问题,使用 增量更新公式:
\[ Q(S_{t},A_{t}) \leftarrow Q(S_{t},A_{t}) + \alpha(G_{t}-Q(S_{t},A_{t})) \]进一步,为了消除对episode的依赖,TD方法采用以下更新方式:
\[ Q(S_{t},A_{t}) \leftarrow Q(S_{t},A_{t}) + \alpha(R_{t+1}+\gamma Q(S_{t+1},A_{t+1})-Q(S_{t},A_{t})) \]TD 预测(TD Prediction) #
在 MC方法 中,每个状态值的更新公式为:
\[ V(S_{t})\leftarrow V(S_{t})+\alpha[G_{t}-V(S_{t})] \]而 TD(0)方法 采用 一步TD更新(one-step TD update):
\[ V(S_{t})\leftarrow V(S_{t})+\alpha[R_{t+1}+\gamma V(S_{t+1})-V(S_{t})] \]
Note:TD方法的优势:
- 对比DP:TD不需要环境的动态模型(model-free)。
- 对比MC:TD可以 在线增量更新(online incremental learning),不必等待episode结束。适用于长episode或 无终止任务(continuing tasks)。
Bootstrap(自举) #
TD方法采用 bootstrap 技术,即利用当前已有的估计值来更新估计:
\[ V(S_{t})\leftarrow V(S_{t})+\alpha[R_{t+1}+\gamma V(S_{t+1})-V(S_{t})] \]- 在DP中,我们用 V_π(S_{t+1}) 近似 v_π(S_{t+1}) 。
- 在MC中,我们用奖励的样本均值来近似期望回报。
- 在TD(0)中,我们用 下一状态的价值估计值 来近似期望回报。
TD 控制(TD Control) #
SARSA(On-policy TD Control) #

- 策略(policy) 使用 epsilon-greedy 策略,探索-利用权衡:
- 需要 行为多样性(behavioral diversity):pi 不能完全贪心(greedy)。
- 需要 最终收敛到最优策略:pi 需要逐渐变得贪心,epsilon 随时间减小,例如 epsilon = 1/t。
Q-Learning(Off-policy TD Control) #

- SARSA是 on-policy,跟随当前策略选择下一步动作。
- Q-Learning是 off-policy,使用 最优动作 来更新Q值。
Note:为什么Q-Learning是off-policy?
- 学到的Q值直接逼近最优值 q^* ,与实际执行的策略无关。
- 策略的作用仅在于 采样足够的状态-动作对,以确保Q值收敛。
⁉️ 什么是函数逼近(Function Approximation)?强化学习中为什么需要函数逼近?
什么是函数逼近(Function Approximation)?强化学习中为什么需要函数逼近?
函数逼近(Function Approximation)是指使用参数化函数(Parameterized Function)来近似一个未知的目标函数 f ,以便在给定输入 x 时,能够预测输出 f^(x) \approx f(x) 。在强化学习(Reinforcement Learning, RL)中,函数逼近的主要作用是用于 估计价值函数(Value Function)或策略函数(Policy Function),特别是在状态空间(State Space)和动作空间(Action Space)非常大的情况下。
在传统的表格方法(Tabular Methods)中,我们通常使用查找表(Lookup Table)存储每个状态-动作对(State-Action Pair)的值。然而,查找表的大小是 |S| x |A| (其中 |S| 是状态空间的大小, |A| 是动作空间的大小),当状态空间或动作空间增大时,查找表的存储需求会迅速变得不可行。例如,在象棋或围棋等复杂环境下,状态数量远远超过了计算机可以存储的规模。因此,函数逼近被引入以用更紧凑的参数化模型来表示价值函数或策略函数,使得强化学习能够扩展到更大、更复杂的问题。 在强化学习(Reinforcement Learning, RL)中,函数逼近有以下几种常见形式:
- 表格存储(Tables of values):适用于小规模问题,但无法扩展。
- 解析表达式(Analytic Expressions):如果存在解析解,通常可使用传统方法(如控制理论或经典计算方法)而非 RL。
- 参数化函数(Parameterized Functions):利用梯度下降(Gradient Descent)等优化方法进行调优,更具泛化能力。
参数化函数的选择 #
强化学习中最常见的函数逼近方法包括:
- 线性逼近(Linear Approximation):
其中 w 和 b 是需要学习的参数。
- 非线性逼近(Nonlinear Approximation):
- 使用特征映射(Feature Mapping) \phi(x) 进行多项式回归(Polynomial Regression)。
- 使用神经网络(Neural Networks),在线性模型基础上添加非线性激活函数(Nonlinear Activation Function):
其中 \sigma 是激活函数,如 ReLU 或 Sigmoid。
函数逼近(Function Approximation)在强化学习中的预测与控制 #
Note:什么是半梯度方法(Semi-Gradient Methods)?
半梯度方法(Semi-Gradient Methods) 是一种在强化学习中用于函数逼近的优化方法。它与标准梯度下降(Gradient Descent)不同之处在于 它只计算了损失函数关于参数的 部分梯度,而没有完全遵循梯度下降的原则。标准的梯度下降方法会计算 损失函数对参数 w 的完整梯度:
\[ w \leftarrow w - \alpha \nabla_w L(w) \]真实回报 G_t 在蒙特卡洛方法(Monte Carlo, MC)中是完整的(无偏估计),但 MC 方法需要等待整个 episode 结束才能更新参数。TD 方法使用了引导目标(Bootstrapped Target) R_t + \gamma V(S_{t+1}) ,其中的 V(S_{t+1}) 也是由当前参数 w 计算出来的,这就导致了 目标本身也依赖于参数 w。具体来说,TD 目标是:
\[ v_{\text{ref}} = R_t + \gamma \hat{v}(S_{t+1}, w) \]那么真正的梯度应该是:
\[ L(w) = \frac{1}{2} (v_{\text{ref}} - \hat{v}(S_t, w))^2 \] \[ \nabla_w L(w) = \nabla_w \left[ \frac{1}{2} (v_{\text{ref}} - \hat{v}(S_t, w))^2 \right]= (v_{\text{ref}} - \hat{v}(S_t, w)) \cdot \nabla_w \left[ v_{\text{ref}} - \hat{v}(S_t, w) \right] \]然而,在 半梯度方法(Semi-Gradient Methods) 中,我们 不会对目标 v_{ref} 求导,而是只对 当前估计值 \hat{v}(S_t, w) 求导。
\[ \nabla_w L(w) \approx -(v_{\text{ref}} - \hat{v}(S_t, w)) \nabla_w \hat{v}(S_t, w) \] \[ w \leftarrow w - \alpha \nabla_w L(w) \]这个更新公式没有对 v_{ref} 求导,而 v_{ref} 依赖于 w ,因此它并不是完整的梯度,而是一个“半”梯度(Semi-Gradient)。
尽管半梯度方法不是严格的梯度下降方法,但它们仍然有重要价值:
- 在许多情况下稳定收敛(Convergence in Important Cases)
- 使得学习速度显著加快
- 允许持续在线学习(Continual and Online Learning),无需等待完整的回合结束


Note:TD(n) 主要用于更新 V(s)(状态值函数),TD(n) 适用于策略评估,用于估计值函数 V(s) (但也可以扩展到 Q 学习)。SARSA 是 TD 方法的一种,SARSA 更新 Q(s, a) (动作值函数),SARSA 适用于策略控制(而不仅仅是评估)。**

⁉️ 什么是策略梯度(Policy Gradient)?它有哪些优势?
什么是策略梯度(Policy Gradient)?它有哪些优势?
策略梯度方法(Policy Gradient)是通过直接学习一个参数化的策略(Policy),来选择行动而不需要依赖价值函数(Value Function)。虽然可以利用价值函数来学习策略参数,但它并不是进行行动选择的必要条件。我们用以下公式表示策略的概率:
\[ \pi(a|s, \theta) = P(A_t = a | S_t = s, \theta_t = \theta) \]策略梯度方法的核心思想很简单:我们将策略表示为一个可调函数,并调整该函数的参数来优化某些指标,使得调整后的策略能够表现出所需的能力(即优化的性能)。我们使用梯度下降方法(Gradient Descent),因此,策略的函数近似的梯度,即策略梯度(Policy Gradient),成为我们关注的对象,它是策略函数调整的基础。
我们基于某个标量性能度量 J(\theta) 关于策略参数的梯度来学习策略参数。这些方法的目标是最大化性能,因此它们的更新近似于在 J 上进行梯度上升(Gradient Ascent):
\[ \theta_{t+1} = \theta_t + \alpha \nabla \hat{J}(\theta_t) \]策略可以采用任何可微分的方式进行参数化,以确保能够进行梯度计算。如果动作空间(Action Space)是离散的且较小,常见的方法是使用软最大(Softmax)策略进行参数化:
\[ \pi(a | s, \theta) = \frac{e^{h(s, a, \theta)}}{\sum_{b} e^{h(s, b, \theta)}} \]Note:策略梯度方法的优势:
现实中的优势
- 通过软最大策略参数化,策略可以逐渐接近确定性策略(Deterministic Policy)。
- 允许对动作进行非均匀概率选择,而不仅仅是选择最大 Q 值对应的动作。
- 在某些情况下,直接学习策略可能比学习 Q 值函数更简单,尤其是在高维连续动作空间(Continuous Action Space)下。
理论上的优势
- 梯度更新更加稳定:相比于 epsilon-贪心方法,策略梯度方法能够保证平滑更新,而 epsilon-贪心方法可能因 Q 值的微小变化导致策略的大幅变化。
- 收敛性更强:由于策略梯度方法能够保持平滑变化,通常可以提供比基于 Q 值的方法(如 DQN)更强的收敛性保证。
策略梯度定理(Policy Gradient Theorem) #
在 每个回合(Episode) 开始于固定的初始状态 s_0,则策略的性能指标 J(theta) 定义为:
\[ J(\theta) = v_{\pi_{\theta}}(s_0) \]策略梯度定理表明:性能指标的梯度可以表示为:
\[ \nabla J(\theta) \propto \sum_{s} \mu(s) \sum_{a} q_{\pi}(s, a) \nabla \pi(a | s, \theta) \]- mu(s) 表示在策略 pi 下,状态 s 出现的概率。
- q_{pi}(s, a) 表示在状态 s 采取动作 a 后的状态-动作值函数(State-Action Value Function)。
这表明,只要能够估计 q_{pi}(s, a) 和 \nabla pi(a | s, theta),我们就可以计算策略梯度,并通过梯度上升更新策略参数。
REINFORCE算法(蒙特卡洛策略梯度) #
由于直接计算上面的梯度期望很困难,我们可以用蒙特卡洛采样(Monte Carlo Sampling) 来近似求解。强化学习中,我们通常只能从环境中采样轨迹,无法直接获得完整的状态分布 mu(s)。因此,我们把对所有状态的求和转换为期望:
\[ \nabla J(\theta) = E_{\pi}[\sum_{a} q_{\pi}(S_t, a) \nabla \pi(a | S_t, \theta)] \]如果我们按照策略 \pi 进行采样,那么我们经历的状态 S_t 出现的频率就是它的真实分布,因此可以通过采样轨迹来估计梯度,而不需要明确计算整个状态空间的分布。
在强化学习中,我们只能观察到在某个状态 S_t 下采取的实际动作 A_t ,而不能观察到所有可能的动作。因此,我们不再遍历所有 a ,而是只考虑实际采取的动作 A_t ,并用重要性采样(Importance Sampling)方法调整权重:
\[ \sum_{a} q_{\pi}(S_t, a) \nabla \pi(a | S_t, \theta) \to G_t \frac{\nabla \pi(A_t | S_t, \theta)}{\pi(A_t | S_t, \theta)} \]对数梯度技巧(Log-Gradient Trick),用于转换求导。最终,我们得到了 REINFORCE 更新规则:
\[ \theta_{t+1} = \theta_t + \alpha G_t \nabla \log \pi(A_t | S_t, \theta_t) \]
LLM 核心技术 #
LLM 基础组件 #
⭐ Tokenization - 分词(BPE, WordPiece, SentencePiece)
⁉️ 什么是 Tokenization?为什么它对LLM至关重要?
什么是 Tokenization?为什么它对LLM至关重要?
Tokenization(分词)是将文本拆分成更小的单元(tokens)的过程,这些单元可以是单词、子词或字符。在自然语言处理中,分词是文本预处理的重要步骤。他直接影响模型对语义的理解能力、计算效率和内存占用。
- Example:句子 “Hello, world!” 可被切分为
["Hello", ",", "world", "!"](基于空格和标点)。
Note:简而言之,Tokenization 是一个 将输入文本拆解为 tokens(可能是词、子词或字符)的过程,而词表是一个 包含所有可能 tokens 的集合,它定义了 token 到数字 ID 的映射。Tokenization 使用词表来将文本转换为模型可以处理的数字序列。我们会使用不同的 Tokenization 方法构建词表,这个词表包含了词或子词的常见组合。当输入一个句子时,Tokenizer 会根据这个词表将输入的文本转换为 tokens,再传递给模型进行处理。
⁉️ 常见的 Tokenization 方法有哪些?它们的区别是什么?
常见的 Tokenization 方法有哪些?它们的区别是什么
- Word-level:按词切分(如
“natural language processing” → ["natural", "language", "processing"]),但词表大且难以处理未登录词(OOV)。 - Subword-level(主流方法):
- BPE(Byte-Pair Encoding):通过合并高频字符对生成子词(如GPT系列使用)。
- WordPiece:类似BPE,但基于概率合并(如BERT使用)。
- SentencePiece:无需预分词,直接处理原始文本(如T5使用)。
- Character-level:按字符切分,词表极小但序列长且语义建模困难。
⁉️ BPE算法的工作原理是什么?请举例说明。
BPE 算法的工作原理是什么?请举例说明。
BPE(Byte Pair Encoding)是一种子词分割(Subword Segmentation)算法,核心思想是基于 统计频率 的合并(Merge frequent pairs)。
- 工作原理:
- 统计字符对(Byte Pair)频率,找到最常见的相邻字符对。
["l", "o", "w", " ", "l", "o", "w", "e", "r", " ", "n", "e", "w", "e", "s", "t"] - 合并最频繁的字符对,形成新的子词单元。
(第一次)合并("l", "o") -> 2次 ("o", "w") -> 2次 ...("l", "o") → "lo":
(第二次)合并["lo", "w", "lo", "w", "er", "n", "e", "w", "e", "st"]("lo", "w") → "low"["low", "low", "er", "n", "e", "w", "e", "st"] - 重复步骤 1 和 2,直到达到预定的子词词汇量。
["low", "lower", "er", "newest"]vocab = {"low": 100, "lower": 101, "er": 102, "newest": 103}
- 统计字符对(Byte Pair)频率,找到最常见的相邻字符对。
BPE的优点是它 能够有效地处理未登录词,并且在处理长尾词(rare words)时表现良好。比如,词”unhappiness”可以被分解为”un” + “happiness”,而不是完全看作一个新的词。
⁉️ WordPiece 算法的工作原理是什么?请举例说明。
WordPiece 算法的工作原理是什么?请举例说明
WordPiece 的核心理念与BPE相似,但合并策略更注重语义完整性。其训练过程同样从基础单元(如字符)开始,但选择合并的标准并非单纯依赖频率,而是通过 计算合并后对语言模型概率的提升幅度,优先保留能够增强语义连贯性的子词。
假设语言模型的目标是最大化训练数据的似然概率,在 WordPiece 中,简化为 通过子词频率估计概率(即一元语言模型)。通过计算合并后对语言模型概率的提升幅度进行合并: [ \begin{equation} P(S)≈ \prod^{n}_{i=1}P(s_i) \end{equation} ]
工作原理:
与BPE类似,首先将所有词分解为最小的单位(如字符)。
["l", "o", "w", " ", "l", "o", "w", "e", "r", " ", "n", "e", "w", "e", "s", "t", " ", "w", "i", "d", "e", "s", "t"]统计所有可能的字符对(或子词对)在文本中的共现频率。
合并字符对,选择合并后能 最大化语言模型似然概率 的字符对。具体公式为:选择使
score = freq(pair) / (freq(first) * freq(second))最大的字符对(与 BPE 不同,BPE 仅选择频率最高的对)。每次合并对语言模型概率提升最大的合并组合。这里的
##表示这个 token 只能作为后缀出现,不会单独存在。{"low", "##er", "##ing", "new", "##est", "wide", "##st"}重复合并得分最高的字符对,直到达到预设的词汇表大小。
vocab = {"low": 100, "##er": 101, "##ing": 102, "new": 103, "##est": 104, "wide": 105, "##st": 106}
WordPiece 通过最大化语言模型概率合并子词,生成的子词更贴合语义需求。但计算复杂度更高,需多次评估合并得分。
- 若需模型捕捉深层语义(如预训练任务),优先选择 WordPiece。
- 若需快速处理大规模数据且词汇表灵活,BPE 更合适。
⁉️ SentencePiece 算法的工作原理是什么?请举例说明。
SentencePiece 算法的工作原理是什么?请举例说明
SentencePiece 是一种无监督的子词分割算法,其核心创新在于直接处理原始文本(包括空格和特殊符号),无需依赖预分词步骤。它支持两种底层算法:BPE 或 基于概率的Unigram Language Model。训练时,SentencePiece 将空格视为普通字符 _,可 直接处理多语言混合文本(如中英文混杂),并自动学习跨语言的统一子词划分规则。
- Example:
"Hello世界" → 编码为 ["▁He", "llo", "▁世", "界"]。
SentencePiece 支持多语言(Multilingual)无需调整,统一处理空格与特殊符号。这一特性使其在需要多语言支持的场景(如T5模型)中表现突出,同时简化了数据处理流程,特别适合处理社交媒体文本等非规范化输入。
⁉️ 如何处理未登录词(OOV)?
如何处理未登录词(OOV)?
- 子词切分:将OOV(Out-of-Vocabulary)词拆分为已知子词(如
“tokenization” → ["token", "ization"])。 - 回退策略:使用特殊标记(如
[UNK]),但会损失信息。 - 动态更新词表:在增量训练时扩展词表。
⁉️ Tokenization 如何影响模型性能?
Tokenization 如何影响模型性能?
- 词表过大:增加内存消耗,降低计算效率(Softmax 计算成本高)。
- 词表过小:导致长序列和语义碎片化(如切分为无意义的子词)。
- 语言适配性:中/日/韩等非空格语言需要特殊处理(如 SentencePiece)。
⁉️ 如何为多语言模型设计Tokenization方案?
如何为多语言模型设计 Tokenization 方案?
- 统一词表:使用 SentencePiece 跨语言训练(如mBERT)。
- 平衡语种覆盖:根据语种数据量调整合并规则,避免小语种被淹没。
- 特殊标记:添加语言ID(如
[EN]、[ZH])引导模型区分语言。
⁉️ Tokenizer 在实际模型预训练阶段是如何被使用的?词表大小对模型性能的影响?
Tokenizer 在实际模型预训练阶段是如何被使用的?词表大小对模型性能的影响?
Tokenizer(分词器)的主要作用是 将原始文本转换为模型可理解的离散数值表示,即Token ID(标记序列)。这个过程通常包括分词(Tokenization)、映射(Mapping to Vocabulary) 和 填充/截断(Padding/Truncation)。在分词时,不同的 Tokenizer会根据预定义的 词表(Vocabulary) 将文本拆分成最优的子词单元。
词表的大小决定了模型可识别的唯一 Token 数量,比如 LLaMA 采用了 32k 的词表,而 GPT-2 使用了 50k 词表。较大的词表允许模型以更少的 Token 表示相同文本,提高表达能力,但也增加了参数规模和计算复杂度;而较小的词表则 减少了计算需求,但可能导致序列变长,进而影响训练效率。因此,在预训练阶段,词表大小的选择会直接影响模型的记忆能力、计算成本以及推理速度。
Note:词表(Vocabulary)既可以直接使用预训练模型提供的标准词表,也可以根据自己的数据集重新训练一个词表,具体取决于应用需求:
- 直接使用预训练词表:如 GPT-3、LLaMA、T5 等开源模型的 Tokenizer 已经基于大规模文本语料(如 Common Crawl、Wikipedia)训练了词表,并随模型一起发布。直接使用这些词表能够确保与原始模型的 Token 方式一致,避免 Token 不匹配导致的性能下降。这种方法 适用于大多数 NLP 任务,特别是在迁移学习(Transfer Learning)场景下。
- 基于自有数据训练新词表:如果 目标领域与通用 NLP 语料差异较大(如医学、法律、金融等专业领域),或者需要支持特定语言(如低资源语言或多语言任务),可以使用 SentencePiece(支持 BPE、Unigram)或 Hugging Face Tokenizers 来从头训练词表。训练时通常会调整 词表大小(Vocabulary Size),使其适配目标任务。较大的词表可以减少 OOV(Out-Of-Vocabulary)问题,而较小的词表能减少计算复杂度,提高推理速度。
⭐ Word Embeddings - 词嵌入(Word2Vec、GloVe、FastText)
⁉️ 什么是词嵌入(Word Embeddings)?为什么它重要?
什么是词嵌入(Word Embeddings)?为什么它重要?
在自然语言处理中,Embedding(词嵌入)是将 离散的文本数据(如单词、短语或句子)映射到一个连续的、低维度的向量空间(vector space)的过程。他的作用包括:
- 捕捉语义关系(Semantic Relationships):能表示同义词、类比关系(如 king - man + woman ≈ queen)。
- 降维(Dimensionality Reduction):将高维的 独热编码(One-hot Encoding) 转换为低维密集向量,提高计算效率。
- 解决稀疏性问题(Handling Sparsity):相比于独热编码,词嵌入具有更好的泛化能力(Generalization)。
⁉️ 静态词向量 和 上下文动态词向量的区别?
静态词向量 和 上下文动态词向量的区别?
- 静态词向量(Static Word Embeddings) 的核心特点是 无论词语出现在何种上下文中,其向量表示均保持不变。这类方法通过大规模语料训练,捕捉词语间的语义和语法关系。静态词向量的优势在于训练高效、资源消耗低,且生成的向量可直观反映语义相似性(如“猫”和“狗”向量接近);但其 局限性是无法处理多义词(如“苹果”在“水果”和“手机”场景中的不同含义),因为 每个词仅对应单一向量。代表模型包括:Word2Vec, GloVe。
- 上下文动态词向量(Contextual Word Embeddings):静态嵌入虽然可以表示词语的语义,但它们无法根据上下文动态调整,例如 “bank” 在 “river bank” 和 “bank account” 里的含义不同。而 动态词嵌入 解决了这个问题,代表性模型包括 ELMo、BERT 和 GPT。
⁉️ 解释 Word2Vec 的两种模型:Skip-gram 和 CBOW。
解释 Word2Vec 的两种模型:Skip-gram 和 CBOW。
跳元模型(Skip-gram) 假设 一个词可以用来在文本序列中生成其周围的单词。以文本序列
“the”“man”“loves”“his”“son”为例。假设中心词选择“loves”,并将上下文窗口设置为2,给定中心词“loves”,跳元模型考虑生成上下文词“the”“man”“him”“son”的条件概率。最大化给定中心词时上下文词的条件概率: $$ max{\sum log P(context_w|center_w)} $$ Word2Vec 的核心是 一个浅层神经网络(Shallow Neural Network),由一个输入层、一个隐藏层(线性变换层)、一个输出层(Softmax 或其他采样方法)组成:- 输入示例:
- 句子:
“I love natural language processing.” - 若窗口大小为1,中心词为
“natural”,则上下文词为“love”和“language”。
- 句子:
- 输入通过 One-Hot 编码 表示为一个稀疏向量。例如,若词汇表为
["cat", "dog", "fish"],则“dog”的输入编码为[0, 1, 0]。 - 输入层到隐藏层:输入向量与 输入权重矩阵相乘,得到中心词的嵌入向量。
- 通过 输出权重矩阵将隐层向量映射到输出概率:
- 使用 Softmax 归一化,通过梯度下降优化词向量,使得上下文词的概率最大化。
跳元模型(Skip-gram)特点:
- 擅长捕捉低频词:通过中心词预测多个上下文,低频词有更多训练机会。
- 训练速度较慢:输出层需计算多个上下文词的概率。
- 输入示例:
连续词袋(CBOW) 与 Skip-gram 相对,CBOW 的训练过程是 给定上下文词,预测中心词。这里的目标是将多个上下文词的向量平均起来,并通过它们来预测中心词。在文本序列
“the”“man”“loves”“his”“son”中,在“loves”为中心词且上下文窗口为 2 的情况下,连续词袋模型考虑基于上下文词“the”“man”“him”“son”生成中心词“loves”的条件概率。最大化给定上下文时中心词的条件概率: $$ max{\sum log P(center_w|context_w)} $$ 连续词袋(CBOW)的训练细节与 跳元模型(Skip-Gram)大部分类似,但是在输入 One-Hot 编码表示时,跳元模型(Skip-Gram)将中心词进行 One-Hot 编码,而连续词袋(CBOW)将上下文词进行 One-Hot 编码并取平均值。 例如,中心词为“natural”,上下文词为“love”和“language”。输入为[0, 1, 0, 0, 0](“love”)和[0, 0, 0, 1, 0](“language”)的平均向量[0, 0.5, 0, 0.5, 0]。此外,输出概率通过 Softmax 计算公式也有不同。连续词袋(CBOW)特点:
- 训练速度快:输入为多个词的均值向量,计算效率高。
- 对高频词建模更好:上下文词共同贡献中心词预测。
⁉️ Word2Vec 如何优化训练效率?
Word2Vec 如何优化训练效率?
由于 softmax 操作的性质,上下文词可以是词表中的任意项,但是,在一个词典上(通常有几十万或数百万个单词)求和的梯度的计算成本是巨大的!为了降低计算复杂度,可以采用两种近似训练方法:负采样(Negative Sampling)和层序softmax(Hierarchical Softmax)。
负采样(Negative Sampling):
- 核心思想:将复杂的多分类问题(预测所有词的概率)简化为二分类问题,用少量负样本近似全词汇的Softmax计算。
- 正负样本构建:
- 对每个正样本(中心词与真实上下文词对),随机采样 K 个负样本(非上下文词)。
- 例如,中心词
“apple”的真实上下文词为“fruit”,则负样本可能是随机选择的“car”,“book”等无关词。
- 目标函数:最大化正样本对的相似度,同时最小化负样本对的相似度。
层序softmax(Hierarchical Softmax):
- 核心思想:通过二叉树(如霍夫曼树)编码词汇表,将全局Softmax分解为路径上的二分类概率乘积,减少计算量。
- 霍夫曼树构建:按词频从高到低排列词汇,高频词靠近根节点,形成最短路径。每个内部节点含一个可训练的向量参数。
⁉️ 解释 GloVe 的原理?
解释 GloVe 的原理?
GloVe(Global Vectors for Word Representation)是一种基于全局统计信息的词向量训练方法,它通过构造整个语料库的共现矩阵(co-occurrence matrix)并进行矩阵分解来学习词的向量表示,其核心思想是 通过捕捉词与词之间的全局共现关系来学习语义信息,而不是像 Word2Vec 那样依赖于局部上下文窗口的预测方法。 具体而言,GloVe 首先统计语料库中的词对共现次数,构建一个共现矩阵 X ,其中 X_{ij} 表示词 i 在词 j 附近出现的频率,并计算共现概率:
\[ P(j|i) = \frac{X_{ij}}{\sum_k X_{ik}} \]GloVe 的核心目标是学习一个词向量映射,使得向量之间的点积能够近似这个共现概率的对数:
\[ \mathbf{u}_j^\top \mathbf{v}_i + b_i + c_j = \log(X_{ij}) \]- v_i, u_j 是词 i 和词 j 的向量表示,每个词都由两个向量组成,一个是中心词向量 ,一个是上下文词向量
GloVe 并不依赖传统的神经网络,它的学习过程 更接近矩阵分解(Matrix Factorization)的优化方法,而非 Word2Vec 这样的前馈神经网络(Feedforward Neural Network)。GloVe 不依赖反向传播(Backpropagation),而是直接最小化共现概率对数的加权平方误差,来学习词向量。
GloVe 的优势在于它直接建模了全局的词共现信息,使得词向量能够更好地捕捉语义相似性和类比关系,如 “king - man + woman ≈ queen”,但由于依赖于整个共现矩阵,计算和存储成本较高,因此适用于大规模离线训练,而不是在线学习任务。
⁉️ 解释 FastText 的原理?
解释 FastText 的原理?
FastText 在 Word2Vec 的基础上进行了改进,能够更好地处理 OOV(Out-of-Vocabulary)问题,同时提高计算效率。FastText 的核心思想是 使用 n-gram 字符级子词(subword) 进行单词表示,而不是仅仅依赖于整个单词的词向量。它的训练过程类似于 Word2Vec 的 CBOW(Continuous Bag of Words)或 Skip-gram 模型,但 FastText 通过将一个单词拆分成多个 n-gram 片段(如 “apple” 可以被拆分为 <ap, app, ppl, ple, le>),然后通过这些 n-gram 子词的向量求和来表示整个单词,从而在处理未见单词时依然可以通过其子词获得较好的表示。
⁉️ 在实际项目中,如何选择不同的嵌入方法(Embedding Methods)?
在实际项目中,如何选择不同的嵌入方法(Embedding Methods)?
- 任务类型与语义需求:
- 基础语义任务(如文本分类、简单相似度计算):
- 静态嵌入:Word2Vec、GloVe、FastText。
- 优点:轻量高效,适合低资源场景。
- 示例:新闻分类任务中,预训练的 Word2Vec 向量足以捕捉主题关键词的语义。
- 静态嵌入:Word2Vec、GloVe、FastText。
- 复杂语义任务(如问答、指代消解、多义词理解):
- 上下文嵌入:BERT、RoBERTa、XLNet。
- 优点:动态生成上下文相关向量,解决一词多义。
- 示例:在医疗问答系统中,BERT可区分“Apple”指公司还是水果。
- 上下文嵌入:BERT、RoBERTa、XLNet。
- 数据量与领域适配:
- 小数据场景:
- 预训练静态嵌入 + 微调:使用公开预训练的 Word2Vec/GloVe,结合任务数据微调。
- 轻量上下文模型:ALBERT或TinyBERT,降低训练成本。
- 大数据场景:
- 从头训练上下文模型:基于领域数据训练BERT或GPT,捕捉领域专属语义。
- 领域适配:在金融/法律等领域,使用领域语料继续预训练(Domain-Adaptive Pretraining)。
⭐ Attention - 注意力机制(QKV,Self-Attention、多头注意力)
⁉️ 什么是注意力机制(Attention Mechanism)?其中的Q,K,V都代表什么?
什么是注意力机制(Attention Mechanism)?其中的Q,K,V都代表什么?
注意力机制(Attention Mechanism) 的核心思想是将 输入看作键-值对的数据库,并 基于查询计算注意力权重 (attention weights),可以动态地选择哪些输入部分(例如词语或特征)最为重要。注意力机制定义如下:
\[ \textrm{Attention}(\mathbf{q}, \mathcal{D}) \stackrel{\textrm{def}}{=} \sum_{i=1}^m \alpha(\mathbf{q}, \mathbf{k}_i) \mathbf{v}_i, \]- 这里的 q,查询(Query) 是当前模型试图“寻找”或“关注”的目标。它是一个向量,代表了你想匹配的信息。
- 公式中的 k,键(key) 是所有潜在匹配目标的特征表示。每个键对应于输入中的一个元素,表示这个元素的特性或身份。
- 其中的 v,值(value) 是和键一起存储的信息,也是最终被提取的信息。注意力机制的目标是通过查询和键找到最相关的值。
注意力机制的一般步骤为:
- 对查询和每个键计算相似度。
- 对这些相似度进行归一化(通常使用 Softmax 函数)。归一化后的结果称为注意力权重(Attention Weights)。
- 将注意力权重与对应的值相乘,得到一个加权求和结果。这个结果就是当前查询的输出。
在 transformer 中,Query (Q)、Key (K) 和 Value (V) 都是从输入嵌入(embedding)中线性变换得到的。它们的计算方式如下:
\[ Q = X W_Q, \quad K = X W_K, \quad V = X W_V \]得到 Q,K,V 的过程 相当于经历了一次线性变换。Attention不直接使用 X 而是使用经过矩阵乘法生成的这三个矩阵,因为使用三个可训练的参数矩阵,可增强模型的拟合能力。
⁉️ 什么是自注意力(Self-Attention)机制?它与传统注意力有何区别?
什么是自注意力(Self-Attention)机制?它与传统注意力有何区别?
Self-Attention(自注意力) 和 一般 Attention(注意力机制) 的 核心计算原理是相同的,都是通过 Query(Q) 和 Key(K) 计算相似度分数,再对 Value(V) 进行加权求和。但它们的区别在于作用目标不同:
- Self-Attention(自注意力)
- Q、K、V 都来自同一个输入序列 X ,即 自身内部计算注意力,挖掘序列中不同位置之间的关系。例如,在 Transformer 的 Encoder 里,每个单词都和句子中的所有单词计算注意力。
- General Attention(通用注意力,通常用于 Seq2Seq 结构)
- Q 和 K、V 来自不同的地方,通常是 Q 来自 Decoder,而 K、V 来自 Encoder,用于建立 Encoder 和 Decoder 之间的联系。例如,在机器翻译中,Decoder 生成当前词时,会对 Encoder 编码的所有词计算注意力,从而获取最相关的信息。
⁉️ 什么是缩放点积注意力(Scaled Dot-Product Attention)?为什么要除以 √d?
什么是缩放点积注意力(Scaled Dot-Product Attention)?为什么要除以 √d?
缩放点积注意力(Scaled Dot-Product Attention) 是 Transformer 结构中的核心机制之一,它用于计算查询(Query)、键(Key)和值(Value)之间的注意力分数,以捕捉序列中不同位置的关联性。在计算过程中,首先对查询矩阵 Q 和键矩阵 K 进行点积(Dot Product),得到注意力得分(Attention Scores)。这个点积运算的本质是衡量 查询向量(Query) 和 键向量(Key) 之间的相似度。 之后,Softmax 作用于Q,K计算出的相似度得分,以将其转换为概率分布,使其满足:
- 归一化(Normalization):确保所有注意力权重总和为 1,便于解释。
- 放大差异(Sharpening):通过指数运算增强高相关性词的权重,抑制低相关性词。
然而,点积的结果可能会随着 d_k(Key 维度的大小)增加而变大。将点积作为输入传递给 Softmax 函数时,Softmax 对大数值特别敏感,因为它会根据输入的相对大小来计算概率值。如果点积值变得非常大,Softmax 会让其中一些值的输出接近 1,而其他值接近 0,这会 导致计算不稳定或梯度消失等问题。
因此,在应用 Softmax 之前,需要对注意力得分进行缩放,即除以 √d_k,这样可以防止梯度消失或梯度爆炸问题,提高训练稳定性。这个缩放的主要目的是 将点积的方差控制在一个合理的范围,使其不随向量维度的增加而变得过大。 数学公式如下:
\[ \mathrm{softmax}\left(\frac{\mathbf Q \mathbf K^\top }{\sqrt{d}}\right) \mathbf V \in \mathbb{R}^{n\times v}. \]⁉️ 计算自注意力机制的时间和空间复杂度,分析其瓶颈。
计算自注意力机制的时间和空间复杂度,分析其瓶颈。
自注意力机制(Self-Attention Mechanism)的时间复杂度(Time Complexity)和空间复杂度(Space Complexity)主要受输入序列长度 n 影响。在标准的 Transformer 结构中,每个 Self-Attention Layer 计算 注意力权重(Attention Weights) 需要进行矩阵乘法,计算 Query Q 和 Key K 之间的点积并进行 Softmax 归一化。
其中, Q 和 K 的维度均为 (n x d_k) ,计算 QK^T 需要 O(n^2 d_k) 次乘法运算,而应用 Softmax 需要 O(n^2) 的额外计算,因此 整体时间复杂度为:
\[ O(n^2 d_k) \]Self-Attention 计算过程中,需要存储 注意力权重矩阵( n x n ),此外还需要存储 中间结果(如 Softmax 输出、梯度),使得 空间复杂度达到:
\[ O(n^2 + n d_k) \]- 瓶颈分析(Bottleneck Analysis)
- 计算瓶颈(Computational Bottleneck):由于 Self-Attention 需要 O(n^2 d_k) 的计算量,因此在超长文本(如 10K 以上 Token)上,计算成本极高,推理速度变慢。
- 内存瓶颈(Memory Bottleneck):存储 O(n^2) 的注意力权重矩阵会 占用大量显存(VRAM),限制了可处理的最大序列长度。
- 长序列扩展性差(Scalability for Long Sequences):当 n 增大时,Transformer 计算复杂度随 n^2 级增长,难以应用于长文本建模。
⁉️ 为什么需要多头注意力(Multi-Head Attention)?多头设计如何提升模型表达能力?
为什么需要多头注意力(Multi-Head Attention)?多头设计如何提升模型表达能力?
多头注意力(Multi-Head Attention)是 Transformer 结构中的关键组件,它通过多个独立的注意力头来提升模型的表达能力。其核心思想是 让模型在不同的子空间(Subspaces)中独立学习不同的特征表示,而不是仅依赖单一注意力机制。例如可以关注不同类型的关系(如语法关系、语义关系、长距离依赖等)。

在计算过程中,输入序列的特征矩阵首先经过线性变换,生成查询(Query, Q)、键(Key, K)、和值(Value, V)。然后,每个注意力头都会独立地对 Q、K、V 进行投影,将其拆分成多个低维子空间,即:
\[ \mathbf{h}_i = f(\mathbf W_i^{(q)}\mathbf q, \mathbf W_i^{(k)}\mathbf k,\mathbf W_i^{(v)}\mathbf v) \in \mathbb R^{p_v}, \]其中 W_i^q, W_i^k, W_i^v 是可训练的投影矩阵,每个头都对应一组独立的参数。随后,每个头分别执行 Scaled Dot-Product Attention(缩放点积注意力)。计算完成后,各个头的注意力输出会被拼接(Concatenation),然后通过一个最终的线性变换矩阵 W^o 进行映射:
\[ \begin{split}\mathbf W_o \begin{bmatrix}\mathbf h_1\\\vdots\\\mathbf h_h\end{bmatrix} \in \mathbb{R}^{p_o}.\end{split} \]这样,多头注意力的最终输出仍然保持与输入相同的维度,同时融合了来自多个注意力头的信息,提高了模型对不同层次语义的建模能力。
⭐ Positional Encoding - 位置编码(绝对位置,相对位置,RoPE)
⁉️ 为什么 Transformer 需要位置编码?纯 Self-Attention 为何无法感知位置信息?
为什么 Transformer 需要位置编码?纯 Self-Attention 为何无法感知位置信息?
在 Transformer 模型中,位置编码(Position Encoding)是用于注入位置信息的关键机制,因为模型本身的 Self-Attention 机制无法感知输入序列中元素的顺序或位置。Transformer 通过 Self-Attention 计算序列中各元素之间的关系,每个元素的表示(representation)由其与其他所有元素的相互作用决定。然而, Self-Attention 本身是位置无关的(position-independent),即它并不考虑元素在序列中的相对或绝对位置。因此,如果不显式地引入位置编码,模型就无法了解输入序列的顺序信息。
⁉️ 绝对位置编码(Absolute PE)和相对位置编码(Relative PE)的核心区别是什么?
绝对位置编码(Absolute PE)和相对位置编码(Relative PE)的核心区别是什么?
绝对位置编码(Absolute Position Encoding, Absolute PE)和相对位置编码(Relative Position Encoding, Relative PE)的核心区别在于它们对序列中单词位置的表示方式。绝对位置编码是基于序列中单词的固定位置来定义每个单词的位置编码,这些编码是通过对每个位置进行显式编码(例如使用正弦和余弦函数)来获得的。这意味着 每个位置的编码是固定的,与其他词汇之间的相对关系无关。简单来说,绝对位置编码的设计是通过为每个位置分配唯一的标识符来捕捉顺序信息。绝对位置编码被广泛用于 Transformer 模型中,如原始的 Transformer 和 BERT,这些模型通过对输入的词汇序列和其位置编码的加和来保留词汇的顺序信息。
相对位置编码则是通过 考虑单词之间的相对位置来计算每个单词的编码,而不是单纯地依赖于其绝对位置。在这种方法中,位置编码的更新基于词语之间的相对距离,因此它能捕捉到不同词之间的相对关系,而不仅仅是它们在序列中的固定位置。相对位置编码的一个例子是 Transformer-XL 模型,它通过引入相对位置编码来克服标准 Transformer 在处理长序列时存在的记忆限制问题,从而提升了对长距离依赖的建模能力。
尽管在某些情况下,相对位置编码可以通过绝对位置得到(例如,简单地计算位置差),但这种方法仍然有限。相对位置编码有以下优势:
- 灵活性和泛化性:相对位置编码使得模型能够处理不同长度的输入,而绝对位置编码依赖于固定的输入长度。这意味着在不同任务或不同数据集上,使用相对位置编码的模型能够更好地进行泛化,尤其是在处理较长序列时。
- 更好的长距离依赖建模:相对位置编码能够更有效地捕捉长距离的依赖关系,因为它直接反映了词汇间的相对关系,而绝对位置编码则对远距离的依赖建模较弱,尤其是在长序列的上下文中。
- 减少位置编码的冗余:在传统的绝对位置编码中,序列中的每个位置都有唯一的编码,且这些编码是全局固定的,而相对位置编码只关心词汇间的相对位置,从而避免了位置编码的冗余,尤其是在处理非常长的序列时。
⁉️ Sinusoidal 位置编码的公式是什么?为什么选择正弦/余弦函数组合?
Sinusoidal 位置编码的公式是什么?为什么选择正弦/余弦函数组合?
Sinusoidal 位置编码(Sinusoidal Positional Encoding) 是 Transformer 模型中用于捕捉序列中单词位置的一种方法,是常见的绝对位置编码(Absolute Position Encoding)方法。Sinusoidal 位置编码通过正弦和余弦函数的组合来生成每个位置的唯一向量,这些向量与输入的词嵌入(Word Embedding)相加,从而使模型能够学习到每个单词在序列中的位置。Sinusoidal 位置编码使用相同形状的位置嵌入矩阵 P 输出 X+P,其元素按以下公式生成:
\[ \begin{split}\begin{aligned} p_{i, 2j} &= \sin\left(\frac{i}{10000^{2j/d}}\right),\\p_{i, 2j+1} &= \cos\left(\frac{i}{10000^{2j/d}}\right).\end{aligned}\end{split} \]- 为什么选择正弦/余弦函数组合?
- 不同频率的周期性:正弦和余弦函数有不同的频率,使得每个位置的编码在不同维度上具有不同的周期。这种周期性使得模型可以通过不同频率的变化来学习相对位置关系。通过正弦和余弦函数的组合,位置编码能够覆盖较长序列的不同范围,模型可以捕捉到全局和局部的位置信息。
- 无重复的唯一表示:正弦和余弦函数的组合能够确保每个位置有一个独特的编码,这些编码在向量空间中是可区分的,能够提供丰富的位置信息。而且由于这两种函数的周期性和无穷制性质,不同位置的编码不会重复。
- 容易计算和扩展:正弦和余弦函数的计算非常简单且高效。它们无需额外的学习参数,且可以通过简单的公式根据位置直接计算得出。这样的位置编码方式能够在大规模数据中有效应用,同时支持较长序列的处理。
- 支持相对位置关系:这种编码方法能够通过比较不同位置的编码来推测它们之间的相对距离和顺序,尤其是在模型学习到的位置编码与实际任务(如机器翻译、文本生成)相关时,正弦/余弦函数的变化有助于保持序列的结构和信息流动。
⁉️ 为什么位置编码可以直接与词向量逐元素相加?位置编码会破坏词向量的语义空间吗?
为什么位置编码可以直接与word embedding逐元素相加?位置编码会破坏词向量的语义空间吗?
Word embedding 主要表示单词的语义信息。Positional Encoding 提供额外的位置信息,以弥补 Transformer 结构中缺少序列顺序感的问题。相加的效果 是让同一个词(如 “apple”)在不同的位置有略微不同的表示,但仍保留其主要的语义信息。
虽然位置嵌入矩阵 P 与词向量 X 直接相加,但在 transformer 获得 Query (Q)、Key (K) 和 Value (V)的线形变化过程中(i.e. Q = XW_q),在学习 Weight 的过程中会将语义和位置信息分别投射在不同的维度上。Positional Encoding 并不需要通过训练来学习,它是固定的、基于位置的函数,因此不干扰原本的语义信息。
⁉️ 什么是可学习的位置编码(Learned PE)?
什么是可学习的位置编码(Learned PE)?
可学习的位置编码(Learned Positional Encoding, Learned PE)是一种在模型训练过程中通过优化学习得到的位置编码方法。与传统的 Sinusoidal Positional Encoding(正弦波位置编码)不同,Learned PE 不使用固定的数学公式来表示位置,而是通过神经网络的训练自动学习每个位置的编码表示。通常,这些位置编码是通过与输入的 词嵌入(Word Embedding) 相加来为模型提供位置信息,从而使模型能够捕捉到输入序列中各个元素的顺序。具体来说,Learned Positional Encoding 是 通过一个嵌入层来生成的。这个过程如下:
- 位置嵌入(Position Embedding):每个位置(序列中的每个元素)都会被映射到一个可学习的向量。对于输入序列中的每个位置 i,我们为其分配一个嵌入向量 P_i ,这个向量是通过一个嵌入层学习得到的。
- 添加到词嵌入(Word Embedding):这些位置嵌入向量会与对应的词嵌入(Word Embedding)向量相加。假设某个词 w_i 在序列中的位置为 i,那么该词的最终输入向量为:
由于每个位置的编码表示是一个可训练的向量,它会在训练过程中和词嵌入(Word Embedding)一起作为输入传递到模型中。然后,模型通过反向传播算法更新这些可训练的参数,以便它们能够更好地捕捉到任务相关的位置信息。
可学习的位置编码的优点主要体现在 灵活性,由于位置编码是通过训练学习的,因此它可以在不同的任务和数据集上找到最优的表示,而不依赖于固定的模式(如正弦波的频率和相位)。这种灵活性使得它能够更好地适应各种复杂的数据模式和任务需求。
但它 需要更多的参数,Learned PE 需要为每个位置学习一个独立的参数,这使得模型的参数量增加,尤其是在处理长序列时,这可能会导致显著的计算和存储开销。同时也会有 过拟合风险:由于 Learnable PE 是基于数据学习的,它可能会过度拟合训练数据中的位置模式,尤其是在数据量较少的情况下,从而影响模型的泛化能力。
⁉️ 写出 RoPE(Rotary Position Embedding)的数学公式,并解释其如何融合相对位置信息。
写出 RoPE(Rotary Position Embedding)的数学公式,并解释其如何融合相对位置信息。
⁉️ 为什么相对位置编码在长文本任务(如文本生成)中表现更好?
为什么相对位置编码在长文本任务(如文本生成)中表现更好?
⁉️ 长度外推(Length Extrapolation)问题的本质是什么?哪些位置编码方法能缓解该问题?
长度外推(Length Extrapolation)问题的本质是什么?哪些位置编码方法能缓解该问题?
⭐ Transformer 模型架构细节(FFN,Layer Norm,激活函数)
⁉️ 解释Transformer 模型架构细节?
解释Transformer 模型架构细节?
Transformer模型是一种 Encoder-Decoder 架构。Transformer的输入(源序列)和输出(目标序列)在送入编码器和解码器之前,会与 位置编码(positional encoding)相加。这种结构的编码器和解码器都基于 自注意力机制(self-attention),并通过堆叠多个模块来实现。
具体来说,Transformer 的编码器(Encoder)由多个相同的层堆叠而成,每一层包含两个子层:第一个是 多头自注意力(multi-head self-attention),第二个是 逐位置的前馈网络(positionwise feed-forward network)。在编码器的自注意力机制中,查询(queries)、键(keys)和值(values)都来自前一层的输出。每个子层都使用 残差连接(residual connection) 设计,并在其后进行 层归一化(layer normalization),确保模型的训练更稳定。最终,编码器为输入序列的每个位置输出一个 d-维向量表示。
Transformer的解码器与编码器类似,也是由多个相同的层组成,包含残差连接和层归一化。除了与编码器相同的两个子层外,解码器还加入了一个额外的子层,称为 编码器-解码器注意力(encoder-decoder attention)。在这个子层中,查询来自解码器自注意力子层的输出,而键和值来自编码器的输出。解码器中的自注意力机制中,查询、键和值都来自前一层的输出,但每个位置只能关注解码器中当前位置之前的所有位置,从而保留了自回归(autoregressive)特性,确保 预测仅依赖于已生成的输出标记。
⁉️ Transformer 中 Encoder 的理解?为什么 堆叠多个 TransformerEncoderBlock?
Transformer 中 Encoder 的理解?为什么 堆叠多个 TransformerEncoderBlock?
Encoder 部分更关注于语言本身,Attention 找出词与词之间的全局关系(Q,K,V 均来自于自身),Positional FFN 深化词本身的含义,最终把所以词的理解综合到一个 matrix 当中。
堆叠多个 TransformerEncoderBlock 主要原因有:
每个 TransformerEncoderBlock 都可以看作是一个特征提取器。通过堆叠多个 Block,模型能够从输入数据中提取出多层次的特征。随着层数的增加,模型能够捕捉更复杂的语义关系和全局依赖:
- 浅层特征:语法、局部依赖。
- 中层特征:句法结构、短距离语义。
- 深层特征:全局语义、长距离依赖、抽象概念。
每个 TransformerEncoderBlock 都包含一个自注意力机制和一个前馈神经网络(FFN),这些模块引入了非线性变换。通过堆叠多个 Block,模型可以逐步组合这些非线性变换,从而学习到更复杂的函数映射。深度模型(更多层)通常具有更强的表达能力,能够拟合更复杂的模式。
虽然自注意力机制理论上可以捕捉任意距离的依赖关系,但在实际中,单层的注意力机制可能仍然有限。通过堆叠多个 Block,模型可以在不同层次上反复处理信息,从而更好地捕捉长距离依赖。
⁉️ 如何理解 Decoder 中三个子层(sublayers)的作用?
如何理解 Decoder 中三个子层(sublayers)的作用?
Transformer解码器由多个相同的层(layers)组成,每一层包括三个子层(sublayers):解码器自注意力(decoder self-attention)、编码器-解码器注意力(encoder-decoder attention) 和 逐位置前馈网络(positionwise feed-forward network)。每个子层都使用残差连接(residual connection)并紧接着进行层归一化(layer normalization)。
Masked Multi-Head Self-Attention Layer(解码器自注意力):在这一步过程中,Q、K、V 全部来自目标序列的嵌入表示(即 Decoder 自身的输入),与 Encoder 的输出无关。这一层的目的是让解码器 捕捉目标序列内部的依赖关系(例如语法结构、语义一致性),类似于 Encoder 的自注意力层捕捉输入序列的依赖关系。同时也确保 自回归特性(Autoregressive Property):在生成目标序列时,解码器是自回归的,即每个 token 的生成依赖于之前已经生成的 token。解码器自注意力通过掩码(mask) 机制,确保在生成第 t 个 token 时,只能关注到第 1 到第 t−1 个 token,而不能“偷看”未来的 token。
Multi-Head Attention Layer (Encoder-Decoder Attention)(编码器-解码器注意力):该子层将解码器的输出与编码器的输出结合起来。通过这种方式,解码器能够 获取来自编码器的上下文信息,从而使得解码器能够 生成更相关的输出。在此过程中,解码器利用 编码器的输出(经过自注意力处理后的表示)来调整自己对目标序列的预测。
- 编码器-解码器注意力中,Q(Query):来自 解码器的当前状态(目标序列的嵌入表示)即“我需要关注什么”。K(Key) 和 V(Value):来自 编码器的输出(即源序列的编码表示)。Key 表示源序列的特征,用于与 Query 计算相似度。Value 表示源序列的实际内容,用于加权求和。
Feed-Forward Neural Network Layer(前馈神经网络层):该子层负责对每个位置的表示进行非线性变换和进一步的处理。它通常由两个全连接层(Fully Connected Layers)组成,其中一个是激活函数(通常是 ReLU/GELU)处理的隐藏层,另一个是输出层。前馈层提供了模型的表达能力,使得模型可以学习更复杂的特征。
⁉️ LayerNorm 和 BatchNorm 的核心区别是什么?为什么 Transformer 选择 LayerNorm?
LayerNorm 和 BatchNorm 的核心区别是什么?为什么 Transformer 选择 LayerNorm?
Batch Normalization(BN) 在 batch 维度 上归一化,每个特征维度 独立计算均值和方差,统计 batch 内的样本均值 和方差。LayerNorm 在 特征维度(对每个样本的所有特征) 进行归一化,即在单个样本内部计算均值和方差,因此它不受 batch size 影响。
Transformer 选择 LayerNorm 而非 BatchNorm 的主要原因是 Transformer 需要处理变长序列并进行自回归推理(Autoregressive Inference),BatchNorm 在这种情况下无法正确归一化,而 LayerNorm 在每个时间步独立计算归一化统计量,避免了 batch 之间的依赖。
- Transformer 处理的是变长文本,例如 短句(“Hello”)和长句(“The weather is nice today”)可能共存于同一个 batch,但它们的 token 数不同。BatchNorm 无法直接在这些变长数据上计算 batch 统计量,因为不同长度的序列无法对齐进行批量归一化。 即使使用填充(Padding),这些填充值可能会影响均值和方差计算,导致不稳定的归一化效果。
- BatchNorm 依赖于 整个 mini-batch 统计量 进行归一化,而在推理阶段(Inference),模型通常只能接收到一个 token 或一个小段文本,并无法获取完整 batch 进行归一化。因此,BatchNorm 统计量在 训练时计算的是 整个 batch 的均值和方差,但在推理时,batch size 可能是 1,导致统计量发生偏移,影响预测质量。
此外,LayerNorm 在梯度流动上比 BatchNorm 更稳定,特别是对于深层 Transformer 模型,能够有效减少梯度消失(Gradient Vanishing)和梯度爆炸(Gradient Explosion)问题。
⁉️ Pre-LN 和 Post-LN 的区别是什么?为什么要在残差连接之后进行归一化(Post-LN)?
Pre-LN 和 Post-LN 的区别是什么?为什么要在残差连接之后进行归一化(Post-LN)?
Pre-Layer Normalization(Pre-LN)和 Post-Layer Normalization(Post-LN)是 Transformer 结构中两种不同的 Layer Normalization(LN,层归一化)策略。Pre-LN 在 Multi-Head Self-Attention(MHSA,多头自注意力) 和 Feed-Forward Network(FFN,前馈神经网络) 之前进行归一化,而 Post-LN 则在 残差连接(Residual Connection)之后进行归一化。
主要区别 在于梯度传播的方式:在 Pre-LN 结构中,归一化操作使得梯度 在深层网络中更加稳定,缓解了梯度消失(Gradient Vanishing)和梯度爆炸(Gradient Explosion)问题,因此 更适合深层 Transformer 训练。而 Post-LN 由于归一化在残差连接之后,会导致前期训练时梯度信号衰减,使得深度网络难以优化,尤其在 Transformer 层数较深时,梯度消失的问题更为严重。
然而,Post-LN 具有更好的优化表现,因为 它保留了每一层的特征分布,使得模型学习到的信息在归一化前不会被直接拉回到零均值单位方差的分布。因此,在某些场景下,如 小规模 Transformer 或浅层 Transformer,Post-LN 可能具有更好的收敛效果。
⁉️ 残差连接(Residual Connection)如何与 LayerNorm 协作缓解梯度消失?
残差连接(Residual Connection)如何与 LayerNorm 协作缓解梯度消失?
残差连接的核心思想是通过 跳跃连接(Skip Connection) 让信息能够绕过多个变换层,直接传递到更深的层,使梯度在反向传播(Backpropagation)过程中能够更稳定地传播。数学上,它通过加法操作,使输入 x 直接与变换后的输出 F(x) 相加,即 y = H(x) = x + F(x) ,从而保留原始信息并防止梯度过小。
- 一个标准的网络层尝试学习一个复杂的映射 H(x)。
- Residual Block 则将目标分解为 F(x) + x,其中:
- F(x) = H(x) - x:残差,即网络学习的部分。
Note: 直接学习 H(x)(输入到输出的完整映射)可能是一个高度复杂的问题,而学习残差 F(x) = H(x) - x 相对简单得多。在许多实际任务中,输入 x 与目标 H(x) 通常是接近的(例如图像分类任务中,特征提取后的信息不会发生剧烈变化)。通过学习残差 F(x),网络只需关注输入与输出之间的细微差异,而不必重新建模整个映射。
另一方面,LayerNorm 作用于每个时间步或通道上的神经元,对其均值和方差进行归一化,从而减小内部协变量偏移(Internal Covariate Shift),使梯度分布更加稳定,避免梯度消失或梯度爆炸(Gradient Explosion)。
⁉️ FFN 的结构是什么?为什么通常包含两层线性层和一个激活函数?
FFN 的结构是什么?为什么通常包含两层线性层和一个激活函数?
前馈神经网络(Feed-Forward Network, FFN)在深度学习模型(如 Transformer)中的结构通常包含两层线性变换(Linear Transformation)和一个非线性激活函数(Activation Function)组成:
\[ \text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2 \]具体来说,FFN 的第一层是一个线性变换 W_1x + b_1 ,将 输入投影到一个更高维度的隐藏层,随后通过非线性激活函数增加模型的表示能力,最后通过第二个线性变换 W_2h + b_2 将高维特征映射回原始维度。这种结构的主要作用是增强模型的非线性表达能力,使其能够学习到更复杂的特征关系。两层线性变换的设计可以视为一种低维到高维再回归低维的映射,这样能够增加模型的容量,同时控制计算成本。
Note: 每个 token 经过 Self-Attention 计算后,得到的输出向量会被 独立地 传入 FFN,这个过程 不会跨 token 共享计算,即 每个位置的 token 独立通过相同的前馈网络 进行转换。可以理解为所有的 token(x)一起通过一个完全一样的 MLP,所以位置共用 MLP 中的一个 weight。
在这个过程中会对每一个位置自身的特征信息进行加工,增加局部特征的表达力。而 Self-Attention 则负责关注全局的相互关系。
⁉️ 激活函数在 FFN 中的作用是什么?为什么常用 GELU 而非 ReLU?
激活函数在 FFN 中的作用是什么?为什么常用 GELU 而非 ReLU?
在前馈神经网络(Feedforward Neural Network, FFN)中,激活函数(Activation Function) 的主要作用是 引入非线性(Non-linearity),使网络能够学习复杂的特征表示,而不仅仅是线性变换。
在大规模预训练语言模型(Large Language Models, LLMs)中,高斯误差线性单元(Gaussian Error Linear Unit, GELU) 常被用作 FFN 的激活函数,而不是传统的 修正线性单元(Rectified Linear Unit, ReLU),主要是因为 GELU 能够提供更平滑的非线性变换,从而提升梯度流的稳定性。GELU 的数学表达式为:
\[ \text{GELU}(x) = x \cdot \Phi(x) = x \cdot \frac{1}{2} \left( 1 + \text{erf} \left( \frac{x}{\sqrt{2}} \right) \right) \]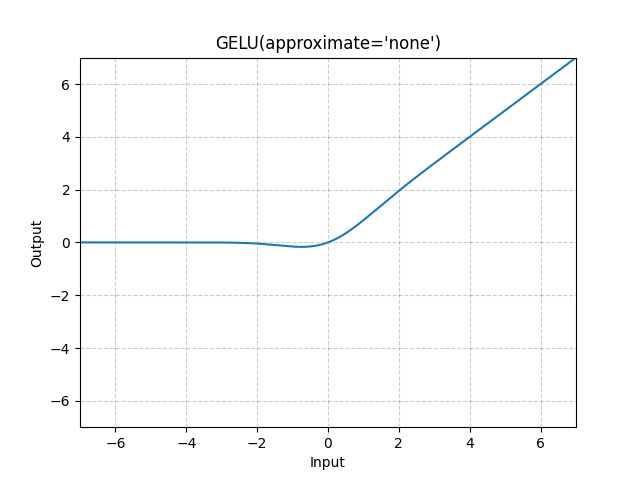
RELU 的数学表达式为:
\[ \text{RELU}(x) = \max(0, x) \]与 ReLU 相比,GELU 在接近 0 的输入处具有平滑的 S 形曲线,而 ReLU 在 0 处存在不连续性(即当 x < 0 时,输出恒为 0)。这种平滑性使 GELU 在训练过程中能够更自然地保留和传播梯度,而不会像 ReLU 那样导致某些神经元完全死亡(Dead Neurons)的问题。此外,由于 GELU 允许输入以概率方式通过,而不是简单地进行硬阈值裁剪(如 ReLU 的 max(0, x) ),它在自注意力(Self-Attention)结构中表现更优,有助于 LLMs 更有效地捕捉复杂的语义关系。
Note: 在 自然语言处理(NLP)任务中,数据通常具有更复杂的特征表示,负数不一定意味着无用信息。(NLP 中的负值包含语义信息,特别是涉及到情感分析、语法结构等复杂任务时。负值可能代表对立的意思(如否定、反向情感等),因此 保留负值 变得尤为重要。)
ReLU 直接裁剪负数部分,意味着所有小于 0 的值都被映射为 0,相当于丢弃了部分信息。GELU 不是一个硬阈值,而是 基于概率平滑地裁剪输入,这意味着接近 0 的小负值仍有一定概率被保留,而不是完全消失。e.g. 假设某层神经元计算出的输出是 -0.1,在 ReLU 下,它会变成 0,而在 GELU 下,它可能仍然保持 -0.05 或其他较小值。这有助于模型保留更多信息,避免信息过早丢失。
ReLU 存在“神经元死亡(Dead Neurons)”问题:如果一个神经元的输入总是负数,那么它的输出始终是 0,对应的梯度也会一直是 0,这样该神经元可能永远无法被更新,从而降低模型的表达能力。GELU 由于其平滑的 S 形曲线,即使在负数区域仍然保持一定梯度,这样梯度可以更稳定地传播,减少“死神经元”问题。数学上看,GELU 的导数:
\[ \frac{d}{dx} GELU(x) = \Phi(x) + x \cdot \phi(x) \]Phi(x) 是标准正态分布的 CDF,表示激活的概率。phi(x) 是标准正态分布的 PDF,表示数据在某个点的概率密度。相比于 ReLU 的二值导数(1 或 0),GELU 的梯度在整个数轴上连续变化,更利于优化。
常见大语言模型 #
⭐ 预训练模型(BERT、GPT、T5)
⁉️ 什么是预训练?与传统监督学习的区别?
什么是预训练?与传统监督学习的区别?
预训练(Pretraining)是一种在大规模无标注数据(Unlabeled Data)上训练深度学习模型的技术,特别常用于自然语言处理(NLP)中的大规模语言模型。在预训练阶段,模型通常采用 自监督学习(Self-Supervised Learning)方法,通过预测被遮蔽的词(如 BERT 的掩码语言模型 Masked Language Model, MLM)或基于上下文预测下一个词(如 GPT 的自回归语言模型 Autoregressive Language Model, AR)来学习文本的统计特性和语义表示(Semantic Representation)。
相比传统的监督学习(Supervised Learning),预训练 不需要大量人工标注数据,而是利用大规模无标签语料,使模型具备广泛的语言理解能力。随后,模型可以通过 微调(Fine-Tuning)在小规模标注数据上进一步优化,以适应具体任务。这种方式相比传统监督学习更加高效,尤其适用于数据标注成本高的任务,同时提升模型的泛化能力(Generalization Ability)和适应性(Adaptability)。
Note:Pre-training 是在大规模无监督数据上训练模型,而 Fine-tuning 是在特定任务或数据集上对模型进行微调。
⁉️ 解释Encoder-only,Encoder-Decoder,Decoder-only 三种模式的区别以及使用场景?
解释Encoder-only,Encoder-Decoder,Decoder-only 三种模式的区别以及使用场景?
- Encoder-only 模式:在这种架构中,只有 编码器(Encoder) 部分用于处理输入数据,通常应用于 文本分类(Text Classification)、命名实体识别(Named Entity Recognition, NER) 和 情感分析(Sentiment Analysis) 等任务。该模式的主要任务是从输入序列中提取信息,生成固定长度的表示,适用于 需要理解输入而不生成输出 的任务。例如,BERT 就是一个典型的 Encoder-only 模型,通过 自注意力机制(Self-Attention) 学习输入文本的上下文信息并生成表示。
- Encoder-Decoder 模式:这种架构包含一个 编码器(Encoder) 和一个 解码器(Decoder),用于从输入生成输出。输入通过编码器进行处理,得到一个上下文表示,然后解码器根据这个表示生成最终输出。这种结构非常适合 序列到序列任务(Sequence-to-Sequence Tasks),如 机器翻译(Machine Translation) 和 文本摘要(Text Summarization)。
- Decoder-only 模式:这种架构仅包含 解码器(Decoder),通常用于 自回归生成任务(Autoregressive Generation Tasks),例如 文本生成(Text Generation) 和 语言建模(Language Modeling)。在这种模式下,模型根据前面的输入和已经生成的词预测下一个词。一个典型的例子是 GPT 系列模型,它基于 Decoder-only 架构,通过不断预测下一个词来生成连贯的文本。此模式非常适用于 需要根据上下文生成输出 的任务。
⁉️ 有哪些适合 LLM 训练的参数初始化策略(Parameter Initialization)?
有哪些适合 LLM 训练的参数初始化策略(Parameter Initialization)?
参数初始化(Parameter Initialization) 是神经网络训练中的一个关键步骤,旨在为 网络的权重(weights)和偏置(biases)赋予初始值。这些初始值对模型的训练收敛速度、稳定性及最终性能有着重要影响。合理的参数初始化策略能够避免梯度消失(Vanishing Gradient)或梯度爆炸(Exploding Gradient)等问题,进而提高训练效率。
对于 大规模语言模型(Large Language Models, LLM) 的训练,一些常见且适用的参数初始化策略包括:
Xavier 初始化(Xavier Initialization):也叫做 Glorot 初始化,它通过考虑输入和输出的神经元数量来设置权重的方差。具体来说,权重的方差设置为:
[ W_{i,j} \sim N\left(0, \frac{2}{n_{\text{in}} + n_{\text{out}}}\right) ]
其中 n_in 和 n_out 分别是当前层的输入和输出神经元数量。此策略通常用于 sigmoid 或 tanh 激活函数的网络,能够帮助缓解梯度消失问题。
Note:Xavier 初始化适用于激活函数是 sigmoid 或 tanh 的网络的原因是这些激活函数的导数容易趋于零,尤其是在输入值落入激活函数的饱和区(Sigmoid 的两侧平坦区域)。如果权重初始化过大,输入会快速进入饱和区,导致梯度消失。如果权重初始化过小,输出信号会逐层衰减,最终导致梯度消失。
Xavier 的初始化方法将权重分布限定在一个较小的范围内,使输入值主要分布在 Sigmoid 和 Tanh 的线性区,避免梯度消失。在较深的网络中,信号可能仍会因为层数的累积效应导致衰减或放大。
- He 初始化(He Initialization):类似于 Xavier 初始化,但特别适用于 ReLU 激活函数。它通过设置权重的方差,有效地解决了 ReLU 激活函数中常见的 dying ReLU 问题,即一些神经元始终不激活。
Note:He 初始化适用于激活函数是ReLU及其变种的原因是对于 ReLU,当输入为负时,输出恒为 0;当输入为正时,输出为原值。由于一部分神经元输出会被截断为 0,导致有效的参与计算的神经元数量减少(称为“稀疏激活”现象)。如果初始化权重过小,信号会迅速减弱,导致梯度消失;而如果权重过大,信号会迅速放大,导致梯度爆炸。
He 初始化通过设定较大的方差,补偿了 ReLU 截断负值导致的信号损失。这样可以让激活值的分布更均衡,避免信号快速衰减或放大。He 初始化根据输入层大小调整权重的方差,使每层的输出方差保持相对稳定,即使网络层数增加,信号也不会显著衰减或爆炸。
- Pretrained Initialization:对于 LLM,使用在大规模数据集上预训练的权重作为初始化参数(例如 BERT、GPT)是一种常见且有效的做法。通过 迁移学习(Transfer Learning),这种初始化策略能够显著加速训练过程,并提升模型的性能。
⁉️ BERT 的预训练目标有哪些?什么是 MLM 和 NSP?具体如何实现?
BERT 的预训练目标有哪些?什么是 MLM 和 NSP?具体如何实现?
BERT(Bidirectional Encoder Representations from Transformers)的预训练目标主要包括 Masked Language Modeling(MLM) 和 Next Sentence Prediction(NSP)。
在 MLM 任务 中,BERT 随机遮盖(mask) 输入文本中的部分词汇(通常为 15%),并通过 Transformer Encoder 预测这些被遮盖的词。具体实现时,80% 的被遮盖词替换为 [MASK],10% 保持不变,另 10% 替换为随机词,以增强模型的泛化能力。
NSP 任务 旨在学习句子级别的关系,BERT 通过给定的两个句子 判断它们是否为原始文本中的连续句(IsNext)或随机拼接的无关句(NotNext)。训练时,BERT 以 50% 的概率选择相邻句子作为正样本,另 50% 选择无关句子作为负样本,并通过 二分类损失函数(Binary Cross-Entropy Loss) 进行优化。MLM 使 BERT 能够学习上下文双向依赖关系,而 NSP 则有助于建模句子间的全局关系,这两个目标共同提升了 BERT 在 自然语言理解(Natural Language Understanding, NLU) 任务中的表现。
Note: BERT 的 Masked Language Modeling 本质上就是在做“完形填空”:预训练时,先将一部分词随机地盖住,经过模型的拟合,如果能够很好地预测那些盖住的词,模型就学到了文本的内在逻辑。这部分的主要作用是让模型 学到词汇和语法规则,提高语言理解能力。
除了“完形填空”,BERT还需要做 Next Sentence Prediction 任务:预测句子B是否为句子A的下一句。Next Sentence Prediction有点像英语考试中的“段落排序”题,只不过简化到只考虑两句话。如果模型无法正确地基于当前句子预测 Next Sentence,而是生硬地把两个不相关的句子拼到一起,两个句子在语义上是毫不相关的,说明模型没有读懂文本背后的意思。 这部分的主要作用是让模型 学习句子级别的语义关系。
⁉️ 为什么 BERT 的输入需要添加 [CLS] 和 [SEP] 特殊标记?
为什么 BERT 的输入需要添加 [CLS] 和 [SEP] 特殊标记?
BERT 的输入需要添加 [CLS] 和 [SEP] 特殊标记,主要是用来表示 Next Sentence Prediction(NSP) 任务的输入格式,并增强模型的表示能力。例如:
[CLS] 句子A [SEP] 句子B [SEP]
[CLS](Classification Token):BERT 在输入序列的开头始终添加[CLS],它的最终隐藏状态(Hidden State)可以作为整个序列的表示,特别 适用于分类任务(如情感分析、自然语言推理 NLI)。即使不是分类任务,BERT 仍然会计算[CLS]的表示,因此它始终是输入的一部分。[SEP](Separator Token):BERT 采用双向 Transformer,因此需要区分单句和双句任务。在单句任务(如情感分析)中,输入序列结尾会加[SEP],而在双句任务(如问答 QA 或文本匹配),[SEP]用于分隔两个句子,帮助 BERT 处理跨句子的关系建模。
在 微调阶段(Fine-Tuning),不同任务对 [CLS] 和 [SEP] 的使用方式略有不同。例如:
- 文本分类(如情感分析):
[CLS]的最终表示输入到 Softmax 层进行分类。 - 问答(QA):
[SEP]作为问题和段落的分隔符,BERT 需要预测答案的起始和结束位置。 - 命名实体识别(NER):
[CLS]不是必须的,而是依赖 Token 级别的输出。
Note: 对比 BERT 的
[CLS]向量和平均池化获取句子表示的优缺点?
[CLS]向量的优缺点:
- 简洁性:只需要一个向量(即
[CLS]向量)来表示整个句子的语义,非常适用于分类任务,尤其是在输入句子较短时。- 端到端优化:由于 BERT 在预训练时优化了
[CLS]向量,使其能够有效地聚合句子的语义信息,且通常与下游任务紧密相关。- 可能信息丢失:
[CLS]向量是通过加权和整个输入的 token 嵌入得到的,可能导致一些细节信息丢失,特别是当句子较长或复杂时。- 平均池化(Mean Pooling)的优缺点:
- 信息保留:平均池化将所有 token 的表示进行平均,从而保留了句子中各个部分的信息,相比于
[CLS]向量,它能保留更多的语义信息。- 缺乏上下文关注:平均池化忽略了 token 之间的复杂依赖关系,简单的加权平均可能无法捕捉到句子中不同部分的关联性,尤其是在多义词或句子结构复杂时。
- 计算开销:对于长句子,平均池化需要计算所有 token 的平均值,可能增加计算开销,尤其在大规模数据集上。
⁉️ BERT 微调的细节?
BERT 微调的细节?
BERT(Bidirectional Encoder Representations from Transformers)微调(Fine-tuning)通常是在预训练(Pre-training)后的基础上,将整个 BERT 模型与特定任务的分类头(Task-specific Head)一起训练,使其适应下游任务(Downstream Task)。
在微调过程中,输入文本经过分词(Tokenization)后,会被转换为对应的词嵌入(Token Embeddings)、位置嵌入(Position Embeddings)和分段嵌入(Segment Embeddings),然后输入 BERT 的 Transformer 层。模型通过多层双向自注意力(Bidirectional Self-Attention)计算上下文信息,并在最终的 [CLS](分类标记)或其他适当的标记上添加任务特定的层,如全连接层(Fully Connected Layer)或 CRF(Conditional Random Field),然后使用任务相关的损失函数(Loss Function)进行优化,如交叉熵损失(Cross-Entropy Loss)用于分类任务。
⁉️ RoBERTa 的技术细节?它相比 BERT 做了哪些改进(如动态掩码、移除 NSP 任务)?
RoBERTa 的技术细节?它相比 BERT 做了哪些改进(如动态掩码、移除 NSP 任务)?
RoBERTa(Robustly Optimized BERT Pretraining Approach) 在 BERT(Bidirectional Encoder Representations from Transformers)的基础上进行了多项优化,以提高模型的性能和泛化能力。
首先,RoBERTa 采用了 动态掩码(Dynamic Masking) 机制,即在每个训练 epoch 重新随机生成 Masked Language Model(MLM)掩码,而 BERT 仅在数据预处理阶段静态确定掩码。这种动态策略增加了模型学习的多样性,提高了其对不同掩码模式的适应能力。
Note:训练时使用的动态掩码(Dynamic Masking)与静态掩码有何区别?
BERT 原始论文使用的是 静态掩码,即在数据预处理阶段,对训练数据进行一次性 Mask 处理,并将其存储起来。在训练过程中,每次使用该数据时,Mask 位置都是固定的。
RoBERTa 在 BERT 的基础上采用了 动态掩码,即在每次数据加载时,都会 随机重新选择 Mask 位置,确保同一输入文本在不同训练轮次中 Mask 位置不同。这提高了数据多样性,使得模型能够学习更丰富的上下文表示,而不会过度拟合某些固定的 Mask 位置。
其次,RoBERTa 移除了 NSP(Next Sentence Prediction)任务,BERT 在训练时采用了 NSP 任务以增强模型对句子关系的理解,但研究发现 NSP 任务并未显著提升下游任务的表现,甚至可能影响模型的学习效率。因此,RoBERTa 采用了更大规模的 连续文本(Longer Sequences of Text) 进行预训练,而不再强制区分句子关系。最后,RoBERTa 通过 增加 batch size 和训练数据量,并 采用更长的训练时间,进一步优化了 BERT 预训练过程,使模型能够更充分地学习语言特征。
⁉️ DeBERTa 的“解耦注意力”机制(Disentangled Attention)如何分离内容和位置信息?
DeBERTa 的“解耦注意力”机制(Disentangled Attention)如何分离内容和位置信息?
DeBERTa(Decoding-enhanced BERT with Disentangled Attention) 相较于 BERT 主要在 解耦注意力(Disentangled Attention) 和 相对位置编码(Relative Position Encoding) 方面进行了改进,以提升模型的语言理解能力。BERT 采用标准的 Transformer 注意力机制(Self-Attention),其中查询(Query)、键(Key)、值(Value)向量均是基于相同的嵌入(Embedding),这意味着 内容信息(Content Information) 和 位置信息(Positional Information) 混合在一起,限制了模型对句子结构的建模能力。而 DeBERTa 通过解耦注意力机制,对内容和位置信息分别编码,使得模型在计算注意力时能够更精确地理解不同词语之间的相对关系。
具体来说,DeBERTa 在计算注意力权重时,不是直接基于词向量(Token Embedding),而是 分别计算基于内容(Content-based Attention)和基于位置(Position-based Attention)的注意力得分,然后再将两者加权合并。这种方式使得 DeBERTa 能够在更长的依赖关系建模上表现更好。此外,DeBERTa 还采用了 增强的相对位置编码(Enhanced Relative Position Encoding),相比 BERT 的绝对位置编码(Absolute Positional Encoding),能够更自然地处理长文本结构。
⁉️ ALBERT 如何通过参数共享降低模型参数量?
ALBERT 如何通过参数共享降低模型参数量?
ALBERT(A Lite BERT)是对 BERT 模型的轻量化改进,旨在通过降低模型参数量而不显著影响模型性能。其主要技术细节涉及两项关键的优化策略:参数分解嵌入(Factorized Embedding) 和 跨层参数共享(Cross-Layer Parameter Sharing)。
- 参数分解嵌入(Factorized Embedding):BERT 使用了一个巨大的词嵌入矩阵(embedding matrix),其大小通常是词汇表的大小与隐藏层维度(hidden size)的乘积。而 ALBERT 采用了参数分解方法,将词嵌入矩阵分解为两个低维矩阵,分别是一个较小的 词汇嵌入矩阵(Word Embedding Matrix) 和一个较小的 隐藏层嵌入矩阵(Hidden Layer Embedding Matrix)。具体来说,词嵌入矩阵被分解为两个矩阵,一个低维的嵌入矩阵和一个较小的输出矩阵,这样就显著减少了参数数量。例如,假设词嵌入矩阵的维度为 V x H(V 是词汇表大小,H 是隐藏层大小),通过分解成两个矩阵 V x E 和 E x H(E 为较小的维度),可以大幅度减少计算复杂度和存储需求。
- 跨层参数共享(Cross-Layer Parameter Sharing):在标准的 BERT 中,每一层 Transformer 都有一组独立的参数,而 ALBERT 通过跨层共享参数,减少了每一层的独立参数。具体来说,ALBERT 将模型中多个 Transformer 层 的参数进行共享,所有层都使用相同的权重。这样,尽管 ALBERT 保留了更多的层数(如 BERT 的 12 层改为 12 层的 ALBERT),但通过共享权重,整体的参数数量大幅度减少。参数共享的核心思想是:每一层 Transformer 的前向传播和反向传播使用相同的参数,从而减少了每层的权重数量,降低了内存消耗。
⁉️ T5 如何统一不同 NLP 任务的格式?其预训练任务(如 Span Corruption)具体如何实现?
T5 如何统一不同 NLP 任务的格式?其预训练任务(如 Span Corruption)具体如何实现?
T5(Text-to-Text Transfer Transformer)通过将所有 NLP 任务(如文本分类、机器翻译、问答、摘要生成等)统一转换为文本到文本(Text-to-Text)的格式,从而实现了一个通用的 NLP 框架。具体而言,无论是输入句子的分类任务还是填空任务,T5 都会将输入转换为文本序列,并要求模型生成相应的文本输出。例如,情感分析任务的输入可以是 "sentiment: I love this movie",输出则是 "positive",而机器翻译任务的输入可能是 "translate English to French: How are you?",输出为 "Comment ça va?"。
Note:Span Corruption(Span-Masked Language Modeling, SMLM)与 Masked Language Modeling(MLM)的核心区别在于 Mask 的方式和学习目标的不同。
- MLM(Masked Language Modeling,BERT 采用):
- MLM 主要是随机选择 单个 token 进行遮蔽,然后让模型预测被遮蔽的 token。例如:
Input: "I love [MASK] learning" Target: "deep"- 由于每次仅遮蔽少量 token,BERT 可能 无法学习到更长跨度的依赖关系,特别是对完整的子句或短语的理解较弱。
- SMLM(Span-Masked Language Modeling,T5 采用):
- SMLM 采用 Span Corruption,即 一次遮蔽连续的多个 token,并用特殊标记
<extra_id_0>来表示被遮蔽部分。例如:Input: "I <extra_id_0> deep <extra_id_1>." Target: "<extra_id_0> love <extra_id_1> learning"- 能够更好地 学习长距离的依赖关系,适用于生成式任务(如摘要、翻译)。训练难度更高。
T5 采用的主要预训练任务是 Span Corruption(Span-Masked Language Modeling, SMLM),这是一种变体的掩码语言建模(Masked Language Modeling, MLM)。具体来说,该任务会在输入文本中随机选择若干个 span(即连续的子序列),用特殊的 <extra_id_X> 令牌替换它们,并要求模型预测被遮蔽的内容。例如,原始文本 "The quick brown fox jumps over the lazy dog" 可能会被转换为 "The <extra_id_0> fox jumps over the <extra_id_1> dog",而模型需要输出 "quick brown" <extra_id_0> 和 “lazy” <extra_id_1>。这种方式比 BERT 的单词级别掩码更灵活,有助于学习更丰富的上下文信息,从而提升生成任务的能力。
Note:在 Span Corruption 预训练(Span Corruption Pretraining)中,被遮蔽的文本片段(Masked Span)的长度通常遵循 Zipf 分布(Zipf’s Law),即较短的片段更常见,而较长的片段较少,以模拟自然语言中的信息分布。具体而言,像 T5 这样的模型使用 几何分布(Geometric Distribution) 来采样 span 长度,以确保既有短范围的遮蔽,也有跨多个 token 的长范围遮蔽。
不同的遮蔽长度会影响模型的学习能力:较短的 span(例如 1-3 个 token)有助于模型学习局部语义填充能力(Local Context Understanding),而较长的 span(如 8-10 个 token 甚至更长)可以增强模型的全局推理能力(Global Reasoning)和段落级理解能力(Document-Level Comprehension)。如果 span 过短,模型可能更倾向于基于表面模式(Surface Patterns)预测,而非真正理解上下文;如果 span 过长,则可能导致学习任务过于困难,使得模型难以有效收敛。
⁉️ 如何将预训练的 Encoder-Decoder 模型(如 T5)适配到具体下游任务?
如何将预训练的 Encoder-Decoder 模型(如 T5)适配到具体下游任务?
T5(Text-to-Text Transfer Transformer)模型与BERT相似,也需要通过在特定任务的数据上进行微调(fine-tuning)来完成下游任务。与BERT的微调有所不同,T5的主要特点包括:
- 任务描述(Task Prefix):T5 的输入不仅包含原始文本,还需要附加一个任务描述。例如,在文本摘要(Text Summarization)任务中,输入可以是 “summarize: 原文内容”,而在问答(Question Answering)任务中,输入可以是 “question: 问题内容 context: 相关文本”。这种设计使 T5 能够以统一的 文本到文本(Text-to-Text) 形式处理不同任务。
- 端到端序列生成(Sequence-to-Sequence Generation):与 BERT 仅能进行分类或填空任务不同,T5 依赖其 Transformer 解码器(Transformer Decoder) 来生成完整的输出序列,使其适用于文本生成任务,如自动摘要、数据到文本转换(Data-to-Text Generation)等。
- 无需额外层(No Task-Specific Layers):在 BERT 微调时,通常需要在其顶层添加特定的任务头(Task-Specific Head),如分类层(Classification Layer)或 CRF(Conditional Random Field)层,而 T5 直接将任务作为输入提示(Prompt),并使用相同的模型结构进行训练,无需修改额外的网络层。
⁉️ 什么是BART?BART 的预训练任务与 T5 有何异同?
什么是BART?BART 的预训练任务(如 Text Infilling、Sentence Permutation)与 T5 的 Span Corruption 有何异同?
BART(Bidirectional and Auto-Regressive Transformers) 是一种结合了 BERT(Bidirectional Encoder Representations from Transformers)和 GPT(Generative Pretrained Transformer)优点的生成模型。BART 在预训练过程中采用了 自编码器(Autoencoder) 结构,其编码器部分像 BERT 一样使用双向编码,能够捕捉上下文信息,而解码器则是像 GPT 一样用于生成任务,通过自回归方式生成文本。
BART 的预训练任务包括 Text Infilling 和 Sentence Permutation:
- Text Infilling:在这一任务中,模型需要从一段被掩盖部分的文本中恢复出被移除的词或词组。具体来说,给定一个输入文本,部分单词或短语被替换为掩码(mask),然后模型的任务是预测这些被掩盖的内容。这一任务类似于 BERT 的 Masked Language Model(MLM),但区别在于,BART 不仅仅是根据上下文来填充单一词汇,它的目标是生成整个缺失的文本片段。
原始文本:“The quick brown fox jumps over the lazy dog in the park.”掩盖后的文本:“The quick [MASK] jumps over the lazy dog in the park.”
Note:在 MLM 中,模型的目标是预测被随机掩盖的单个词(或子词)。虽然 Text Infilling 看起来类似于 MLM,但 BART 的 Text Infilling 中,掩盖的部分不仅限于单个词,而是可能是一个较大的片段或短语。通常,模型会随机选择一个较长的文本片段(如一个短语或句子的一部分)并用一个掩码标记替换,然后模型需要预测整个被掩盖的文本片段。
总结,MLM遮一个词,Text Infilling 遮一个片段,Span Corruption 遮多个片段。
- Sentence Permutation:在这一任务中,输入文本的句子顺序被打乱,模型的任务是根据上下文恢复正确的句子顺序。这个任务是为了帮助模型学习长文本的结构和上下文关系,使其能够生成连贯且符合语法规则的文本。它与 T5 中的 Span Corruption 有一定的相似性,因为两者都涉及对文本进行扰动,并要求模型根据扰动后的文本恢复原始文本。
原始文本: “The dog chased the ball. It was a sunny day.”打乱顺序后的文本: “It was a sunny day. The dog chased the ball.”
⁉️ Decoder-only 模型与 Encoder-Decoder 模型的核心区别是什么?
Decoder-only 模型与 Encoder-Decoder 模型的核心区别是什么?
Decoder-only(如GPT)仅保留解码器,通过自回归生成(逐词预测)完成任务。移除原始Transformer的编码器和交叉注意力层,保留掩码自注意力(Masked Self-Attention)与前馈网络(FFN)。输入处理时,文本序列添加特殊标记 <bos>(序列开始)和 <eos>(序列结束),目标序列为输入右移一位。适用任务主要为生成类任务(文本续写、对话、代码生成)。Encoder-Decoder(如原始Transformer、T5)分离编码器(理解输入)与解码器(生成输出),通过交叉注意力传递信息。适用任务主要为需严格分离输入理解与输出生成的任务(翻译、摘要、问答)。
Decoder-only模型通过 上下文学习(In-Context Learning) 将任务隐式编码到输入中(如添加“Translate English to French:”前缀),利用生成能力模拟翻译,完成和 Encoder-Decoder 一样的工作。但是 Encoder-Decoder在以下场景更具优势:
- 输入与输出解耦的复杂任务(如翻译):Encoder-Decoder 模型的编码器可先提取完整语义,解码器再逐词生成,避免生成过程中的语义偏差,准确性更高。而Decoder-only模型(如GPT-3)需通过Prompt(如“Translate English to French: …”)隐式对齐输入输出,易受提示词设计影响。
- 长文本处理效率:Encoder-Decoder:编码器一次性压缩输入为固定长度表示,解码生成时无需重复处理长输入(节省计算资源)。Decoder-only:生成每个词时需重新处理整个输入序列(如输入1000词的文档),导致计算复杂度高。
- 总结来说
- Decoder-only:适合开放域生成任务,依赖生成连贯性与上下文学习,但对输入-输出结构复杂的任务效率较低。
- Encoder-Decoder:在需严格分离理解与生成、处理长输入、多任务统一的场景中更优,尤其适合翻译、摘要等结构化任务。
- 类比:Decoder-only像“自由创作的作家”,Encoder-Decoder像“严谨的翻译官”——前者更灵活,后者更精准。
⁉️ Decoder-only 模型的预训练任务通常是什么?
Decoder-only 模型的预训练任务通常是什么?
- 自回归语言建模(Autoregressive Language Modeling):这个任务的目标是通过给定一部分文本(如前面的词或字符),预测接下来的单词或字符。例如,给定输入
“The cat sat on the”, 模型的任务是预测下一个单词是“mat”。这个过程是自回归的,因为每次生成新的词都会基于模型已经生成的文本。自回归语言建模任务常见于 GPT(Generative Pre-trained Transformer) 等模型。 - 文本填充任务(Cloze Task):在这个任务中,模型的目标是根据上下文填充文本中的空白部分。例如,给定句子
“The cat sat on the ____”, 模型需要预测空白处应该填入的词“mat”。这种填空任务常见于 BERT(Bidirectional Encoder Representations from Transformers) 的变体,如 Masked Language Modeling (MLM)。尽管 BERT 是基于 编码器(Encoder) 架构,但类似的目标也可以应用于 Decoder-only 架构,通过在训练时将部分词语随机遮蔽(mask)并让模型预测被遮蔽的部分。
⁉️ 为什么 Decoder-only 模型通常采用自回归生成方式?因果掩码的作用及其实现方法。
为什么 Decoder-only 模型通常采用自回归生成方式?因果掩码的作用及其实现方法。
Decoder-only 模型通常采用自回归(Autoregressive)生成方式,因为这种方式能够通过模型已经生成的输出逐步生成下一个 token,从而形成连贯的序列。自回归生成方式使得每个步骤的生成依赖于前一步的生成结果,这种特性非常适合文本生成任务,如 语言建模(Language Modeling) 和 对话生成(Dialogue Generation)。通过这种方式,模型能够以逐词的方式生成文本,在每个步骤中利用之前的上下文信息预测下一个 token。即最大化序列联合概率,损失函数为交叉熵(Cross-Entropy):
\[ \begin{equation} \mathcal{L} = -\sum_{t=1}^{T} \log P(w_t | w_{1:t-1 }) \end{equation} \]在 Decoder-only 模型中,因果掩码(Causal Mask) 的作用是确保模型在生成时 仅依赖于已生成的部分,而不会看到未来的信息。具体来说,在训练时,因果掩码会屏蔽未来 token 的信息,使得模型只能访问当前位置及其之前的 token,这样保证了每个时间步的预测仅受历史信息的影响,而无法窥视未来的输出。实现方法通常是在注意力机制(Attention Mechanism)中,通过对自注意力矩阵应用一个上三角矩阵的掩码,将未来的 token 阻止在计算中。例如,如果在生成第 4 个 token 时,模型不允许访问第 5、6 个 token,掩码就会在这些位置设置为负无穷,从而避免信息泄漏。
⁉️ 解释 Teacher Forcing 在 Decoder-only 模型训练中的作用及其潜在缺陷。
解释 Teacher Forcing 在 Decoder-only 模型训练中的作用及其潜在缺陷。
Teacher Forcing 是一种在训练序列生成模型时常用的技术,尤其是在 Decoder-only 模型(如 GPT 等自回归语言模型)的训练过程中。在 Teacher Forcing 中,模型在 每个时间步的输入不依赖于前一步的预测输出,而是直接使用真实的目标词(Ground Truth)作为输入。这意味着,在训练过程中,Decoder 在每个时间步都接收的是当前时间步的真实标签,而不是模型自己预测的输出。
这种方法的主要作用是加速模型训练,因为它 避免了模型在每次预测时犯错后导致的错误传播。在传统的训练过程中,模型每一次的预测都可能受到前一步错误的影响,这样会使得训练变得更加困难且收敛速度变慢。而 Teacher Forcing 确保每个时间步的输入都是正确的,从而减少了梯度计算中的误差积累,加速了训练过程。
然而,Teacher Forcing 也存在潜在缺陷,特别是在 推理阶段(Inference)。在训练阶段,模型总是看到真实的目标词作为输入,但在推理时,它必须依赖于自己之前的预测。Teacher Forcing 可能导致 模型在训练和推理时的分布不匹配(Exposure Bias),即训练时的“理想环境”与实际推理时的“真实环境”不一致。若在训练中模型从未经历过自己预测错误的情况,它可能在推理时无法有效地纠正错误,从而影响生成的质量,导致 生成质量下降 或 无法适应真实环境中的错误传播。
为了缓解这个问题,一些方法如 Scheduled Sampling 被提出,它 逐渐减少训练时的 Teacher Forcing 比例,让模型在训练阶段逐步适应自己的预测输出,从而提高模型在推理时的稳定性和表现。
⁉️ 什么是 In-Context Learning?Decoder-only 模型如何实现零样本(Zero-Shot)推理能力?
什么是 In-Context Learning?Decoder-only 模型如何实现零样本(Zero-Shot)推理能力?
上下文学习(In-Context Learning) 是指在推理过程中,模型通过理解并利用输入文本中的上下文信息来做出预测,而无需对任务进行额外的训练或微调(fine-tuning)。在这种方法中,模型通过直接接收任务的描述和示例输入-输出对,在推理时依赖这些信息来预测结果。与传统的基于训练的学习方式不同,上下文学习使得模型可以灵活应对新任务,而无需重新训练。
Decoder-only 模型(例如 GPT-3)通过将 任务的描述、示例以及相关输入文本提供给模型,使得模型能够在上下文中推理并生成响应。具体而言,GPT-3 和类似的 Transformer 模型基于自回归生成(autoregressive generation)机制,通过逐步生成下一个词,结合前文的上下文信息来进行推理。在这种机制下,模型无需显式的监督学习或微调,只要给定足够的上下文(例如任务描述和输入示例),它就能根据这些信息来做出预测。
- Few-shot 示例:
Q: Capital of France? A: Paris Q: Capital of Japan? A: Tokyo Q: Capital of Brazil? A:
- 模型通过前两例学习“Q-A”模式,生成“Brasília”。
- Zero-shot 指令:
Please answer the following question: What is the boiling point of water? Answer:
- 模型根据指令词“Please answer”生成“100°C (212°F) at sea level”。
Zero-Shot 推理的实现方式在于 训练过程中接触了多种任务(如文本生成、问答、翻译、摘要等),使得模型能够在面对新任务时,依靠其通用语言理解能力完成推理,而无需重新训练或微调(Fine-tuning)。例如,假设我们要求模型完成一个数学问题,尽管模型未曾专门针对该任务训练,但它能依赖于其对语言的广泛理解,推断出合理的解答。大规模的训练数据为模型提供了更广泛的背景知识,使其能够在推理时利用丰富的上下文信息。
举个例子,当我们给出一个从未见过的任务,比如 “翻译以下文本成法语:‘I have a dream’”,GPT-3 可以准确地根据其训练数据中的语言模式生成翻译:“J’ai un rêve”。这是因为在其训练数据中,它已经接触过大量的文本翻译任务,并学会了如何根据提示进行推理。
⁉️ 对比 Greedy Search 与 Beam Search 在 Decoder-only 模型中的优缺点。
对比 Greedy Search 与 Beam Search 在 Decoder-only 模型中的优缺点。
Greedy Search 是一种简单的解码策略,它在 每个时间步(Time Step)选择概率最大的词作为输出。具体来说,对于每个生成步骤,模型会选择当前概率分布中 最大概率的词(Maximum Probability Word) 作为下一步的输出,并且该词会作为输入传递到下一个时间步。Greedy Search 的优点是 计算效率高(High Computational Efficiency),因为它只进行单一的选择和计算。然而,它的缺点是 局部最优问题(Local Optima),即每次选择最有可能的词,而没有考虑未来可能的其他选择,因此它容易陷入次优解,导致生成的序列质量不高。
与此不同,Beam Search 是一种更加复杂的解码方法,它通过在每个时间步保留 多个候选序列(Multiple Candidate Sequences) 来进行搜索。具体来说,Beam Search 会在每个步骤保留 k个最优候选(Top-k Candidates),而不是仅仅选择概率最大的一个词。通过这种方式,Beam Search 允许模型探索更多的可能性,从而提高生成质量。Beam Search 的优点是能够生成更具多样性的序列,通常能避免 Greedy Search 的局部最优问题,生成的结果更具 全局最优性(Global Optimality)。然而,它的缺点是 计算开销较大(Higher Computational Cost),因为需要维护多个候选序列,尤其在长文本生成时,这种计算开销可能会显著增加。
⁉️ Top-k 采样 和 Top-p(Nucleus)采样 的核心区别是什么?各适用于什么场景?
Top-k 采样 和 Top-p(Nucleus)采样 的核心区别是什么?各适用于什么场景?
Top-k 采样、Top-p 采样和 Greedy Search 和 Beam Search 一样都是解码策略(decoding strategies),它们的目标是生成高质量的文本。
Top-k 采样 是一种基于概率分布的截断方法,在每次生成一个单词时,只从概率分布前 k 个最可能的词中选择一个进行生成,其他词的概率被截断为零。这种方法通过限制候选词的数量来控制生成文本的多样性,从而避免生成非常低概率的、不太合理的词汇。其公式可以表示为:
\[ P(w_i) = \begin{cases} P(w_i), & \text{if } w_i \in \text{Top-}k \\ 0, & \text{otherwise} \end{cases} \]Top-k 表示从前 k 个概率最高的词中进行选择。Top-k 采样适用于生成任务中需要平衡多样性和合理性,如 对话生成(Dialogue Generation) 和 文本创作(Text Generation) 等场景。
Top-p 采样(Nucleus Sampling) 则是一种基于 累积概率的采样方法。在每个时间步,Top-p 会选择一个最小的词集合,使得这些词的累积概率大于或等于 p。与 Top-k 采样固定候选词数不同,Top-p 采样动态调整候选词的数量,这使得它在生成过程中更加灵活和多样。其公式为:
\[ \sum_{i=1}^{n} P(w_i) \geq p \]P(w_i) 是每个候选词的概率,p 是预定的累积概率阈值。Top-p 采样适用于对生成多样性要求较高的任务,如 创意写作(Creative Writing) 或 开放域问答(Open-Domain QA),它能够灵活调整候选词的数量,从而在生成中加入更多的随机性。
⁉️ 温度参数(Temperature)如何影响 Decoder-only 模型的生成结果?
温度参数(Temperature)如何影响 Decoder-only 模型的生成结果?
温度参数(Temperature)在 Decoder-only 模型(如 GPT)中用于 控制生成文本的随机性或确定性。它的作用是在模型生成过程中对 输出概率分布(Output Probability Distribution)进行调整,从而影响模型的生成结果。温度的公式通常为:
\[ P(w) = \frac{e^{\frac{log(P(w))}{T}}}{\sum_{w{\prime}} e^{\frac{log(P(w{\prime}))}{T}}} \]其中,P(w) 是生成某个单词 w 的原始概率,T 是温度参数, w’ 是所有可能的单词。温度参数 T 控制了概率分布的平滑度。当 T = 1 时,模型按照正常的概率分布生成输出;当 T > 1 时,概率分布变得更加平缓,生成的结果会更加随机,可能导致较为多样化的输出;当 T < 1 时,概率分布变得更加陡峭,模型会更加倾向于选择概率较高的词语,从而生成更加确定性和保守的结果。
温度的调整作用于 softmax 函数(用于将模型的原始输出转换为概率分布)。通过改变温度值,模型可以控制生成内容的多样性和创造性。较高的温度通常会增加生成内容的创新性,但可能导致语法错误或不连贯的输出,而较低的温度则会使输出更加连贯和符合预期,但可能缺乏创意或多样性。
例如,在文本生成任务中,若我们将温度设为 1.0,则生成的文本遵循模型原本的概率分布;若我们将温度设为 0.5,生成的文本将更加趋向于模型最有可能生成的词,文本可能会变得单调和缺乏创意;若温度设为 1.5,则生成的文本可能会表现出更多的创造性,但也可能出现语法错误或不太连贯的部分。
⁉️ 为什么 Decoder-only 模型推理时需要 KV Cache?如何优化其内存占用?
为什么 Decoder-only 模型推理时需要 KV Cache?如何优化其内存占用?
Note:在推理阶段,所有的 权重(Weights)已经通过训练学习完毕(不再改变)。输入的句子会按照预定义的规则转换成 Query (Q)、Key (K) 和 Value (V) 向量。无论是训练阶段还是推理阶段,句子中的 每个 token(词)都会有一个唯一对应的 Key 和 Value 向量。在自回归生成过程中,每次输入新的时间步 x_t ,会计算出当前时刻的 Query 向量 Q_t ,同时,新的 Key 和 Value 向量 K_t, V_t 会与之前的 KV 缓存合并,形成当前时刻的完整历史信息。新的 Query 用于查询当前输入和历史信息之间的关系,从而生成有意义的上下文信息,用于生成下一个 token。
在 Decoder-only 模型(如 GPT)中,推理时需要 KV Cache(Key-Value Cache)来提高计算效率和减少内存占用。KV Cache 主要用于存储模型在每个时间步生成的 Key 和 Value 向量,这些向量用于自注意力机制(Self-Attention)中计算当前词与之前所有词之间的依赖关系。具体来说,当模型生成一个新的 token 时,它不仅要计算当前 token 的自注意力,还需要利用已经生成的 tokens 的表示来计算新的 token,因此必须保存这些 Key 和 Value 向量。
Note:假设我们正在进行推理,模型已经生成了序列 “I love deep learning” 中的前四个词 “I love deep learning”(也就是说,当前时间步是第5个词)。在传统推理中,如果没有 KV Cache,模型在计算每个新的 token 时都需要重新计算与之前所有已经生成的 tokens(“I love deep learning”)之间的依赖关系。
- 对于第5个词 “model”,模型首先计算 “model” 和 “I”、“love”、“deep”、“learning” 之间的自注意力(self-attention)。为了计算这个自注意力,模型需要 重新计算每个之前词的 Key 和 Value 向量。
为了避免这种重复计算,使用 KV Cache 的方法是:当我们生成第5个词时,模型会保存 前四个词(“I love deep learning”)的 Key 和 Value 向量。下一次生成新 token 时(比如第6个词),模型只需要利用 缓存中的 Key 和 Value 向量 来计算当前 token 和已经生成的历史 tokens 之间的依赖关系,而无需重新计算历史 tokens 的表示。
- 对于第5个词 “model”,模型首先计算 “model” 和缓存中的 “I love deep learning” 之间的自注意力。
- 在此过程中,模型使用的是 已经缓存的 Key 和 Value 向量,而不是重新计算整个输入序列的 Key 和 Value 向量。
- 当模型生成第6个词时,只需将第5个词 “model” 的 Key 和 Value 向量加入缓存,并计算与缓存中所有其他 tokens 之间的关系。
在传统的推理过程中,模型需要重新计算每个时间步的所有 Key 和 Value 向量,导致计算量和内存占用急剧增加。使用 KV Cache 后,模型只需要保存每一层的 Key 和 Value 向量,从而避免了重复计算,极大地提升了推理效率。
如何优化内存占用:
- 动态 KV 缓存大小:在一些任务中,并不需要保留所有时间步的 Key 和 Value 向量。例如,对于生成式任务,缓存可以按照一定步长进行清理,或者只保留 前 n 步 的缓存。
- 分层缓存:根据模型层数和层间依赖,可以在 不同层 采用不同的缓存策略。例如,可以对较低层进行更频繁的缓存清理,对较高层保留更多的缓存信息。
- 量化(Quantization):通过降低 Key 和 Value 向量的精度(例如从浮点数精度到低精度存储),减少内存占用,同时尽量保持推理的精度。
⁉️ Decoder-only 模型如何处理长文本依赖问题?(如稀疏注意力、窗口注意力)
Decoder-only 模型如何处理长文本依赖问题?(如稀疏注意力、窗口注意力)
Decoder-only 模型(如 GPT 类模型)通过不同的技术来处理长文本中的依赖问题,尤其是在处理长序列时,传统的 全局注意力(Global Attention) 计算会变得非常消耗资源。为了解决这个问题,Decoder-only 模型采用了 稀疏注意力(Sparse Attention) 和 窗口注意力(Windowed Attention) 等方法,从而有效地减小计算复杂度并增强长文本的建模能力。
稀疏注意力(Sparse Attention) 的 核心思想是通过引入局部化注意力机制,使得每个 token 只与部分上下文进行交互,从而减少计算量。具体而言,稀疏注意力只计算一部分的注意力权重而不是全部,这样可以降低模型计算的复杂度。常见的稀疏注意力结构包括 固定模式(Fixed Patterns) 和 学习模式(Learned Patterns),其中一个代表固定的局部上下文窗口,另一个则依赖于模型在训练过程中自适应学习关注哪些位置的关系。稀疏注意力通常通过 Top-k 注意力(Top-k Attention) 或 Block-sparse 格式 来实现。
窗口注意力(Windowed Attention) 是一种将输入序列划分为多个固定大小的窗口(或块),每个窗口内的 token 之间通过注意力进行交互,而窗口之间没有直接的依赖关系。窗口大小是一个超参数,通常会选择较小的窗口以限制每次计算的注意力范围,从而减少计算负担。通过这种方式,模型能够在较低的计算成本下捕捉到长序列中的重要信息,同时避免了全局注意力带来的高昂计算开销。
⭐ LLama
⁉️ 什么是LLama?它有哪些技术特点?
什么是LLama?它有哪些技术特点?
LLaMA(Large Language Model Meta AI) 是由 Meta(前 Facebook)推出的大规模语言模型,旨在提供高效的文本生成和理解能力,同时优化计算资源的利用。它基于 Transformer 架构,并采用了一系列优化技术,使其在计算资源较低的情况下仍能达到或超过 GPT-3 级别的性能。LLaMA 主要基于 Decoder-Only Transformer,即 因果语言模型(Causal Language Model, CLM),用于自回归文本生成。LLaMA 在多个方面进行了优化,包括数据选择、模型架构调整、训练方法等,主要特点如下:
- 更高效的训练
- 数据优化:LLaMA 训练时使用了更高质量的文本数据,减少了低质量和冗余数据,从而提高了训练效率和泛化能力。
- 更少计算资源:相比 GPT-3(175B 参数),LLaMA 采用了更小规模的参数(如 LLaMA-7B、LLaMA-13B、LLaMA-65B),但在多个基准测试中仍能达到甚至超越 GPT-3 的效果。
- Transformer 架构优化
- RoPE(旋转位置编码,Rotary Position Embeddings):LLaMA 使用 RoPE 代替传统的 绝对位置编码(Absolute Positional Encoding),使得模型可以更好地处理长文本:
- SwiGLU 激活函数(Swish-Gated Linear Unit):LLaMA 采用 SwiGLU 代替 ReLU 或 GELU 作为激活函数,提高了模型的表示能力:
- 不使用 Position Embedding Table:LLaMA 放弃了传统的 绝对位置编码,转而使用 RoPE,减少了额外的参数,同时增强了模型的泛化能力。
- Flash Attention 提高推理效率:LLaMA 可能使用 Flash Attention 进行加速,减少了传统 Transformer 中注意力计算的 时间复杂度:
⁉️ LLaMA 使用的 RoPE 如何编码位置信息?与传统绝对位置编码相比有何优势?
LLaMA 使用的 RoPE 如何编码位置信息?与传统绝对位置编码相比有何优势?
LLaMA 使用的 Rotary Position Embedding(RoPE) 通过在 自注意力机制(Self-Attention Mechanism) 中对 查询(Query) 和 键(Key) 施加旋转变换来编码位置信息,而不是像传统的绝对位置编码(Absolute Positional Encoding)那样将位置编码直接加到输入嵌入(Input Embeddings)上。RoPE 主要 利用旋转矩阵使得任意两个 token 之间的点积能够自然地反映它们的相对位置信息(Relative Positional Information),从而增强模型对长序列的泛化能力。
给定一个 d 维向量 x (如 Query 或 Key),RoPE 通过一个依赖于 token 位置 n 的 旋转矩阵(Rotation Matrix) 来对输入进行变换:
\[ \text{RoPE}(x_n) = R_{\theta_n} x_n \]其中,旋转矩阵 R_{\theta_n} 的构造方式如下:
- 首先,将每个向量划分为一对一对的二维子向量(即假设维度 d 为偶数,每两个维度一组)。
- 对于每个二维子向量 (x^{(2i)}, x^{(2i+1)}),应用如下的旋转变换:
其中,旋转角度 \theta_n^{(i)} 定义为:
\[ \theta_n^{(i)} = n / 10000^{2i/d} \]RoPE 相比于传统 Sinusoidal 位置编码的 优势 在于:
- 自然地编码相对位置信息(Relative Positional Encoding)
- 在 传统的 Sinusoidal 编码 中,位置编码 PE(n) 是直接加到输入嵌入上的,而在 RoPE 中,位置编码通过旋转变换作用于 Query 和 Key,使得注意力分数 QK^T 能够直接反映 token 之间的相对位置信息,无需额外的相对位置偏置设计。
- 无界位置泛化(Unbounded Position Generalization)
- 绝对位置编码(Sinusoidal) 依赖固定的预定义位置索引,难以泛化到训练时未见过的长序列。
- RoPE 仅通过角度的旋转变换编码位置信息,理论上可以无界扩展,而不会影响模型的性能。
- 更好的长距离依赖建模(Long-Range Dependency Modeling)
- Sinusoidal 位置编码 具有固定的正弦周期性,在较长距离的 token 之间可能会导致相似性降低。
- RoPE 通过旋转变换使得注意力计算中的点积值仍然能够捕捉远距离 token 之间的相对关系,从而增强模型的长距离依赖建模能力。
⁉️ 为什么 LLaMA 使用 SwiGLU 激活函数而非标准 ReLU 或 GELU?
为什么 LLaMA 使用 SwiGLU 激活函数而非标准 ReLU 或 GELU?
SwiGLU 是 Swish 激活函数和 Gated Linear Unit (GLU) 结合的变体,其公式如下:SwiGLU 是 Swish 激活函数和 Gated Linear Unit (GLU) 结合的变体,其公式如下:
\[ \text{SwiGLU}(x) = \text{Swish}(x) \odot \text{Linear}(x) = \left( \frac{x}{1 + \exp(-x)} \right) \odot W x + b \]LLaMA 选择 SwiGLU (Swish Gated Linear Unit) 作为激活函数,而非标准的 ReLU (Rectified Linear Unit) 或 GELU (Gaussian Error Linear Unit),主要是因为 SwiGLU 在大规模语言模型训练中的性能优势。首先,SwiGLU 结合了 Swish activation 和 Gated Linear Unit (GLU) 结构,使其能够 在非线性表达能力和计算效率之间取得平衡。相比于 ReLU,SwiGLU 避免了 dying ReLU problem(神经元输出恒为零的问题),并且减少了梯度消失现象。而相较于 GELU,SwiGLU 在实践中展现出了更优的梯度流动特性,并提高了训练稳定性。此外,SwiGLU 通过门控机制有效地增强了模型的表示能力,同时在 Transformer 结构中带来了更好的 parameter efficiency(参数效率),这对于大规模预训练模型至关重要。因此,LLaMA 采用 SwiGLU 作为激活函数,以提高整体的模型性能和训练效率。
⁉️ LLaMA 是否采用 Pre-LayerNorm 或 Post-LayerNorm?这对训练稳定性有何影响?
LLaMA 是否采用 Pre-LayerNorm 或 Post-LayerNorm?这对训练稳定性有何影响?
LLaMA (Large Language Model Meta AI) 使用的是 Post-LayerNorm 结构(Post-Layer Normalization)。与 Pre-LayerNorm 相比,Post-LayerNorm 将层归一化(Layer Normalization)应用在每个子层(如自注意力层和前馈神经网络层)之后,而不是之前。
这种选择对训练稳定性有重要影响。具体来说,Post-LayerNorm 有助于更稳定的梯度传播,尤其是在较深的网络中,避免了梯度消失或爆炸的现象。因为在 Pre-LayerNorm 中,层归一化发生在每个子层之前,这可能导致网络中更高的梯度不稳定性,尤其是在训练过程中梯度的变化幅度较大时。而 Post-LayerNorm 的顺序确保了归一化发生在激活函数后,可以有效地缓解这些问题,从而提高训练的稳定性和收敛速度。
⭐ DeepSeek
⁉️ 什么是 Deepseek V3?它有哪些技术特点?
什么是 Deepseek V3?它有哪些技术特点?
DeepSeek-V3 是典型的 Decoder-Only 架构,其设计继承了当前主流生成式大语言模型(如 GPT、LLaMA 等)的核心结构,但通过 混合专家(MoE) 的引入进一步优化了性能和效率。设计目标是实现高性能、高效率及低成本推理。该模型在架构和技术特点上进行了多项创新,尤其以混合专家(MoE,Mixture of Experts)架构为核心,显著提升了模型能力与资源利用效率。
DeepSeek V3的框架基于分层的 MoE-Transformer 架构,核心模块如下:
- 输入嵌入层:将输入文本转换为高维向量,可能结合动态词表扩展技术处理多语言或专业术语。
- MoE Transformer层:多头自注意力(MHSA):捕捉全局依赖关系,可能采用稀疏注意力或窗口注意力降低计算复杂度。
- MoE前馈网络(MoE-FFN):
- 每个MoE层包含多个专家(如128个),每个专家是一个独立的前馈神经网络。
- 路由器(Router):根据当前输入生成专家权重,选择Top-K专家(如Top-2)参与计算,其余专家被屏蔽以减少计算量。
- 残差连接与层归一化:确保训练稳定性。
- MoE前馈网络(MoE-FFN):
- 动态路由算法:使用可学习的门控机制(如GShard、Switch Transformer的路由策略),结合负载均衡损失函数,防止专家训练不均衡。
- 输出层:线性投影与Softmax生成下一个token的概率分布。
模型训练与优化 #
模型预训练 #
⭐ 预训练流程细节
⁉️ LLM 的预训练流程通常涉及到哪些环节?
LLM 的预训练流程通常涉及到哪些环节?
在 大规模语言模型(LLM, Large Language Model) 的 预训练(Pretraining) 过程中,整个流程可以从宏观的角度划分为 数据收集与预处理、模型架构设计、训练目标设定、优化与梯度更新、以及分布式训练 五个关键部分,每一部分在模型能力的提升上都起着至关重要的作用。
- 数据收集与预处理(Data Collection & Preprocessing):预训练的第一步是收集大规模、高质量的数据集,通常包括 网络文本(web corpus)、书籍(books)、维基百科(Wikipedia)、代码数据(code repositories) 等多种来源。数据经过 去重(deduplication)、格式化(formatting)、分词(tokenization) 等预处理步骤,以确保输入的数据干净、标准化,并能有效地被神经网络处理。此外,还可能应用 文本过滤(text filtering) 和 去毒化(detoxification) 以减少偏见(bias mitigation)和不良内容。
- 模型架构设计(Model Architecture Design):现代 LLM 主要采用 Transformer 架构,其核心是 自注意力机制(Self-Attention Mechanism),能够有效建模长距离依赖(long-range dependencies)。具体的设计可能包括 解码器(Decoder-only, 如 GPT 系列) 或 编码器-解码器(Encoder-Decoder, 如 T5) 结构,参数规模从数亿到数千亿不等。此外,还涉及 层数(number of layers)、隐藏维度(hidden size)、多头注意力(multi-head attention)、前馈网络(feedforward network) 等关键超参数的选择。
- 训练目标设定(Training Objectives):LLM 的预训练目标通常基于 自监督学习(Self-Supervised Learning),主要分为:
- 自回归目标(Autoregressive Objective, AR):如 GPT 系列使用的 因果语言建模(Causal Language Modeling, CLM),即通过已知的上下文预测下一个单词。
- 自编码目标(Autoencoding Objective, AE):如 BERT 采用的 掩码语言建模(Masked Language Modeling, MLM),即在输入中随机掩盖(mask)部分单词,并让模型预测原始单词。
- 对比学习(Contrastive Learning) 和 指令调优(Instruction Tuning) 在部分预训练或微调阶段也会用到,以提升模型的表示能力。
- 优化与梯度更新(Optimization & Gradient Updates):预训练的核心是基于 梯度下降(Gradient Descent) 进行参数优化,具体采用 AdamW(带权重衰减的 Adam 优化器)来减少过拟合(overfitting)。此外,由于 LLM 训练涉及超大规模的参数,通常会使用:
- 混合精度训练(Mixed Precision Training, FP16/BF16) 降低计算成本。
- 梯度裁剪(Gradient Clipping) 解决梯度爆炸(Gradient Explosion)。
- 学习率调度(Learning Rate Scheduling, 如 Cosine Decay, Warmup) 提升收敛效率。
- 分布式训练(Distributed Training):由于 LLM 规模巨大,单机难以承载完整计算,因此需要分布式训练,包括:
- 数据并行(Data Parallelism, DP):多个 GPU 处理相同的模型,但分配不同的数据批次(batches)。
- 模型并行(Model Parallelism, MP):模型的不同部分分布在多个 GPU 计算,适用于超大参数模型。
- 流水线并行(Pipeline Parallelism) 和 张量并行(Tensor Parallelism) 结合使用,以提升大模型的计算效率。
⁉️ 什么是对话模型和推理模型?他们的区别是什么?
什么是对话模型和推理模型?他们的区别是什么?
对话模型 主要用于 人机交互(Human-Computer Interaction),能够处理用户输入并生成合适的文本响应。典型的对话模型包括任务导向型对话系统(Task-Oriented Dialogue System),如用于客服的聊天机器人,以及开放域对话系统(Open-Domain Dialogue System),如基于大型语言模型(Large Language Model, LLM)的聊天助手。对话模型的核心能力包括 语义理解(Semantic Understanding)、上下文管理(Context Management)和自然语言生成(Natural Language Generation, NLG)。
推理模型 则专注于 逻辑推理(Logical Reasoning)、因果关系推断(Causal Inference)、数学计算(Mathematical Computation)或知识推理(Knowledge Reasoning)。这类模型通常用于解数学题(Mathematical Problem Solving)、常识推理(Commonsense Reasoning)或代码生成(Code Generation)。推理模型需要更强的逻辑一致性(Logical Consistency)和事实性(Factuality),通常会结合知识图谱(Knowledge Graph, KG)或强化学习(Reinforcement Learning, RL)来提升推理能力。
两者的主要区别在于:对话模型侧重于自然语言交互,强调流畅性(Fluency)和连贯性(Coherence);而推理模型侧重于逻辑推理能力,强调准确性(Accuracy)和可靠性(Reliability)。 许多现代 LLM(如 GPT-4、Claude、Gemini)在融合了对话能力和推理能力后,能够同时在对话和推理任务上表现良好,但在高难度推理任务上仍可能需要外部工具(如 Wolfram Alpha、代码解释器)辅助计算。
⁉️ 训练一个推理模型的流程是怎么样?
训练一个推理模型的流程是怎么样?
- *预训练阶段(Pretraining Phase):
- 使用自回归语言建模(Autoregressive Language Modeling, ARLM)或自编码语言建模(Autoencoding Language Modeling, AELM),在大规模文本数据上进行无监督学习(Unsupervised Learning),建立语言理解和基本的知识表示能力。
- 主要优化目标是最小化交叉熵损失(Cross-Entropy Loss),让模型学习文本分布。
- 任务适配微调(Task-Specific Fine-tuning):
- 在特定推理任务数据上进行监督微调(Supervised Fine-tuning, SFT),例如:
- 数学推理(Mathematical Reasoning): GSM8K, MATH, BigBench
- 常识推理(Commonsense Reasoning): OpenBookQA, ARC, HellaSwag
- 代码推理(Code Reasoning): HumanEval, MBPP
- 目标是优化逻辑推理能力(Logical Reasoning Capability)和问题求解能力(Problem-Solving Capability)。
- 增强推理能力(Reasoning Enhancement):
- 链式思维提示(Chain-of-Thought Prompting, CoT)训练: 让模型学习分步推理(Step-by-Step Reasoning),提升多步推理能力。
- 自一致性(Self-Consistency): 让模型生成多个不同解法,并投票选择最可能的正确答案,以提高推理稳定性。
- 工具增强(Tool-Augmented Training): 训练模型调用计算工具(如 Wolfram Alpha)或代码解释器,以提升高精度计算能力。
- 强化学习对齐(Alignment with Reinforcement Learning):
- 采用基于人类反馈的强化学习(RLHF),结合奖励模型(Reward Model, RM)优化推理质量,使模型更符合人类期望的答案。
- 使用最优策略迭代(Optimal Policy Iteration),减少模型的推理错误和幻觉(Hallucination)。
- 评估与测试(Evaluation & Benchmarking):
- 在标准推理基准测试(Benchmark Datasets)上评估,如:
- 数学推理(Mathematical Reasoning): MATH, GSM8K
- 逻辑推理(Logical Reasoning): LogiQA, ReClor
- 代码推理(Code Reasoning): HumanEval
⁉️ 什么是链式思维提示(Chain-of-Thought)?它在推理模型中是怎么被运用的?
什么是链式思维提示(Chain-of-Thought)?它在推理模型中是怎么被运用的?
链式思维提示(Chain-of-Thought Prompting, CoT) 是一种增强大型语言模型(Large Language Model, LLM)推理能力的技术,通过显式地引导模型逐步分解复杂问题,使其能够进行更可靠的逻辑推理(Logical Reasoning)。与传统的端到端回答方式不同,CoT 通过提供 中间推理步骤(Intermediate Reasoning Steps),减少模型在复杂任务中的直觉性错误(Intuitive Mistakes)。
在 推理模型(Reasoning Model)中,CoT 主要用于提高数学推理(Mathematical Reasoning)、常识推理(Commonsense Reasoning)、代码理解(Code Understanding)和因果推理(Causal Inference) 等任务的准确性。其应用方式包括:
- 显式提示(Explicit Prompting):在训练或推理过程中,提供带有详细推理过程的示例,使 LLM 学习如何以逻辑化的方式思考。例如,在解决数学问题时,CoT 提示会引导模型逐步拆解计算过程,而不是直接输出答案。
- 少样本学习(Few-shot Learning with CoT):使用几个带有详细推理步骤的示例作为输入,使得 LLM 能够模仿推理过程(Imitative Reasoning Process),即使在没有明确定义的规则情况下,也能推导出合理的答案。例如,在逻辑谜题(Logic Puzzles)或文本推理(Text-based Reasoning)任务中,CoT 可以让模型按照逻辑链条逐步推演结论。
- 自洽性验证(Self-Consistency with CoT):通过让模型生成多个不同的推理路径,并使用**投票机制(Majority Voting)**选出最可能的答案,以减少幻觉(Hallucination)和随机误差(Random Errors)。
⁉️ 什么是混合专家模型(Mixture of Experts, MoE)?
什么是混合专家模型(Mixture of Experts, MoE)?
混合专家模型(Mixture of Experts, MoE) 是一种神经网络架构,通过在不同的任务或输入数据上动态选择并激活子模型(专家模型, Experts),以提高计算效率和模型的表现。MoE模型通常由多个专家网络和一个门控机制(Gating Mechanism)组成。门控机制根据输入数据决定哪个专家应该被激活,从而使得每次计算只涉及部分专家,而不是全部专家网络。这种机制使得MoE可以在不显著增加计算负担的情况下,扩展到更大规模的模型。
MoE的关键优势在于其稀疏性(Sparsity),即每次计算只激活少数几个专家。这使得模型在处理大规模数据时,能够有效减少计算资源的消耗。专家的选择通常是通过门控网络来进行的,它会基于输入数据的特征动态决定哪个子网络最适合处理当前任务。通过这种方式,MoE能够在多个领域(如语言理解、图像识别等)上获得更强的表现。
假设我们的模型需要处理两个任务:
- 情感分析任务:输入一段文本,模型需要判断文本的情感(积极、消极、中立)。
- 机器翻译任务:输入一段英语句子,模型需要将其翻译成法语。
如果我们采用混合专家模型(MoE),我们将构建多个专家子网络(Experts),每个专家擅长处理特定类型的任务。例如: * 专家1(Expert 1):擅长情感分析任务。 * 专家2(Expert 2):擅长机器翻译任务。 * 专家3(Expert 3):擅长更复杂的语言理解任务(比如多轮对话)。 * 专家4(Expert 4):擅长语法解析任务。
然后,我们会使用一个 门控网络(Gating Network),它的作用是根据输入数据来决定激活哪些专家。举例来说,当模型接收到一个关于情感分析的输入文本时,门控网络可能会决定激活专家1来处理这个任务,因为专家1专门训练过情感分析的任务。另一方面,当接收到一段英语句子要求翻译成法语时,门控网络会选择激活专家2来处理翻译任务。
⁉️ 什么是多模态大语言模型(Multimodal LLM, MLLM)?它是如何实现的?
什么是多模态大语言模型(Multimodal LLM, MLLM)?它是如何实现的?
多模态大语言模型(Multimodal Large Language Model, MLLM)是一种能够处理和生成多种类型输入(如文本、图像、音频、视频等)的模型,它不仅限于文本数据,还能理解和生成跨多个模态(Modality)的信息。它的实现方式一般为:
- 模态转换(Modality Conversion):多模态模型通常通过 将不同类型的输入数据转换为相同的表示空间,来实现跨模态学习。例如,图像数据可以通过卷积神经网络(Convolutional Neural Network, CNN)进行特征提取,转化为固定长度的特征向量;音频数据可以通过 声学模型(Acoustic Model)或语音识别(Speech Recognition)模型转换为文本形式;视频数据通过时空特征提取(Spatio-temporal Feature Extraction) 技术处理。
- 多模态融合(Multimodal Fusion):一旦不同模态的数据被转换为相同的表示,下一步就是 融合(Fusion)。常见的融合方式包括早期融合(Early Fusion)、晚期融合(Late Fusion)和混合融合(Hybrid Fusion)。早期融合将不同模态的特征直接结合,晚期融合则在各自的模型部分独立处理后再进行融合,而混合融合则结合了这两种方法。具体的融合技术包括Transformer模型(Transformer-based Models),它能够处理多模态信息之间的复杂关系。
- 跨模态对齐(Cross-modal Alignment):在多模态模型中,关键挑战之一是确保不同模态之间的表示对齐(Alignment),使得图像、文本等模态的信息能够在同一空间内有效互操作。对比学习(Contrastive Learning)是一种常见的对齐方法,它通过最小化不同模态之间的表示距离,使得在一个共享的特征空间中,相关的模态信息能够彼此靠近。一个著名的例子是CLIP(Contrastive Language-Image Pre-training) 模型,它通过对比学习同时训练图像和文本特征,使得模型能够理解图像和文本之间的相关性。
- 多模态生成(Multimodal Generation):多模态生成模型能够根据不同模态的信息生成对应的输出。例如,DALL·E和MidJourney这样的模型能够基于文本描述生成图像;AudioLM则能够根据文本生成语音。为了实现这一目标,通常使用 条件生成模型(Conditional Generative Models)或扩散模型(Diffusion Models) 来确保在多模态条件下生成高质量的输出。
✅ 继续预学习
⁉️ 什么是继续预训练(Continued Pretraining)?它和Fine-tuning 有什么区别?
什么是继续预训练(Continued Pretraining)?它和Fine-tuning 有什么区别?
继续预训练(Continued Pretraining) 是指在一个已经 预训练(Pretraining) 过的大型语言模型(LLM)上,使用 新的大规模无标注文本数据进行进一步的预训练,以适应特定领域(如医学、法律、金融等)或更新模型的知识库。这一过程通常保持模型的 自监督学习(Self-Supervised Learning) 方式,例如 掩码语言模型(Masked Language Model, MLM) 或 自回归语言模型(Autoregressive Language Model, AR) 进行训练,以确保模型继续学习语言结构和知识。
相比之下,微调(Fine-tuning) 主要针对一个特定任务(如文本分类、命名实体识别、问答系统等),通常使用带标签的数据(Labeled Data),并进行 监督学习(Supervised Learning)。在微调过程中,模型的参数会在目标任务的数据上进行调整,使其更适应特定任务需求。Fine-tuning 训练时间短,数据量相对较小,调整的范围较窄,而 Continued Pretraining 可能需要 大规模的无监督数据,训练时间较长,并且可能涉及调整整个模型的参数。
简单来说,继续预训练是对 模型“整体知识库”的扩展,而微调是 针对“特定任务”的优化。
⁉️ 什么是垂域继续预训练?
什么是垂域继续预训练?
垂域继续预训练(Domain-Adaptive Pretraining) 是指在一个已经经过大规模 通用预训练(General Pretraining) 的 大语言模型(LLM, Large Language Model) 上,进一步使用特定领域的数据进行额外的训练,以使模型在该领域的任务上表现更优。这种方法的核心思想是 迁移学习(Transfer Learning),它可以帮助模型更好地理解 医药(Medical)、法律(Legal)、金融(Finance) 等专业领域的语言模式和术语,从而提升下游任务的效果,如领域特定的问答(Domain-Specific QA)、信息抽取(Information Extraction)、文本分类(Text Classification)等。
⁉️ 什么是长文本继续预训练?
什么是长文本继续预训练?
长文本继续预训练(Long-context Continued Pretraining) 是指在大语言模型(LLM, Large Language Model)已经完成初始训练的基础上,针对更长文本输入进行额外的训练,以增强模型对 长距离依赖关系(long-range dependencies)的建模能力。这种预训练方式主要用于解决传统 Transformer 架构在处理长文本时的上下文窗口长度(context window length) 限制问题,使模型能够更有效地理解并生成超长文本内容。
- 上下文窗口扩展技术(Context Window Extension Techniques):由于标准 Transformer 采用固定的 Positional Encoding(位置编码),其外推能力有限,因此在长文本预训练中,研究者提出了多种方法来扩展模型的上下文窗口,包括:
- RoPE(Rotary Positional Embedding, 旋转位置编码)外推:相比于传统的绝对位置编码,RoPE 通过相对旋转嵌入(relative rotation embeddings) 使模型能够更自然地外推到更长的序列长度,而不会因为超出训练范围的 token 位置导致性能急剧下降。
- ALiBi(Attention with Linear Biases):通过在注意力权重中引入线性衰减(linear decay),使模型能够在更长的上下文范围内保持有效的注意力机制,而不需要显式的位置编码。
- Multi-Scale Positional Embeddings:结合不同尺度的位置信息,使模型能够对局部和全局位置信息进行建模,从而提升长文本的推理能力。
- 长文本训练策略(Long-context Training Strategies):为了有效训练 LLM 处理长文本,需要优化计算效率和内存占用,常见的策略包括:
- FlashAttention:这是一种优化版的自注意力计算(self-attention computation)方法,核心思想是减少显存占用(memory footprint)并提升计算速度。FlashAttention 通过分块计算(chunking)和 IO-aware 优化,避免了标准 Transformer 在长序列上的 O(N²) 计算瓶颈,使得更长的序列能够被高效训练。
- Sliding Window Attention(滑动窗口注意力):在计算注意力时,仅关注固定窗口内的 token,降低计算复杂度。例如 Longformer 和 BigBird 采用此策略,使 Transformer 能够在 O(N) 甚至 O(log N) 的计算复杂度下处理超长文本。
- Memory-efficient Attention(高效内存注意力):如 Reformer 使用局部敏感哈希(LSH Attention, Locality-Sensitive Hashing),将注意力计算复杂度从 O(N²) 降低到 O(N log N),显著优化长文本处理的效率。
- Chunk-wise Training(分块训练):将长文本拆分成多个重叠的子块(overlapping chunks),然后通过交叉连接这些子块,使模型能够学习跨块的长距离依赖关系,而不会因为序列长度过长导致计算资源消耗过大。
分布式训练和训练框架 #
✅ 分布式训练
⁉️ 数据并行的基本工作原理是什么?
数据并行的基本工作原理是什么?
数据并行(Data Parallelism)的基本工作原理是将输入数据划分(partitioning)为多个子集,并在多个计算设备(如多个GPU或TPU)上并行执行相同的模型计算。每个设备持有相同的神经网络模型副本(model replica),但处理不同的数据子集(mini-batches)。
Note:由于梯度计算是线性的,多个 mini-batch 的梯度可以分别计算,并在后续进行加权平均合并。这种方法与单设备计算完整 batch 的梯度在数学上等价,因此数据并行不会影响梯度的正确性。
在训练过程中,数据并行通常遵循以下步骤:
- 数据划分(Data Partitioning):将输入批次(batch)拆分为多个子批次(sub-batches),并分配到不同的计算设备。
- 前向传播(Forward Pass):每个设备独立执行前向计算,计算出局部的损失值(loss)。
- 梯度计算(Gradient Computation):每个设备计算自身数据子集的梯度(gradients)。
- 梯度同步(Gradient Synchronization):使用分布式通信(如AllReduce操作)在所有设备间聚合(aggregate)梯度,以确保所有模型副本保持一致。
- 参数更新(Parameter Update):使用优化器(optimizer)对全局梯度执行参数更新(parameter update),并同步到所有设备。
⁉️ 数据并行过程中有哪些数据被计算、传递和存储?
数据并行过程中有哪些数据被计算、传递和存储?
- 计算过程中涉及的数据(存储在各个计算设备上)
- 输入数据(Input Data):每个计算设备(GPU/TPU)接收来自全局批次(Global Batch)的一个子批次(Sub-batch),并存储在其内存中。
- 中间激活值(Intermediate Activations):在前向传播(Forward Pass)过程中,计算各层的激活值并存储,以便在反向传播(Backward Pass)中使用。
- 损失值(Loss Values):每个设备独立计算自己的子批次损失值,并可能存储下来用于后续的梯度计算。
- 需要在设备间通信的数据(主要通过 AllReduce 操作)
- 梯度(Gradients):各设备计算出的参数梯度需要通过AllReduce操作在多个设备之间同步,以确保所有设备的梯度一致。
- 模型权重更新(Model Parameter Update):每次梯度更新后,最新的模型参数需要在所有设备间同步,以保证模型状态的一致性。
- 需要存储的数据(在内存或存储介质上)
- 模型参数(Model Parameters, W):所有计算设备存储相同的模型参数,每次更新后保持同步。
- 优化器状态(Optimizer States):包括动量(Momentum)、自适应优化方法(如 Adam、RMSprop)的二阶矩估计(Second-order Moments)等,这些状态通常在参数更新时存储,并在下一轮迭代继续使用。
- 检查点数据(Checkpoint Data):定期保存的模型权重、优化器状态和训练进度,以便在训练中断后恢复。
⁉️ 数据并行在 pytorch 框架下的流程?
数据并行在pytorch框架下的流程?
在 PyTorch 框架下,数据并行(Data Parallel)主要用于将模型训练任务分布到多个 GPU 上,从而加速大规模训练。在这个过程中,PyTorch 提供了 torch.nn.DataParallel 模块来简化分布式训练的实现。具体流程如下:
- 模型复制:首先,
DataParallel会在每个可用的 GPU 上复制模型。每个 GPU 拥有模型的一份副本(model replica)。这个过程可以通过torch.nn.DataParallel(model)来实现。 - 数据分配:当一个批次的数据输入到模型时,
DataParallel会自动将输入数据按 GPU 数量进行拆分(通常是按照批次大小),并将拆分后的数据分发到不同的 GPU 上进行计算。这一过程被称为数据并行化(data parallelism)。 - 每个 GPU 计算:每个 GPU 上的模型副本会使用分配到的数据进行前向传播(forward pass)和反向传播(backward pass),计算出梯度(gradients)并保存。
- 梯度汇总:所有 GPU 上计算出的梯度会被
DataParallel自动汇总到主 GPU(通常是 GPU 0)。这个过程通过梯度聚合(gradient aggregation)完成,主要是通过 all-reduce 操作来进行同步。 - 参数更新:在汇总了所有梯度之后,主 GPU 会将这些梯度应用到模型的参数上(通过优化器进行更新),然后同步更新模型的参数。
- 优化器与同步:通过 DataParallel,优化器的参数更新会同步到所有模型副本中,确保每个 GPU 上的模型始终保持一致。
使用 DataParallel 时,PyTorch 还会处理不同 GPU 之间的设备管理和数据传输,简化了多 GPU 训练的实现流程。不过,DataParallel 是单机多卡的解决方案,对于多机多卡的分布式训练,PyTorch 更推荐使用 torch.nn.parallel.DistributedDataParallel,它能够在分布式环境下提供更高效的通信和更好的扩展性(scalability)。
Note:
torch.nn.DataParallel(DP)与torch.nn.parallel.DistributedDataParallel(DDP)的区别?
DataParallel是一种数据并行的实现方式,它通过在多个 GPU 上复制同一个模型,然后将输入数据拆分为多个 mini-batches,并将它们分别送入不同的 GPU 进行计算。每个 GPU 计算完成后,DataParallel会在主 GPU 上进行梯度汇总,然后更新模型的参数。虽然使用起来简单,但由于主 GPU 负责所有梯度汇总的工作,因此DataParallel在性能上存在瓶颈,尤其是在多卡训练时,主 GPU 的负载可能会过重,影响整体效率。相比之下,
DistributedDataParallel是更加高效的并行训练方法。它通过使用分布式训练框架,将模型和数据并行地分布到多个 GPU 上,每个 GPU 处理自己的数据和计算,同时与其他 GPU 进行梯度同步。DDP 在每个 GPU 上运行独立的训练进程,避免了 DataParallel 中主 GPU 的瓶颈问题,能够实现更好的扩展性和性能。DDP 通常与torch.distributed API配合使用,可以支持跨多个节点的分布式训练,是在大规模训练中推荐的选择。也就是说,DDP 舍去了把梯度传回 gpu0 计算再返回更新参数的步骤,直接在每一个 gpu 都更新梯度然后直接更新参数。简而言之,
DataParallel更适合小规模的单机多卡训练,易于实现,但存在性能瓶颈;而DistributedDataParallel更适合大规模分布式训练,提供更高的效率和可扩展性。
⁉️ 数据并行的参数同步机制(同步 vs 异步更新)有何区别?
数据并行的参数同步机制(同步 vs 异步更新)有何区别?
在数据并行训练中,参数同步机制有两种主要方式:同步更新(Synchronous Update) 和 异步更新(Asynchronous Update)。它们的区别在于各个计算节点对模型参数的更新方式。
同步更新是指所有计算节点在每次梯度计算后,首先等待所有节点完成计算并同步其梯度,然后 统一更新模型参数。这种方式确保了所有节点的参数始终保持一致,适合于较小的集群或者对一致性要求较高的场景。其缺点是可能会导致较大的延迟,特别是在网络带宽不足时,每个节点都需要等待其他节点完成计算,这样就会受到最慢节点(straggler)的影响。同步更新常用于梯度下降优化(Gradient Descent)中的标准同步版本,如 All-Reduce。
异步更新则允许各个计算节点 独立地更新自己的参数,而无需等待其他节点的梯度。这种方式通常能提高计算效率,因为每个节点可以在完成本地计算后立刻更新参数,减少了等待的时间。然而,由于各个节点的参数更新不一致,可能会 导致模型收敛速度较慢,甚至可能会出现不稳定的情况,特别是当参数更新幅度过大时。异步更新常见于一些分布式深度学习框架中,如 Parameter Server 架构。
⁉️ 什么是模型并行(Model Parallelism)?
什么是模型并行(Model Parallelism)和混合并行(Hybrid Parallelism)?
模型并行(Model Parallelism)是一种将大型机器学习模型的不同部分分布在多个计算设备上进行并行计算的方法。当模型的规模超过单一设备的内存限制时,无法在一个设备上完全加载模型参数,模型并行就变得尤为重要。在这种策略中,模型被拆分成多个部分(例如,分割神经网络的不同层或模块),并将每个部分分配到不同的硬件设备上。通过这种方式,计算任务可以在多个设备之间进行负载均衡,从而加速训练过程并减少单一设备的内存负担。
模型并行和数据并行的核心区别在于它们处理模型和数据的方式。数据并行(Data Parallelism)将同一个模型复制到多个计算设备上(例如多个GPU),然后将数据划分成多个子集,每个设备负责处理一个子集,并在每次计算后合并梯度。这种方式适用于数据量较大,但模型能够在单一设备上存放的情况。模型并行(Model Parallelism)则是 将模型的不同部分分配到不同的计算设备上,每个设备负责处理模型的一部分计算,适用于模型太大,无法在单一设备上放下的情况。
混合并行(Hybrid Parallelism) 则结合了数据并行和模型并行的优点,在需要时同时使用这两种并行方式。通常,当模型非常大且数据量也较大时,混合并行能够将模型的不同部分分配到多个设备上,同时对每个设备上不同的数据进行并行计算。这样可以更高效地利用计算资源,在提升计算速度的同时避免内存瓶颈。
⁉️ 什么是张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)?
什么是张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)?
张量并行(Tensor Parallelism)是一种将 单个神经网络层的计算任务拆分到多个GPU上执行的方法,主要应用于大型矩阵运算。例如,在Transformer模型的自注意力机制(Self-Attention Mechanism)中,对查询(Query)、键(Key)、值(Value)矩阵的计算可以被拆分,每个GPU负责一部分矩阵的计算,并在计算过程中进行必要的通信(如All-Reduce操作)以合并结果。这种方式适用于单层计算负载较大的模型,能够有效减少单个GPU的内存占用,但会带来额外的通信开销。
流水线并行(Pipeline Parallelism)则是一种 将神经网络的不同层分配到不同的GPU进行顺序执行的方法,适用于具有深层结构的模型。例如,在Transformer模型中,可以将前半部分层(如前N层)分配到第一组GPU,后半部分层(如后M层)分配到另一组GPU。训练时,输入数据会按照批次(Micro-batches)被切分,并以流水线的方式在不同GPU间依次传播,减少了计算资源的空闲时间。
✅ 训练框架(PyTorch DDP、DeepSpeed)
⁉️ 什么是训练框架?有哪些常见的大语言模型训练框架?
什么是模型并行(Model Parallelism)和混合并行(Hybrid Parallelism)?
训练框架(Training Framework) 是用于构建、训练和优化深度学习模型的软件工具或库,通常提供自动梯度计算(Automatic Differentiation)、模型优化(Model Optimization)、数据加载(Data Loading)等功能,以简化大规模模型的训练过程。常见的大语言模型(Large Language Model, LLM)训练框架包括 PyTorch(提供灵活的动态图计算和分布式训练支持)、TensorFlow(支持静态计算图优化和高效的分布式训练)、JAX(基于XLA加速计算,适用于高效自动微分和TPU加速)、DeepSpeed(由微软开发,优化大规模模型的分布式训练,如ZeRO优化器)、Colossal-AI(专注于高效的并行计算和内存优化)、以及 Megatron-LM(由NVIDIA开发,专门针对超大规模Transformer模型进行优化)。
⁉️ 介绍 pytorch 训练框架?DP 和 DDP 的区别?
介绍 pytorch 训练框架?DP 和 DDP 的区别?
PyTorch 训练框架主要由 数据加载(Data Loading)、模型构建(Model Building)、前向传播(Forward Propagation)、损失计算(Loss Computation)、反向传播(Backward Propagation) 和 优化(Optimization) 这几个关键步骤组成。在分布式训练(Distributed Training)场景下,PyTorch 提供了两种常见的多 GPU 训练方式:torch.nn.DataParallel (DP) 和 torch.nn.parallel.DistributedDataParallel (DDP),它们的主要区别如下:
- 数据并行方式(Parallelism Approach):
DataParallel(DP)采用 单进程(Single-process) 模式,内部会自动将输入数据 复制(Replicate) 到多个 GPU 设备,并在每个 GPU 上执行前向计算,随后再进行 梯度汇总(Gradient Aggregation),最后更新主 GPU 上的模型参数。- DistributedDataParallel(DDP) 采用 多进程(Multi-process) 模式,每个进程负责一张 GPU,并使用 梯度同步(Gradient Synchronization) 机制来进行参数更新,通常基于 NCCL(NVIDIA Collective Communications Library) 或 Gloo 后端实现高效通信。
- 计算和通信开销(Computation & Communication Overhead):
- DP 的梯度汇总在 主 GPU 上完成,可能导致 主 GPU 负载过重(Bottleneck on Master GPU),在大规模分布式训练中会影响性能。
- DDP 采用 分布式梯度同步(All-Reduce Gradient Synchronization),直接在各个 GPU 间通信梯度,避免了 DP 的主 GPU 负载问题,因此 扩展性(Scalability)更好,能有效支持数百张 GPU。
- 模型参数同步(Model Parameter Synchronization):
- DP 在每次前向传播(Forward Pass)时,会 复制模型(Model Replication) 到各个 GPU,这导致 额外的内存开销(Memory Overhead),且在较大模型上可能导致训练变慢。
- DDP 仅在初始化时分发模型参数,并通过 梯度平均(Gradient Averaging) 来同步参数,因此避免了重复复制,训练效率更高。
⁉️ 介绍 DeepSpeed 训练框架的细节?
介绍 DeepSpeed 训练框架的细节?
DeepSpeed是由微软开发的深度学习训练优化框架,旨在提升大规模 预训练模型(Pretrained Models)的训练效率和资源利用率。它通过多个核心技术来优化大规模语言模型(Large Language Models, LLMs) 的训练,包括:
- ZeRO (Zero Redundancy Optimizer):ZeRO是一种内存优化策略(Memory Optimization Strategy),将优化器状态(Optimizer States)、梯度(Gradients)和参数(Model Parameters)分片存储在不同的GPU上,大幅减少单个GPU的显存占用,使得超大模型训练成为可能。
- DeepSpeed-Inference:一个用于高效推理的组件,支持Transformer层融合(Transformer Kernel Fusion)、张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism),显著提高推理速度并降低显存占用。
- 3D 并行(3D Parallelism):结合数据并行(Data Parallelism)、张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism),优化计算资源分配,使得更大的模型能够高效训练。
- 深度可伸缩性(Deep Scalability):DeepSpeed可以轻松扩展到数千个GPU,并利用高效的通信优化技术(如NVLink和InfiniBand)来最大化吞吐量。
- 深度压缩(Deep Compression):提供 稀疏化(Sparsity)和量化(Quantization) 技术,降低模型大小和计算成本,使得LLM可以在更小的设备上运行。
- 高效内存管理(Efficient Memory Management):通过 异步优化(Asynchronous Optimization)和分层缓存(Hierarchical Caching) 机制,减少内存碎片化,提高数据加载速度。
⁉️ DeepSpeed 的 ZeRO 的三个阶段(ZeRO-1/2/3)分别优化了什么?
DeepSpeed 的 ZeRO 的三个阶段(ZeRO-1/2/3)分别优化了什么?
DeepSpeed 的 Zero Redundancy Optimizer(ZeRO) 是一个旨在优化大规模模型训练的高效分布式优化器,通过 减少内存冗余 来提升模型训练效率。ZeRO 分为三个阶段(ZeRO-1、ZeRO-2 和 ZeRO-3),每个阶段分别针对不同的内存优化进行改进:
- ZeRO-1 (Optimizer State Partitioning):在 ZeRO-1 阶段,优化器的状态(例如动量和自适应矩阵)被划分和分布到不同的设备上,而不是在每个设备上复制完整的优化器状态。通过这一分配,内存消耗得到了显著降低,使得每个设备只保存自己负责的部分,减少了内存冗余(Optimizer State Redundancy)。
- ZeRO-2 (Gradient Partitioning):ZeRO-2 进一步优化了梯度存储,除了对优化器状态进行分布外,还将梯度(Gradients)分布到多个设备上。通过这种方式,梯度的内存也得到了有效的分配和压缩,避免了各设备间的冗余存储,从而提高了训练过程中的内存效率和计算效率。
- ZeRO-3 (Parameter Partitioning):ZeRO-3 是 ZeRO 的最全面阶段,它不仅优化了优化器状态和梯度,还对 模型参数(Model Parameters)进行分布式管理。每个设备只存储一部分模型参数,这样即使在非常大的模型中,每个设备都不会承担完整参数集的存储任务,进一步降低了内存开销,提升了可扩展性(Scalability)。
ZeRO 的三个阶段是按顺序进行的。每个阶段的优化是对前一个阶段的扩展和增强,逐步减少内存冗余,从而提升大规模模型训练的效率和可扩展性。
✅ 混合精度训练(FP16、BF16)
⁉️ 单精度浮点(FP32)和半精度浮点(FP16或BF16)?
单精度浮点(FP32)和半精度浮点(FP16或BF16)?
单精度浮点(FP32, Single-Precision Floating Point)和半精度浮点(FP16, Half-Precision Floating Point)或BF16(BFloat16, Brain Floating Point 16)是两种不同的浮点数表示方式,主要用于深度学习计算和高性能计算中。
- FP32 使用 32 位存储一个浮点数,其中 1 位用于符号位(Sign Bit),8 位用于指数位(Exponent),23 位用于尾数(Mantissa),提供较高的精度和动态范围,因此在大多数计算任务中作为默认精度。
Note:指数位和尾数位的作用
- 指数位(Exponent) 控制数的大小(决定它是 2^3 、 2^{-5} 还是 2^{100} )。
- 尾数位(Mantissa) 控制数的精度(决定它是 1.25、1.75、1.875 还是 1.999)。
- 指数大 → 这个数更大,尾数多 → 这个数更精确。
FP16 采用 16 位存储,其中 1 位是符号位,5 位是指数位,10 位是尾数位,精度较 FP32 低,但计算速度更快,主要用于加速神经网络推理(Inference)和训练时的混合精度训练(Mixed-Precision Training)。
BF16 也是 16 位格式,但采用 8 位指数位和 7 位尾数位,相比 FP16 牺牲了一些精度,但保留了 FP32 近似的动态范围,使其在深度学习任务中更稳健,特别适用于 TPU 和部分 GPU 训练优化。
通常,深度学习框架(如 PyTorch、TensorFlow)默认使用 FP32 进行计算,而在优化训练或推理时,可以切换到 FP16 或 BF16 以减少显存占用并提高计算速度。
⁉️ 什么是混合精度训练?
什么是混合精度训练?
混合精度训练(Mixed Precision Training) 是一种通过在深度学习模型训练过程中同时使用 单精度浮点(FP32) 和 半精度浮点(FP16或BF16) 来加速计算并减少内存占用的技术。由于半精度浮点在现代GPU(如NVIDIA Tensor Cores)上可以提供更高的计算吞吐量(Throughput)并降低显存(VRAM)占用,混合精度训练能够在保持模型精度的同时,提高训练效率。
具体而言,混合精度训练的关键组件包括:
- 自动混合精度(Automatic Mixed Precision, AMP):一种由深度学习框架(如PyTorch和TensorFlow)提供的自动化工具,可在关键计算过程中动态选择FP16或FP32进行计算,以保证数值稳定性。
Note:在实际使用中,AMP可以自动调整大部分混合精度操作,因此通常不需要手动设定精度。它通过动态调整浮点数精度来提升计算效率和降低显存占用。其核心策略包括:
- 使用FP16(半精度浮点数)和FP32(单精度浮点数)混合计算:权重参数通常存储为FP32以保持数值稳定性,而计算过程中尽可能使用FP16以提高吞吐量。
- 自动精度管理:框架如 PyTorch 的
torch.cuda.amp或 TensorFlow 的tf.keras.mixed_precision提供了AMP功能,可自动处理FP16计算并确保数值稳定性。- 层级精度控制(Layer-wise Precision Control):某些特定层(如归一化层BatchNorm)仍需FP32计算,以防止数值不稳定。
- 损失缩放(Loss Scaling):由于FP16精度较低,可能会导致梯度值过小而下溢(Underflow),因此通常需要将损失值(Loss)乘以一个较大的缩放因子(Scaling Factor),在反向传播(Backpropagation)时再进行相应缩放,以避免数值精度问题。
- 张量核心(Tensor Cores):在NVIDIA GPU中,专门用于加速混合精度计算的硬件单元,使FP16计算比FP32计算更加高效。
混合精度训练的主要优势包括更快的计算速度(由于FP16计算效率更高)、更低的显存占用(使得可以训练更大的模型或增大Batch Size),以及在某些情况下甚至能提升模型的收敛性。
⁉️ 混合精度训练(FP16/FP32)中 Loss Scaling 的作用?
混合精度训练(FP16/FP32)中 Loss Scaling 的作用?
在混合精度训练(Mixed Precision Training,通常涉及 FP16 和 FP32)中,Loss Scaling(损失缩放)用于缓解数值精度问题,特别是 防止梯度在反向传播时由于 FP16 计算的动态范围较小而下溢(Underflow)。由于 FP16(16-bit Floating Point)表示的最小非零数相比 FP32(32-bit Floating Point)要大得多,小梯度可能会被截断为零,导致 梯度消失(Gradient Vanishing) 问题。
因此,Loss Scaling 通过在计算损失(Loss)时 乘以一个较大的缩放因子(Scaling Factor,例如 1024 或 65536),使得反向传播时的梯度值变大,避免由于精度限制导致的信息丢失。随后,在梯度更新前,会将梯度除以相同的缩放因子,以恢复其原始的数值范围。这种方法确保了梯度计算的稳定性,同时充分利用 FP16 计算的速度和内存优势,提高训练效率。
高效微调技术 #
⭐ 监督微调(Supervised Fine-Tuning)
⁉️ 监督微调(SFT)与预训练(Pre-training)的核心区别是什么?为什么需要 SFT?
监督微调(SFT)与预训练(Pre-training)的核心区别是什么?为什么需要 SFT?
预训练(Pre-training) 是 LLM 训练的第一阶段,通常采用 无监督学习(Unsupervised Learning) 或 自监督学习(Self-Supervised Learning) 方式,使用大规模的通用文本数据(如网页、书籍、论文)来训练模型,使其学习 通用的语言表示(General Language Representations)。常见的预训练目标包括 自回归语言建模(Autoregressive Language Modeling, 如 GPT 系列) 和 掩码语言模型(Masked Language Modeling, 如 BERT)。该阶段的主要目的是让模型捕获语言的统计规律、语法结构和基本知识,但不会对特定任务进行优化。
监督微调(Supervised Fine-Tuning, SFT) 则是在预训练后的基础上,使用 带标签的任务特定数据(Labeled Task-Specific Data) 进行训练,以使模型适应特定的应用场景,例如文本分类、机器翻译、代码生成等。SFT 采用 监督学习(Supervised Learning),其目标函数通常是 交叉熵损失(Cross-Entropy Loss) 或其他适用于任务的损失函数。该阶段的训练数据通常由人类标注,或者由较小规模的高质量数据集构成,以提升模型在特定任务上的性能和对齐能力(Alignment)。
⁉️ 为什么需要 监督微调(SFT)?
为什么需要 监督微调(SFT)?
大模型(如 LLaMA、GPT)需要监督微调(Supervised Fine-Tuning, SFT),主要原因是预训练模型虽然掌握了广泛的语言知识,但在特定任务上的表现往往不够精准,**缺乏任务对齐(Task Alignment)和人类偏好(Human Preference)的优化**。具体而言,主要有以下几点原因:预训练模型仅具备通用语言能力,无法精准执行特定任务:预训练(Pre-training)通常使用大规模无标签的互联网文本数据,模型学到的是语言的统计规律、句法结构和基本的世界知识,但并没有针对具体任务(如对话、代码生成、医学诊断)进行优化。因此,直接使用预训练模型可能会导致 输出不可控、不符合任务需求,甚至产生幻觉(Hallucinations)。
提升对齐性(Alignment)和用户体验:即使预训练模型能够给出合理的回答,其表达方式可能不符合用户期望,或者提供的信息缺乏清晰的逻辑结构。通过 SFT,模型可以更好地对齐人类偏好,例如提高可读性、增强对话的连贯性、减少重复信息,从而提升用户体验。
特定领域任务需要专门优化:某些任务(如法律、医学、金融等)需要高精度和专业知识,而预训练模型仅基于通用文本进行学习,可能无法满足高要求的专业应用。SFT 通过高质量、特定领域的数据对模型进行微调,使其在目标任务上表现更好。例如,训练医疗大模型时,可以使用医生标注的病例数据进行 SFT,使其在医学问答任务上更可靠。
⁉️ 什么是对齐(Alignment)问题?
什么是对齐(Alignment)问题?
Model Alignment 的核心目标是 让AI系统的行为与设计者的意图或人类价值观保持一致,避免出现有害、偏见或不可控的输出。根据具体方向,可分为两类:
- 伦理对齐(Ethical Alignment):
- 定义:确保AI系统在目标、决策和输出中符合人类伦理、道德和社会规范(如安全、公平、透明)。
- 关键挑战:
- 价值观冲突:不同文化、群体间的伦理标准差异。
- 长链推理中的一致性:复杂任务中多步决策的价值观连贯性。
- 可扩展性:将人类价值观高效泛化到未知场景。
- 技术对齐(Technical Alignment)
- 定义:解决模型内部组件或多任务目标之间的协调问题,例如:
- 多模态学习中不同模态(文本、图像)的特征对齐。
- 多任务学习时不同目标函数的平衡。
- 跨模型协作中的行为一致性(如多个AI代理合作)。
- 关键挑战:模态差异、任务冲突、知识迁移效率。
- 定义:解决模型内部组件或多任务目标之间的协调问题,例如:
⁉️ 技术对齐(Technical Alignment)的技术挑战?
技术对齐(Technical Alignment)的技术挑战?
多模态特征对齐:在多模态学习(如文本-图像联合建模)中,不同模态(文本、图像、音频等)的数据结构和语义空间差异巨大,需对齐特征以实现跨模态理解(例如:让模型理解“猫”的文本描述与其图像的关联)。
技术挑战:
- 模态差异 (Modality Discrepancy): 文本是离散符号序列,而图像是连续像素空间,二者的语义关联复杂。
- 噪声关联 (Noisy Association): 不同模态的数据可能包含冗余或冲突的信息,比如文本描述和图像内容不符。
- 计算效率 (Computational Efficiency): 跨模态联合训练的计算开销高,且需要在不同模态之间进行高效的特征对齐。
解决思路:
- 对比学习 (Contrastive Learning, CL): 例如CLIP(Contrastive Language-Image Pre-Training)模型,通过对比正负样本对,将匹配模态的特征向量拉近,促进文本嵌入和图像嵌入之间的语义对齐。
- 跨模态注意力机制 (Cross-modal Attention Mechanism): 通过动态分配注意力权重,捕捉不同模态之间的关键关联,像是根据文本中的关键词对图像区域进行对齐。
- 知识蒸馏 (Knowledge Distillation): 用大模型对齐特征并将其指导到轻量化模型上,从而减少计算开销并提高模型在多模态任务上的表现。
多任务目标平衡 (Multi-task Objective Balancing):在多任务学习中,模型需要同时优化多个目标(如分类、生成、检测等),然而这些任务的损失函数可能存在冲突。例如,提升分类精度可能会降低生成任务的流畅性。
技术挑战:
- 任务优先级冲突 (Task Priority Conflict): 不同任务的优先级可能随时间变化,尤其在实时应用中需要优先保证某些任务的响应时间(如低延迟)。
- 梯度冲突 (Gradient Conflict): 不同任务的梯度方向可能不一致,导致优化过程中出现震荡或难以收敛。
解决思路:
- Pareto优化 (Pareto Optimization): 寻找多任务损失的帕累托前沿(Pareto Front),即在不损害任何任务的情况下最大化其他任务的优化。
- 动态权重调整 (Dynamic Weight Adjustment, e.g., GradNorm): 根据每个任务的难度动态调整损失函数的权重,从而平衡任务间的梯度影响,避免某个任务过度主导优化过程。
跨模型协作一致性 (Cross-model Collaboration Consistency):在多个AI代理(如自动驾驶车辆、多机器人系统)协作完成任务时,每个代理的策略可能存在不一致。例如,两辆自动驾驶车可能同时抢占同一车道,导致策略冲突。
技术挑战:
- 通信限制 (Communication Constraints): 代理间的信息交换可能会延迟,或由于带宽限制而受限,影响协作效率。
- 环境动态性 (Environmental Dynamics): 外部环境的变化(如突发障碍物)可能要求代理实时调整其策略以应对新的情况。
- 目标分歧 (Goal Divergence): 个体目标与全局目标可能发生冲突,如一个机器人可能追求效率,而整个系统的目标是确保安全性。
解决思路:
- 分布式共识协议 (Distributed Consensus Protocol): 基于去中心化通信(例如使用区块链技术),通过协议达成代理之间的策略共识。
- 共享价值函数 (Shared Reward Function): 设计联合奖励函数,鼓励所有代理最大化共同利益,例如在多智能体强化学习(Multi-agent Reinforcement Learning, MARL)中的集中式训练-分布式执行框架。
- 联邦学习 (Federated Learning): 在保护隐私的前提下,允许多个代理通过参数共享协作,从而提升协作模型的一致性和性能。
⁉️ 如何设计高质量的SFT数据集?SFT 数据的典型结构是什么?
如何设计高质量的SFT数据集?SFT 数据的典型结构是什么?
在 监督微调(Supervised Fine-Tuning, SFT)过程中,数据构建的核心在于提供高质量的输入-输出(input-output) 对,以便大模型在特定任务上学习到精准的映射关系。为了设计高质量的SFT数据集,需要遵循以下关键原则:
- 任务对齐(Task Alignment):确保数据严格符合目标任务,例如,在对话任务中,数据应包含多轮交互,而非单轮问答,以增强上下文理解能力。
- 数据平衡(Data Balance):避免数据分布偏差,例如,在代码生成任务中,需涵盖多种编程语言,而非仅训练在Python上,否则会导致模型对其他语言的生成能力不足。
- 标注一致性(Annotation Consistency):确保数据标注风格统一,避免因不同标注者的偏差影响模型收敛。例如,在情感分析任务中,“积极”与“消极”应有明确的定义,不能因主观因素导致标注标准不一致。
- 指令增强(Instruction Augmentation):在构建指令微调(Instruction Tuning)数据时,应增加多样化的指令表达方式,使模型能理解不同的任务描述,而非仅匹配固定的指令模板。
- 对话式SFT数据的典型结构
{
"messages": [
{"role": "system", "content": "你是一个专业的Python编程助手,擅长提供代码示例。"},
{"role": "user", "content": "请写一个Python函数来计算斐波那契数列。"},
{"role": "assistant", "content": "好的,以下是一个递归实现的Python函数:\n\n```python\ndef fibonacci(n):\n if n <= 0:\n return 0\n elif n == 1:\n return 1\n else:\n return fibonacci(n-1) + fibonacci(n-2)\n```"},
{"role": "user", "content": "这个实现效率太低了,你能优化它吗?"},
{"role": "assistant", "content": "当然!可以使用动态规划来优化,提高计算效率:\n\n```python\ndef fibonacci_dp(n):\n if n <= 0:\n return 0\n dp = [0, 1] + [0] * (n-1)\n for i in range(2, n+1):\n dp[i] = dp[i-1] + dp[i-2]\n return dp[n]\n```"}
]
}
⁉️ SFT通常使用哪些损失函数(如交叉熵、序列级损失)?为什么?
SFT通常使用哪些损失函数(如交叉熵、序列级损失)?为什么?
SFT(Supervised Fine-tuning,监督微调)通常使用 交叉熵损失(Cross-Entropy Loss) 和 序列级损失(Sequence-Level Loss),主要是为了优化语言模型(LLM)的文本生成质量。
- 交叉熵损失(Cross-Entropy Loss):交叉熵损失是最常用的损失函数之一,它用于衡量模型输出的概率分布与真实分布之间的差异。在 SFT 过程中,给定输入序列 x ,模型生成的输出序列 y 的概率分布 P(y|x) 应尽可能接近真实数据的分布 P^(y|x) 。其数学公式如下:
在实际应用中,通常将真实标签视为 one-hot 分布,则损失可以简化为:
\[ L_{\text{CE}} = -\sum_{t=1}^{T} \log P(y_t^|x) \]其中 T 是序列长度, y_t^ 是真实标签, P(y_t^|x) 是模型对 y_t^ 的预测概率。交叉熵损失能够有效地指导模型学习 token 级别的准确性。
- 序列级损失(Sequence-Level Loss):序列级损失 关注整个生成序列的质量,而非单个 token 级别的准确性。这类损失函数通常基于 强化学习(Reinforcement Learning, RL) 方法,如 最小风险训练(Minimum Risk Training, MRT) 和 奖励加权最大似然(Reward-Weighted Maximum Likelihood, RWML),它们优化目标函数来最大化最终生成序列的质量。例如,在 最小风险训练(MRT) 中,目标是最小化基于评估指标(如 BLEU、ROUGE)的损失:
其中 Y 是所有可能的生成序列集合, \Delta(y, y^) 是评估损失(如 BLEU 评分的负值),使得模型生成的序列 y 与真实序列 y^* 尽可能接近。而在 强化学习方法(如 REINFORCE 算法) 中,基于策略梯度的方法可以优化模型生成的完整序列:
\[ \nabla_{\theta} L = -\mathbb{E}{y \sim P{\theta}(y|x)} [R(y) \nabla_{\theta} \log P_{\theta}(y|x)] \]其中 R(y) 是基于某种评价指标(如 GPT-4 评分)的奖励值, P_{\theta}(y|x) 是模型的策略分布。
⁉️ 是否需要在SFT阶段冻结部分模型参数?
是否需要在SFT阶段冻结部分模型参数?
在 SFT(Supervised Fine-Tuning,监督微调) 阶段,是否需要冻结部分模型参数取决于具体的任务需求、计算资源以及期望的模型泛化能力。一般来说,有以下几种情况会选择冻结部分参数:
- 避免灾难性遗忘(Catastrophic Forgetting):对于已经经过预训练(Pretraining)的大语言模型(LLM, Large Language Model),完全更新所有参数可能会导致模型丧失之前学习到的通用知识,特别是在数据量较小或分布差异较大的任务上。冻结底层 Transformer层(Transformer Layers) 的参数可以保留模型的基础语言能力,同时仅微调上层以适应新任务。
- 减少计算开销(Computational Efficiency):冻结部分参数可以显著降低训练所需的 显存(VRAM)和计算资源,从而提升训练效率。这在大规模模型(Large-Scale Models)上尤为重要,特别是当计算资源有限时,可以仅调整适配模块(Adapter Layers)或前馈网络(Feed-Forward Networks, FFN) 的部分权重。
- 提高稳定性(Training Stability):完全解冻所有参数可能会导致梯度更新过大,使得模型训练不稳定,甚至出现梯度爆炸(Gradient Explosion)或梯度消失(Gradient Vanishing)。冻结底层层并仅调整高层参数,或者采用 低秩适配(LoRA, Low-Rank Adaptation) 等技术,可以更稳健地调整模型。
⁉️ SFT如何导致模型遗忘预训练知识?有哪些缓解方法?
SFT如何导致模型遗忘预训练知识?有哪些缓解方法?
在 Supervised Fine-Tuning (SFT) 过程中,模型可能会发生 灾难性遗忘(catastrophic forgetting),即模型在学习新任务时,会丧失在 预训练(pretraining)阶段学到的知识。这是因为在 SFT 阶段,模型权重更新的过程中,新的任务会使得原本用于 语言建模 或 通用任务 的知识被改变,从而导致模型无法保留预训练时的有效信息。为了缓解这种遗忘现象,可以采取以下几种方法:
- 回放缓存(Replay Buffer / Experience Replay):回放缓存方法通过保存和定期回放部分 预训练数据 或 历史数据 来保持预训练任务的知识。这种方法利用了以前数据的样本,防止模型在 SFT 过程中完全忘记它所学的内容。通过这种方式,模型在学习新任务时可以同时进行适当的记忆保持,从而减轻灾难性遗忘。
- 弹性权重固化(Elastic Weight Consolidation, EWC):弹性权重固化是一种通过正则化的方式来控制模型权重更新的技术。EWC 通过计算新任务与旧任务之间的 权重重要性 来为每个权重分配一个弹性系数,在进行新任务的训练时,惩罚那些对预训练任务非常重要的权重更新,防止它们发生过大的变化,从而保护模型的原始知识。这可以有效减少灾难性遗忘,尤其是在多任务学习或 逐步学习(sequential learning)中。
- 多任务学习(Multi-task Learning):多任务学习通过在同一模型中并行训练多个任务,可以有效避免灾难性遗忘。通过设计合理的 任务权重(task weighting)和 共享表示(shared representations),可以确保模型在学习新任务时保留预训练任务的知识。模型同时在多个任务上进行优化,使得各任务之间的信息得以保持和共享
⭐ 参数高效微调(LoRA、Adapter、Prefix Tuning)
⁉️ 什么是参数高效微调(PEFT)?其核心目标是什么?
什么是参数高效微调(PEFT)?其核心目标是什么?
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)是一种优化深度学习模型微调(fine-tuning)效率的方法。与传统的微调方法不同,PEFT的 核心目标是通过仅调整模型中的少量参数,来实现下游任务的性能提升,而不是对整个模型进行全参数调整。这种方法通常包括 冻结预训练模型的大部分参数,仅微调一些特定层或子模块,从而在保持较低计算开销的同时,仍能得到较好的任务表现。PEFT常用于大规模预训练语言模型(如GPT、BERT等)的微调过程中,尤其适用于资源有限的场景,或者当处理多个任务时,能够实现快速适应和高效的迁移学习(transfer learning)。
⁉️ PEFT 在训练速度和显存占用上的优势是如何实现的?
PEFT 在训练速度和显存占用上的优势是如何实现的?
PEFT(Parameter-Efficient Fine-Tuning)通过减少模型参数的更新来优化训练速度和显存占用。与传统的微调方法(full fine-tuning)不同,PEFT不需要对整个预训练模型(pre-trained model)进行参数更新,而是通过对少量特定的参数进行微调,通常是通过对层级适配器(adapter layers)或者其他轻量级模块的微调。这样,尽管模型的参数量保持较大,但在训练过程中所需更新的参数量却大大减少,进而减少了计算资源和显存(GPU memory)的需求。
具体实现方式通常有两种:一是只微调少数权重,如权重矩阵的低秩分解(low-rank decomposition),或通过增设适配器模块(adapter modules)对输入输出进行微调。另一种方式是 利用冻结大部分模型层的参数(freezing most layers),只更新与任务相关的小范围参数。这些方式都能有效减少每次迭代需要的计算量,从而提高训练效率,并显著降低显存占用。
⁉️ 什么是 Prompt Tuning?
什么是 Prompt Tuning?
Prompt Tuning 是一种 参数高效微调(Parameter-Efficient Fine-tuning, PEFT) 方法,它通过学习一组 可训练的提示向量(Trainable Soft Prompts),在不修改大语言模型(LLM, Large Language Model)原始参数的情况下,引导模型执行特定任务。这种方法相比于 完整微调(Full Fine-tuning),只需要优化少量参数,从而减少计算成本并提高适配效率。
在 Prompt Tuning 中,给定一个 预训练的 LLM,其原始输入表示为:X = (x_1, x_2, …, x_n)。在 Prompt Tuning 过程中,我们引入一个 可训练的连续向量(Soft Prompt),记为:P = (p_1, p_2, …, p_m)。其中, P 是一组 可训练的嵌入向量(Trainable Embeddings),与 离散 token 不同,它们不与任何特定词汇表绑定,而是通过优化得到的连续向量。最终,模型的输入变为:
\[ X^{\prime} = (p_1, p_2, …, p_m, x_1, x_2, …, x_n) \]Prompt Tuning 训练的目标是 最小化任务特定的损失函数(Task-Specific Loss),如 交叉熵损失(Cross-Entropy Loss):
\[ \mathcal{L} = -\sum_{i=1}^{N} y_i \log(\hat{y_i}) \]Example:
- 传统离散 Prompt(Discrete Prompting)
"The movie was fantastic! Sentiment: [MASK]"
在这种方法中,[MASK] 依赖于手工设计的提示,而不是模型自动优化的。
- Prompt Tuning 的 Soft Prompt
[P1] [P2] [P3] "The movie was fantastic!" → "Positive"
其中 [P1] [P2] [P3] 是可训练的向量,模型会学习如何利用这些向量来引导输出 Positive。
⁉️ 什么是 Prefix-Tuning?Prefix Tuning 和 Prompt Tuning 的区别是什么?
什么是 Prefix-Tuning?Prefix Tuning 和 Prompt Tuning 的区别是什么?
Prefix-Tuning 是一种参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,专门用于调整大语言模型(LLM, Large Language Model)的行为,同时避免对整个模型进行微调。其核心思想是,在模型输入的 注意力层(Attention Layers) 之前添加一组 可训练的前缀向量(Trainable Prefix Vectors),从而引导模型在特定任务上表现更好。
与 Prompt Tuning 类似,Prefix-Tuning 也是一种利用 连续嵌入(Continuous Prompts) 的方法,但它的 关键区别 在于:
- Prompt Tuning 仅优化输入嵌入层的前缀,而
- Prefix-Tuning 直接优化 Transformer 网络的每一层注意力机制的前缀,让它们影响整个推理过程。
Prefix-Tuning 的核心在于在 Transformer 的 多头自注意力(Multi-Head Self-Attention, MHSA) 机制中引入 可训练的前缀向量。在 所有层 的 Key(K)和 Value(V) 之前插入可训练的前缀向量 P_K 和 P_V :
\[ K^{\prime} = [P_K; K], \quad V^{\prime} = [P_V; V] \]P_K, P_V 是 Prefix-Tuning 训练得到的 固定长度前缀参数,并且不依赖于原始输入文本。这些前缀参数会在训练过程中进行优化,但原始模型参数保持不变。最终,注意力计算变为:
\[ \text{Attention}(Q, K^{\prime}, V^{\prime}) = \text{softmax} \left( \frac{QK{\prime}^T}{\sqrt{d}} \right) V^{\prime} \]这种方式让 Prefix-Tuning 能够引导 LLM 在下游任务上表现更好,而无需修改整个模型的参数。
Prefix Tuning 影响的是隐藏层的注意力机制,适用于生成任务,而 Prompt Tuning 直接作用于输入嵌入,更适用于下游任务。
⁉️ LoRA的核心思想是什么?如何通过低秩分解实现参数高效?
LoRA的核心思想是什么?如何通过低秩分解实现参数高效?
LoRA(Low-Rank Adaptation)的核心思想是通过 引入低秩矩阵分解 来高效地适应预训练语言模型(如Transformer)中的大规模参数。在传统的模型微调过程中,需要调整大量的模型参数,尤其是在大规模语言模型(LLM, Large Language Models)中,这种方法会非常计算和存储密集。LoRA的创新在于它通过在模型参数矩阵的基础上引入低秩矩阵,减少了需要调整的参数数量,从而大幅提高了参数效率和训练速度。
假设你有一个预训练的语言模型,其中的一个权重矩阵 W 需要进行微调。原始的权重矩阵 W 具有大小 m x n (例如, m 是输入维度, n 是输出维度)。在传统的微调中,我们会对整个 W 进行更新,而在LoRA中,我们使用低秩分解的方法来减少更新的参数数量。
LoRA通过将权重矩阵 W 分解为两个低秩矩阵 A 和 B ,从而使得参数的更新更加高效。假设低秩矩阵的秩为 r ,则可以将 W 表示为:
\[ W^{\prime} = W + \Delta W = W + A \cdot B \]其中, A 是一个大小为 m x r 的矩阵, B 是一个大小为 r x n 的矩阵, r 是设定的秩,通常 r « (m, n) 。传统的微调方法需要更新整个 W 矩阵中的所有 m x n 个参数,而LoRA只需要更新 A 和 B 中的 m x r + r x n 个参数。因此,LoRA的参数量减少了大约 (m x n - m x r - r x n) 个参数,这对于大规模模型(如GPT、BERT等)尤为重要,能够显著降低计算和存储开销。
⁉️ LoRA通常作用于Transformer的哪些层?为什么选择这些层?
LoRA通常作用于Transformer的哪些层?为什么选择这些层?
LoRA(Low-Rank Adaptation)通常作用于Transformer模型中的 attention layers(注意力层)和feed-forward layers(前馈层)。LoRA的核心思想是在这些层的权重矩阵中插入低秩矩阵,从而有效地进行模型的适应和微调。
为什么选择这些层:Transformer模型的主要计算开销和参数量通常集中在注意力机制和前馈神经网络这两部分。特别是self-attention(自注意力)机制中,键(Key)、值(Value)和查询(Query)矩阵的计算和更新是模型中最重要的部分,涉及到大规模的矩阵乘法运算。因此,在这些层插入低秩矩阵,可以以较小的参数量实现对模型的有效调整,而不会显著增加计算开销。同时,这些层对于模型的性能和表达能力至关重要,调整它们可以帮助模型在特定任务上更好地进行迁移学习(transfer learning)和微调。
⁉️ 如何选择LoRA的秩(Rank)?秩的大小如何影响模型性能和计算开销?
如何选择LoRA的秩(Rank)?秩的大小如何影响模型性能和计算开销?
选择LoRA的秩(Rank)通常是一个需要在模型性能和计算开销之间做平衡的过程。秩的大小直接影响LoRA的效果,因为它决定了低秩矩阵的维度,进而影响到模型的可适应性和计算复杂度。
- 影响模型性能:
- 较小的秩:选择较小的秩会显著降低计算开销,因为低秩矩阵的参数量更少。然而,较小的秩可能会限制模型的表达能力,使其在一些任务上的适应性较差,无法捕捉到足够的复杂特征,从而导致性能下降。
- 较大的秩:增大秩可以增加模型的表达能力,允许LoRA适应更多的任务细节,从而提升模型在特定任务上的表现。但过大的秩可能会导致计算开销增大,甚至使得低秩适应的优势不再明显。
- 影响计算开销:
- 计算量与秩的关系:秩的增大会线性增加低秩矩阵的参数量,因此计算量也随之增加。在Transformer中,LoRA通常对矩阵的低秩矩阵进行插入,因此秩的增大会影响计算复杂度,特别是在注意力层(attention layers)和前馈层(feed-forward layers)中。
- 如何选择合适的秩:
- 实验验证:通常,通过在不同秩的情况下进行多次实验,评估模型的表现,并根据性能和计算开销的权衡来选择最合适的秩。
- 任务依赖性:对于不同的任务,秩的选择也可能不同。例如,对于一些复杂的生成任务,较大的秩可能有助于捕捉更多的语义信息,而对于一些较为简单的任务,较小的秩即可达到良好的效果。
- 预训练模型的影响:在基于预训练模型进行微调时,通常可以选择较小的秩,因为预训练模型已经有了良好的表征能力,微调时无需大幅调整模型。
⁉️ 什么是QLoRA?他和LoRA有什么区别?
什么是QLoRA?他和LoRA有什么区别?
QLoRA(Quantized Low-Rank Adaptation)是一种优化大规模预训练语言模型(LLMs)微调的方法,它结合了量化(quantization)和低秩适配(low-rank adaptation)技术。QLoRA通过量化模型的参数来减少存储和计算的需求,并采用低秩矩阵分解技术进行模型的微调,从而实现更高效的资源利用和计算优化。量化步骤使得模型在微调时可以使用较少的内存和计算资源,而低秩适配则保持了模型的表达能力,能够在不显著降低性能的情况下,进行高效的任务特定适配。
与QLoRA不同,LoRA(Low-Rank Adaptation)专注于通过低秩矩阵分解来对预训练模型进行微调。在LoRA方法中,模型参数不会被量化,而是通过低秩矩阵表示来减少微调时的参数量。LoRA通过这种方式减少了计算和存储需求,但其内存和计算消耗可能比QLoRA稍高,因为LoRA没有引入量化机制。
因此,QLoRA相对于LoRA的优势在于,它在低秩适配的基础上,增加了量化技术,使得模型微调在计算和存储上更加高效,尤其适用于内存受限或计算资源有限的情况。
⁉️ Adapter模块的标准结构是什么(如瓶颈层设计)?
Adapter模块的标准结构是什么(如瓶颈层设计)?
Adapter模块 是一种轻量级的神经网络结构,主要用于在预训练的大型模型(如BERT、GPT等)基础上进行迁移学习。其核心思想是 在不修改模型大部分参数的情况下,通过插入小型的适配层(Adapter)来实现对新任务的适应,从而节省计算资源和减少训练时间。
Adapter模块通过添加几个小型的层(通常包括瓶颈层和非线性激活层)来对原有模型进行微调。通常,它会插入到预训练模型的某些层之间(如Transformer模型的每个Encoder层),仅修改这些插入的部分,而保持大部分预训练参数不变。
Adapter模块的标准结构通常包括以下几个核心组件:首先是输入层(Input Layer),它将输入特征传递给后续的模块;然后是 瓶颈层(Bottleneck Layer),该层是Adapter的关键部分,通过减少维度来限制参数的数量,从而提升训练效率和降低计算开销。瓶颈层通常包含一层较小的隐藏层(Hidden Layer),该层将输入数据的维度映射到一个较低的空间,接着是一个激活函数(Activation Function),常用ReLU(Rectified Linear Unit)等非线性激活函数。接下来是输出层(Output Layer),其目的是将特征转换回原始空间的维度,供下游任务使用。为了避免模型过拟合,Adapter模块通常会在瓶颈层和输出层之间引入跳跃连接(Residual Connection),这有助于稳定训练过程,并确保重要特征信息能够有效传播。最后,Adapter模块常配合预训练的语言模型使用,以使得模型在不大幅改变预训练参数的情况下,适应新的任务或领域。Adapter模块的流程一般为:
- 冻结大部分预训练模型的参数:在fine-tuning过程中,除了Adapter模块的参数外,预训练模型的其他参数(如Transformer的层、Attention机制的权重等)保持不变,不参与训练。这使得我们只需要训练少量参数,显著减少了训练成本。
- 插入Adapter模块:Adapter模块插入到预训练模型的各层中。在每个Transformer层之间插入一个Adapter,通常是在自注意力机制和前馈神经网络层之间。这些适配器通常只包含少量的参数,例如一个瓶颈层(较低维度)和投影层。假设原始Transformer层的输入维度是 d ,瓶颈层的维度通常会被压缩到 d’ ,其中 d’ 很小。例如,在一个标准的BERT模型中,假设BERT的每一层有 d 维的输出,而Adapter会通过一个瓶颈层将这个 d 维度压缩为一个更小的维度 d’,然后通过投影层恢复到原始维度 d 。公式上可以表示为:
- 训练Adapter模块:在Adapter模块中,参数(如权重 W1 和 W2 )是唯一在fine-tuning过程中更新的部分,而原始BERT模型的其他参数保持冻结。这使得模型能够专注于从新任务的数据中学习最相关的特征,同时保持预训练的通用知识。
- 通过残差连接(Residual Connection)保证信息流:Adapter模块通常使用残差连接来将原始输入信号和Adapter的输出相加。这种设计不仅能让网络更深(更易学习复杂的特征),而且能防止梯度消失问题,确保信息流可以有效地通过网络传递。这样即使Adapter的参数很小,原始模型的表现也不会受到太大影响。
⁉️ LoRA 与 Adapter 在参数量、计算开销和效果上的差异?能否同时使用?
LoRA 与 Adapter 在参数量、计算开销和效果上的差异?能否同时使用?
LoRA (Low-Rank Adaptation) 和 Adapter 是两种常用于大规模预训练语言模型(LLM)微调的方法,它们在参数量、计算开销和效果方面有一些显著的差异。
- 参数量 (Parameter Count):
- LoRA:LoRA通过在预训练模型的权重矩阵中引入低秩矩阵分解,旨在减少需要微调的参数数量。LoRA不会修改原始模型的参数,而是通过学习低秩矩阵来调整模型的表现,因此它能够在不增加大量参数的情况下实现有效的微调。
- Adapter:Adapter方法通过为每一层的神经网络添加一个小的适配模块来微调模型。每个适配器模块通常由几个层组成,这会增加模型的总参数量,但这个增量相对较小,因为只有适配器层的参数需要被训练。
- 计算开销 (Computational Overhead):
- LoRA:由于LoRA引入了低秩矩阵,计算开销较小,尤其是在需要微调的任务中,计算效率得到了提高。这是因为LoRA只需要对新增的低秩矩阵进行训练,而不需要反向传播整个模型的所有参数。
- Adapter:Adapter方法虽然增加了参数量,但相对于全量微调,它仍然保持较低的计算开销。适配器模块的计算主要集中在通过添加额外的层来调整模型,因此计算开销比全量微调要小,但比LoRA稍大。
LoRA和Adapter可以同时使用。这样做的好处是能够结合两者的优势:LoRA通过低秩矩阵减少计算开销并提高效率,而Adapter通过增加层来增强模型对任务的适应性。结合两者可能会提升在某些特定任务上的表现,尤其是在复杂任务中,LoRA和Adapter各自从不同角度优化模型。但有以下可能带来的问题:
- 过拟合 (Overfitting):如果同时使用LoRA和Adapter,可能会导致模型过于复杂,增加了过拟合的风险,尤其是在训练数据较少时。
- 训练稳定性 (Training Stability):LoRA和Adapter的联合使用可能会对训练过程的稳定性产生一定的影响,特别是在调整低秩矩阵和适配器模块时,可能需要精细的超参数调节,以避免训练过程中的不稳定。
- 计算资源 (Computational Resources):尽管LoRA和Adapter比全量微调要节省计算资源,但两者的联合使用仍然会带来额外的计算开销和内存消耗,尤其在处理大规模模型时,可能需要额外的资源来处理这些增加的模块。
⭐ 强化学习微调与对齐(RLHF、PPO、DPO)
⁉️ 什么是基于人类反馈的强化学习(RLHF)?它的主要步骤是什么?
什么是基于人类反馈的强化学习(RLHF)?它的主要步骤是什么?
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)是一种用于训练大规模语言模型(LLM)的方法,它结合了强化学习(Reinforcement Learning, RL)和人类反馈(Human Feedback) 来优化模型的行为,使其更符合人类期望。RLHF通常用于提高模型的可控性、对齐性(Alignment)和用户体验,如 OpenAI 的 GPT 系列模型训练过程中就使用了 RLHF。RLHF 训练过程通常包含三个主要步骤:
监督微调(Supervised Fine-tuning, SFT):首先,使用人工标注的高质量数据集对预训练语言模型(Pretrained Language Model, PLM)进行有监督微调,以便模型学习初步的任务能力。例如,如果任务是对话生成,可以用高质量的人工标注对话对(prompt-response pairs)训练模型,使其能合理生成回答。
奖励模型训练(Reward Model Training, RM):由于强化学习需要一个奖励信号(Reward Signal),但 LLM 生成的文本质量难以直接定义数学函数来评估,因此需要训练一个 奖励模型(Reward Model, RM) 来评分。
- 数据构造:人类标注者会对多个候选回答进行排序(Preference Data),形成数据集 D 。假设有两个回答 y_A, y_B ,标注者认为 y_A 比 y_B 更好,记作 y_A > y_B 。
- 奖励模型(RM)的目标:
- 训练一个神经网络来预测人类偏好的分数(reward score)。
- 例如,关于回答A 和回答B,如果人类标注者更倾向于回答 A,则训练 RM,使 R(A) > R(B) ,从而在后续 RL 训练时鼓励生成更好的回答。
通过强化学习优化(Reinforcement Learning Optimization, PPO):使用 近端策略优化(Proximal Policy Optimization, PPO) 对模型进行强化学习,使其在 RM 评分下表现更优。
- 假设 pi_{\theta}(y | x) 是当前策略(即 LLM 生成文本的分布),目标是最大化奖励。
- 由于直接优化可能导致模型剧烈变化,因此使用 PPO 进行约束优化
Note:强化学习(Reinforcement Learning, RL)的基本概念依然适用,只不过它是在语言模型(LLM)生成文本的环境下进行的:
- 状态(State, s):当前的上下文或输入,即提示词(Prompt)和之前的对话历史。在 RLHF 训练 LLM 时,状态 s 通常指的是模型当前处理的输入文本。
- 动作(Action, a):LLM 生成的下一个单词或完整的回答。
- 环境(Environment, E):评估模型输出并提供奖励的系统,在 RLHF 中主要由奖励模型(Reward Model, RM)和人类反馈组成。传统 RL 中,环境通常是一个物理世界(如机器人控制)或游戏环境,而在 RLHF 训练 LLM 时:环境就是奖励模型(RM),它会对 LLM 生成的文本进行评分。
- 奖励(Reward, r):对 LLM 生成内容质量的评估分数,通常由 奖励模型(RM) 提供。奖励模型 R(x, y) 通过人类标注数据训练,可以对回答的质量进行评分。
- 策略(Policy, pi):LLM 生成文本的概率分布,即决定给定输入下生成哪个 token 或句子的策略。传统 RL 中,策略 表示在状态 s 下采取动作 a 的概率,而在 RLHF 中,就是语言模型的概率分布,表示 LLM 生成某个 token 或句子的概率。训练的目标是 优化策略,使其更符合人类反馈的奖励分布。
- 回报(Return, G):从某个状态出发,模型在整个生成过程中获得的累计奖励。因为 LLM 生成的文本通常是有限步的过程,所以一般不需要长期折扣。
⁉️ RLHF的奖励模型(Reward Model)是如何训练的?
RLHF的奖励模型(Reward Model)是如何训练的?
在强化学习训练大语言模型(LLM)的过程中,奖励模型(Reward Model, RM)的训练通常包括以下几个关键步骤:
- 数据收集(Data Collection):首先,人工标注者或基于已有模型生成一组人类偏好数据(Human Preference Data),通常包含多个候选回复,并由人类标注者进行排序(Ranking)。这些数据用于学习人类偏好,使得模型可以预测哪些输出更符合人类期望。
- 数据处理与特征提取(Data Processing & Feature Extraction):将标注的排名数据转换为二元比较(Pairwise Comparisons)或更复杂的排序信号,并对文本输入进行编码(Tokenization),以便输入到神经网络中。
- 监督训练(Supervised Training):使用深度学习模型(通常是Transformer架构,如BERT或GPT的变体)进行训练。输入通常是文本对(如一个更好的回复和一个较差的回复),目标是让奖励模型学习如何将更优的响应赋予更高的奖励分数(Reward Score)。
- 损失函数(Loss Function):常用的方法是基于 伯努利对数似然(Binary Cross-Entropy Loss)或排序损失(Ranking Loss)的优化目标。例如,给定两个输出 y^+ (更优答案)和 y^- (较差答案),模型通过对比损失(Pairwise Ranking Loss) 来优化,使得 R(y^+) > R(y^-)。
- 优化与正则化(Optimization & Regularization):使用优化器(如Adam或AdamW)调整模型参数,并可能使用 KL散度正则化(KL Divergence Regularization) 来避免过拟合到训练数据,确保奖励模型的泛化能力。
- 模型评估与调优(Evaluation & Fine-tuning):通过A/B测试或与人类偏好对比,评估奖励模型的性能,并调整超参数(如学习率、batch size)以提高预测准确性。
最终训练完成的奖励模型可用于强化学习阶段(如PPO, Proximal Policy Optimization)来指导LLM的优化,使其生成更符合人类偏好的文本。
⁉️ 什么是PPO?它与传统的Policy Gradient方法相比有什么优势?
什么是PPO?它与传统的Policy Gradient方法相比有什么优势?
PPO(Proximal Policy Optimization,近端策略优化) 是一种强化学习(Reinforcement Learning, RL)算法,属于策略梯度(Policy Gradient, PG)方法的一种改进形式。它主要通过限制策略更新的幅度来提高训练的稳定性和样本效率。
PPO的目标是 最大化期望回报(Expected Return),并且通过剪切(Clipping)策略或 信赖域优化(Trust Region Optimization) 的方式限制策略更新的步长,使得新策略不会偏离旧策略过远,以防止训练不稳定。PPO主要有两种变体:
- PPO-Clip: 通过裁剪(Clipping)概率比值来限制策略更新幅度。
- PPO-Penalty: 通过KL散度(Kullback-Leibler Divergence)惩罚项来约束策略变化。
PPO的 优化目标 如下:
\[ J(\theta) = \mathbb{E}_t \left[ \min(r_t(\theta) A_t, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) A_t) \right] \]其中 r_t 是新旧策略的概率比(Probability Ratio)。 A_t 是优势函数(Advantage Function),衡量当前动作相对于平均水平的优劣程度。如果 A(s, a) > 0 ,说明动作 a 比该状态下的平均策略要好,强化学习应鼓励该动作。
\[ r_t(\theta) = \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \\ A(s, a) = Q(s, a) - V(s) \\ \]PPO的目标函数选择了最小值,即当 r_t(\theta) A_t 过大时,裁剪项会限制它的变化,使策略不会偏离太远;当 r_t(\theta) A_t 在合理范围内时,不受裁剪影响。这种机制确保了策略更新既具有足够的灵活性,又能保持稳定性。
Example:假设我们在训练一个机器人进行路径规划,使用传统PG方法时,我们可能会发现它的策略更新剧烈变化,导致训练不稳定,甚至在某些episode中表现极差。而PPO通过裁剪策略,确保新旧策略不会偏离过大,即使在高方差的环境中,也能缓慢而稳定地优化策略,使得最终收敛效果更好。
Note:PPO与传统Policy Gradient的对比:
传统的策略梯度方法,如REINFORCE或TRPO(Trust Region Policy Optimization),存在一定的问题:
- 高方差(High Variance):PG方法依赖于回报的采样,导致梯度估计的方差较大,收敛速度慢。
- 不稳定的策略更新(Unstable Policy Updates):在TRPO中,需要计算费时的二阶导数来保持策略变化的稳定性,而REINFORCE直接使用回报进行梯度更新,可能导致训练不稳定。
- 样本效率低(Sample Inefficiency):在PG方法中,每个样本通常只使用一次,而PPO能够更高效地使用样本。
PPO通过裁剪目标函数解决了上述问题,使得训练更加稳定、高效,并减少了超参数的敏感性。
⁉️ DPO(Direct Preference Optimization)是什么?它如何改进RLHF流程?
DPO(Direct Preference Optimization)是什么?它如何改进RLHF流程?
Direct Preference Optimization (DPO) 是一种用于对齐大语言模型(LLM, Large Language Model)的方法,旨在改进基于人类反馈的强化学习(RLHF, Reinforcement Learning from Human Feedback)流程。DPO 直接在无奖励模型 (reward-free) 设置下优化偏好数据,而无需显式地训练奖励模型或进行强化学习优化,从而避免了 RLHF 训练中的不稳定性和高计算成本。
DPO 通过 最大化偏好数据中首选响应 (preferred response) 与不被偏好的响应 (dispreferred response) 之间的对数概率比 (log probability ratio) 来优化模型。设偏好数据集{D} = { (x, y^+, y^-) } 其中: x 是输入 (prompt),y^+ 是人类偏好的答案 (preferred response),y^- 是被人类标记为较差的答案 (dispreferred response)。DPO 直接优化下面的目标函数:
\[ \mathcal{L}{\text{DPO}} = \mathbb{E}{(x, y^+, y^-) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \cdot \left( \log \pi_\theta(y^+ | x) - \log \pi_\theta(y^- | x) \right) \right) \right] \]DPO 通过直接优化对数概率比而非显式奖励模型,使得训练更加稳定,同时避免了 RLHF 过程中需要采样和估计价值函数的不确定性。
Note:传统 RLHF 流程通常涉及:
- 训练奖励模型 (Reward Model, RM): 使用人类偏好数据训练一个奖励函数 r_\phi(x, y) 。
- 强化学习 (PPO, Proximal Policy Optimization): 通过强化学习(如 PPO)调整 LLM 以最大化奖励模型的得分。
DPO 通过直接最大化偏好数据的概率比,绕过了这两个步骤,避免了:
- 奖励模型偏差 (Reward Model Bias): 由于 DPO 不依赖外部奖励模型,而是内嵌在人类偏好的数据分布中,因此减少了因奖励模型误差带来的训练不稳定性。
- PPO 训练的不稳定性 (Training Instability of PPO): PPO 需要精细调节超参数,训练过程中可能出现梯度爆炸或崩溃,而 DPO 采用简单的对数概率优化,更加稳定。
推理优化(Inference Optimization) #
✅ 缓存机制(KV Cache, Key-Value Caching) FlashAttention
⁉️ FlashAttention 的原理是什么?
FlashAttention 的原理是什么?
FlashAttention 是一种优化的自注意力(Self-Attention)计算方法,旨在提高 Transformer 模型的计算效率,特别是在 GPU 上减少显存(Memory)占用,同时保持精度。它的核心思想是通过 I/O-aware algorithm(输入输出感知算法)减少数据在 GPU 计算单元(SM, Streaming Multiprocessor)与显存(HBM, High Bandwidth Memory)之间的传输开销,从而提高计算效率。
FlashAttention 主要优化的是标准 Scaled Dot-Product Attention(缩放点积注意力)计算:
\[ \text{Attention}(Q, K, V) = \text{softmax} \left(\frac{QK^T}{\sqrt{d_k}}\right) V \]FlashAttention 通过 块(Block-wise)计算 和 行(Row-wise)Softmax 来优化该计算过程,避免整个 QK^T 计算结果(大小为 n x n )全部存入显存,从而减少显存占用。其主要流程如下:
- 分块计算(Block-wise Computation)
- 将 Q, K, V 按块(Block)划分,每次仅加载一个小块的数据到 共享内存(Shared Memory)。
- 计算小块的 QK^T ,并存入 片上寄存器(Registers) 而非显存。
- 行 Softmax 计算(Row-wise Softmax)
- 由于 Softmax 需要归一化,因此 FlashAttention 逐行(Row-wise)计算最大值,以保持数值稳定性(Numerical Stability)。
- 计算 Softmax 分子和归一化 Softmax:
- 流式计算 PV (Streaming Matmul with V)
- 在寄存器级别直接计算 O = PV 而不存入显存,以进一步减少 I/O 负担。
- 反向传播(Backward Pass)优化
- 在反向传播阶段,FlashAttention 只需存储 Softmax 归一化后的 注意力得分(Attention Scores)而不是整个 QK^T 矩阵,进一步减少存储需求。
- 编译器优化(TensorRT, ONNX, vLLM)
- 推理框架
- FlashAttention
模型压缩 #
✅ 模型蒸馏(Knowledge Distillation)
⁉️ 什么是模型蒸馏技术(Model Distillation)?
什么是模型蒸馏技术(Model Distillation)?
模型蒸馏(Model Distillation)是一种 将一个大型、复杂的模型(通常称为“教师模型”)中的知识 转移到一个 较小、较简单的模型(即“学生模型”)中的技术。其核心思想是通过让 学生模型学习教师模型的输出,而不仅仅是训练数据的标签,从而在保持模型性能的同时,减少计算资源的消耗和模型的复杂度。
在蒸馏过程中,教师模型首先在数据上进行训练,并生成预测结果(如类别概率分布)。然后,学生模型通过最小化自己预测和教师模型预测之间的差异(通常使用KL散度,Kullback-Leibler Divergence)来进行训练。这样,学生模型不仅学习训练数据的标签,还学习到教师模型在不同数据样本下的预测模式。
模型蒸馏的应用场景包括加速推理过程、减少内存使用、在边缘设备上部署更轻量级的模型等。它通常被用于深度学习(Deep Learning)领域,特别是在需要进行大规模推理或在硬件资源受限的情况下。
⁉️ 模型蒸馏技术的具体流程步骤细节?
模型蒸馏技术的具体流程步骤细节?
模型蒸馏(Model Distillation)是一种将大型复杂模型(称为“教师模型”)的知识迁移到小型高效模型(称为“学生模型”)的技术,旨在保持学生模型性能的同时显著减少其计算资源和存储需求。它的核心思想是:
- 知识迁移:教师模型通过大量数据和复杂结构学习到的“知识”(如类别间的关系、数据分布)被提炼到学生模型中,而非直接模仿教师的结构。
- 软标签(Soft Targets):教师模型的输出 概率分布(如分类任务中各类别的概率) 比真实标签(硬标签)包含更多信息(如“猫与豹的相似性”),学生模型通过匹配软标签学习更丰富的知识。
具体流程步骤
- 教师模型训练:
- 首先,训练一个高性能的教师模型,该模型通常 较大且复杂(如ResNet-152、BERT-Large)。教师模型在训练数据上进行标准训练,通常使用交叉熵损失函数(Cross-Entropy Loss)进行训练,以获得准确的预测。
- 生成教师模型的软标签(Soft Labels):
- 教师模型完成训练后,对每个输入样本生成一个预测概率分布(通常是通过Softmax函数计算的概率分布)。这些概率分布被称为 软标签(Soft Labels),与传统的硬标签(Hard Labels)不同,软标签包含了更多关于各类别之间的相对关系的信息。
- 在计算学生模型和教师模型的输出差异时,使用一个 温度参数 T 来调节教师模型的输出概率分布的“平滑程度”。通过增加温度 T ,教师模型的输出概率分布会变得更平滑,从而包含更多的类别之间的关系信息。输出层使用带温度参数(Temperature, T)的 Softmax 可以表示为:
学生模型训练:
- 学生模型为 轻量级结构(如MobileNet、TinyBERT)
- 在学生模型训练时,我们不仅使用传统的硬标签(通常是one-hot标签),还让学生模型学习教师模型的软标签。学生模型的目标是通过最小化自己输出的概率分布和教师模型输出之间的差异,来进行训练。为了使学生模型的学习更加准确,通常会加大软标签的“温度”参数(Temperature)。
损失函数:
- 学生模型的损失函数包括两个部分:一部分是传统的交叉熵损失函数(Hard Target Loss),用于训练学生模型的标准标签;另一部分是蒸馏损失(Distillation Loss),用于使学生模型接近教师模型的输出。
- 硬标签损失:学生预测与真实标签的交叉熵(Cross-Entropy, CE)。
- 软标签损失:通常采用KL散度(Kullback-Leibler Divergence)来衡量学生模型输出与教师模型输出之间的差异:它衡量了两个概率分布之间的差异。KL散度的公式为:
- 学生模型的损失函数包括两个部分:一部分是传统的交叉熵损失函数(Hard Target Loss),用于训练学生模型的标准标签;另一部分是蒸馏损失(Distillation Loss),用于使学生模型接近教师模型的输出。
总体损失函数可以表示为:
\[ L_{\text{total}} = \alpha L_{\text{hard}} + \beta L_{\text{soft}} \] \[ L = \alpha \cdot \text{CE}(y_{\text{hard}}, y_{\text{student}}) + (1 - \alpha) \cdot T^2 \cdot \text{KL}(p_{\text{teacher}} \parallel p_{\text{student}}) \]⁉️ DistilBERT 和 TinyBERT 的区别?
什么是模型蒸馏技术(Model Distillation)?
TinyBERT和DistilBERT是两种 基于BERT的压缩模型,它们都旨在减少模型的规模和计算需求,但在方法和策略上有所不同。虽然它们的目标是类似的,但它们的设计理念、训练方法和具体实现方式有一些关键差异。以下是这两者的对比:
- 蒸馏方法
- DistilBERT:DistilBERT采用的是 经典的蒸馏方法,即通过将教师模型(BERT)训练得到的知识传递给一个较小的学生模型。DistilBERT的主要目标是减少层数,即将 BERT的12层(如BERT-Base)压缩为6层,并且保持相对较小的隐藏层维度。此外,DistilBERT通过soft target(软标签)和硬标签(真实标签)一起进行训练,目标是使学生模型尽可能模仿教师模型的输出。
- TinyBERT:TinyBERT则采用了更加精细的蒸馏策略,不仅仅是减少模型的层数和隐藏层维度,还引入了 层间蒸馏(layer-wise distillation)。这意味着在训练过程中,TinyBERT不仅从教师模型的最终输出(soft targets)中学习,还在每一层的表示(中间层)中进行学习,从而能更好地传递教师模型在不同层次上的知识。此外,TinyBERT还使用了知识蒸馏增强(Knowledge Distillation Augmentation),并结合了网络剪枝(network pruning)等技术来进一步提高压缩效率。
- 网络压缩策略
- DistilBERT:DistilBERT主要通过减少Transformer层数来进行压缩。具体来说,DistilBERT将BERT模型的层数从12层减少到6层。这种方式大幅降低了模型的计算复杂度,并使得DistilBERT的模型大小比BERT小一半,但仍能保持较好的性能。DistilBERT的结构压缩主要是通过减少网络深度来实现的。
- TinyBERT:TinyBERT的压缩策略则更加多样化和精细化。除了减少层数外,它还采用了网络剪枝和低秩近似等技术,进一步减少了每一层的参数量。TinyBERT通过层间蒸馏和数据增强来优化学生模型的训练过程,从而在更小的规模下尽量保留教师模型的性能。
- 最终模型
- DistilBERT:DistilBERT的最终模型通常较为紧凑,通常会减少一半的参数量。它在性能上与BERT相当,尤其在推理速度上表现优秀。
- TinyBERT:TinyBERT通常比DistilBERT更加精简,能够在保持较高性能的同时,进一步减少模型的大小。由于层间蒸馏的引入,TinyBERT可以保留更多来自教师模型的中间层知识,从而达到更好的性能压缩效果。
⁉️ 在NLP任务中,如何将BERT蒸馏为 TinyBERT?
在NLP任务中,如何将BERT蒸馏为 TinyBERT?
在NLP任务中,将BERT蒸馏为TinyBERT的过程可以分为两个主要步骤:预训练蒸馏(Pre-training Distillation) 和 任务蒸馏(Task-specific Distillation)。
- 预训练蒸馏(Pre-training Distillation):这个阶段的目标是通过大规模预训练来让TinyBERT模仿BERT模型的行为。我们首先使用BERT作为教师模型(Teacher Model),然后让TinyBERT(学生模型,Student Model)通过学习教师模型在每一层的输出(即隐藏状态和注意力权重)来获取知识。具体来说,这个阶段包括以下两个方面:
- 层级蒸馏(Layer-wise Distillation):将教师模型每一层的隐藏状态作为目标,优化TinyBERT的每一层输出,使其尽可能接近教师模型的输出。
- 注意力蒸馏(Attention Distillation):在BERT中,注意力机制是非常关键的部分。在这个阶段,TinyBERT将模仿教师模型的注意力模式,即教师模型的注意力权重分布,帮助学生模型更好地捕捉上下文信息。
- 任务蒸馏(Task-specific Distillation):一旦完成了预训练蒸馏,TinyBERT就会在特定任务上进行优化。任务蒸馏的目标是使TinyBERT在如文本分类(Text Classification)、序列标注(Sequence Labeling)或问答(Question Answering)等任务上达到与BERT相似的效果。具体做法是通过使用任务数据和教师模型的预测输出(如概率分布)来指导学生模型的训练。这一步通过对学生模型进行有监督学习,使其不仅模仿教师模型的结构,还能够在特定任务上优化其表现。
✅ 模型量化(Quantization)
⁉️ 什么是 LLM 中的模型量化(Quantization)?
什么是 LLM 中的模型量化(Quantization)?
LLM中的模型量化(Quantization)是一种优化技术,旨在通过降低模型权重(Weights)和激活值(Activations)的数值精度来减少计算资源消耗和存储需求,从而加速推理(Inference)并降低内存(Memory)占用。传统LLM通常使用32位浮点数(FP32)进行计算,而量化可以将其转换为16位浮点数(FP16)、8位整数(INT8)甚至更低,如4位整数(INT4),从而减少计算复杂度并提高效率。
量化方法主要包括 后训练量化(Post-Training Quantization, PTQ) 和 量化感知训练(Quantization-Aware Training, QAT)。PTQ在模型训练完成后进行量化,而QAT在训练过程中模拟低精度运算,使模型适应量化带来的精度损失(Accuracy Degradation)。此外,量化方式可以分为 对称量化(Symmetric Quantization) 和 非对称量化(Asymmetric Quantization),它们决定了如何映射数值范围以减少误差。
虽然量化可以显著提高推理速度并减少存储占用,使得LLM能够在资源受限的设备(如边缘设备或移动端)上运行,但过度量化可能会导致推理精度下降。因此,在实际应用中,需要权衡计算性能与模型精度,以选择合适的量化策略。
⁉️ 模型量化和混合精度有什么区别?
模型量化和混合精度有什么区别?
模型量化(Quantization)和混合精度训练(Mixed-Precision Training) 都是降低计算资源消耗并提高深度学习模型推理效率的技术,但它们的目标、应用阶段和方法有所不同,同时在LLM中也可以互相结合使用。
- 应用阶段不同:
- 量化(Quantization)通常用于推理(Inference)阶段,通过将权重和激活值转换为低精度数据类型(如 INT8 或 INT4)来减少计算和存储需求。
- 混合精度训练(Mixed-Precision Training)应用于训练阶段,在前向传播(Forward Pass)和反向传播(Backward Pass)过程中动态使用不同精度的数据类型,以加速训练并减少显存占用。
- 数据类型的选择:
- 量化通常采用 整数(INT8、INT4) 或低位浮点数(FP16)进行计算,以 最小化存储需求和提高计算效率。
- 混合精度训练通常使用 FP16(半精度浮点数)或BF16(Brain Floating Point 16) 与FP32(单精度浮点数)结合,在不牺牲数值稳定性的前提下加速计算。
- 目标不同:
- 量化主要用于加速推理,降低内存占用,适用于部署到低功耗设备(如移动端或嵌入式设备)。
- 混合精度训练主要用于加速训练,减少显存(VRAM)占用,使得更大的模型可以在有限的GPU资源上训练。
两者的关系:
- 可以结合使用:混合精度训练用于加速和优化训练,而训练完成后可以进一步使用量化技术来优化推理。例如,训练时采用FP16+FP32的混合精度,然后推理时再转换为INT8或INT4量化,以达到最优的计算效率。
- 量化感知训练(QAT)与混合精度训练的兼容性:在QAT中,模型在训练时模拟量化过程,使其适应INT8或更低精度的运算,而QAT本身可以结合混合精度训练,以同时优化训练效率和推理效率。
⁉️ 什么是后训练量化(PTQ)和量化感知训练(QAT)?
什么是后训练量化(PTQ)和量化感知训练(QAT)?
后训练量化(Post-Training Quantization, PTQ) 是一种在模型训练完成后进行量化的技术,主要用于 在不重新训练的情况下,将浮点权重(如FP32)转换为低精度格式(如INT8或INT4),以减少模型大小并提高推理速度。常见方法有:
- 动态量化(Dynamic Quantization):仅量化权重,而激活值在推理时仍使用FP32。适用于Transformer类模型,如BERT。
- 静态量化(Static Quantization):在量化之前使用一小部分校准数据(Calibration Data)来确定激活值的量化范围,使整个模型(包括权重和激活)都以低精度运行。
- 权重量化(Weight-Only Quantization):仅量化权重,激活值保持高精度,适用于减少存储需求但对计算影响较小的场景。
量化感知训练(Quantization-Aware Training, QAT) 是一种在 训练过程中引入量化仿真的方法,它在训练阶段就使用低精度(如INT8)进行前向传播(Forward Pass),但在反向传播(Backward Pass)时仍使用高精度浮点数(如FP32)来计算梯度,从而使模型在训练时适应量化的影响,降低精度损失。训练流程一般为:
- 初始化模型:从FP32预训练模型开始。
- 插入量化仿真模块:在前向传播时对权重和激活值应用低精度量化模拟。
- 进行标准训练:使用反向传播调整权重,以适应量化误差。
- 导出量化模型:训练完成后,生成最终的INT8或INT4量化模型。
Note:PTQ(后训练量化)适用于已训练的LLM,不需要额外训练,但可能带来一定的精度损失。
QAT(量化感知训练)需要在训练过程中引入量化,但能更好地适应低精度计算,提升推理性能,同时保持较高精度。
果部署环境受限(如移动端、边缘计算设备),QAT是更优选择,但前提是可以重新训练模型;否则,可以先使用PTQ,并在精度允许的情况下采用更低比特的量化方案。
✅ 模型剪枝(Pruning)
⁉️ 什么是 LLM 中的模型剪枝(Pruning)?
什么是 LLM 中的模型剪枝(Pruning)?
LLM中的Pruning(模型剪枝)是一种模型压缩(Model Compression)技术,旨在减少大语言模型(Large Language Model, LLM)的计算成本和存储需求,同时尽量保持其推理能力。Pruning 的核心思想是 通过删除权重较小或对最终预测贡献较低的神经网络权重(Neural Network Weights)或神经元(Neurons)来减少模型的计算复杂度。常见的剪枝方法包括权重剪枝(Weight Pruning)、结构化剪枝(Structured Pruning)和动态剪枝(Dynamic Pruning)。
- 权重剪枝(Weight Pruning):直接移除权重较小的参数,使参数矩阵变得更加稀疏(Sparse),从而减少计算量。
- 结构化剪枝(Structured Pruning):基于神经网络的结构进行剪枝,例如移除整个神经元、通道(Channels)或层(Layers),以优化计算效率。
- 动态剪枝(Dynamic Pruning):在推理过程中根据输入数据动态调整剪枝策略,使得不同输入样本激活不同的子网络(Sub-network)。
在 LLM 中,Pruning 可以结合 知识蒸馏(Knowledge Distillation)或量化(Quantization) 等技术共同优化模型,以减少推理成本,同时尽可能保持模型的性能。
模型评估与调优 #
- 评估基准(GLUE、SuperGLUE、HELM)
- 超参数搜索(Optuna、Ray Tune)
- 可解释性(Attention可视化、LIME)
- A/B Testing(A/B 测试)
- Ablation Study(消融实验):分析不同组件对整体性能的影响
- Scaling Laws(扩展定律):模型大小 vs. 数据 vs. 计算资源的关系
大规模实验设计 #
- 超参数调优(Hyperparameter Tuning)
- Learning Rate, Batch Size, Optimizer(AdamW, SGD)
- Warmup, Cosine Decay, Linear Decay
- 实验追踪(Experiment Tracking)
- Weights & Biases (W&B), MLflow
- 计算资源管理
- GPU/TPU 优化
- 训练成本 vs. 计算效率
应用开发与工程化 #
检索增强生成(RAG) #
- 向量数据库(Faiss、Pinecone、Chroma)
- 文档分块与嵌入策略(滑动窗口、语义分块)
- 检索优化(重排序、HyDE技术)
工具与框架 #
- Hugging Face Transformers库(模型加载、Pipeline、Trainer)
- LangChain(Agent、Chain、Tools设计)
- LlamaIndex(文档索引、检索增强生成RAG)
应用开发框架 #
- LangChain高级用法(自定义Tools、Agent逻辑、流式输出)
- 前端集成(Streamlit、Gradio构建交互界面)
- API开发(FastAPI/Flask构建RESTful服务)
部署与运维 #
- 容器化(Docker、Kubernetes)
- 模型部署(ONNX、TensorRT、Triton Inference Server)
- 监控与日志(Prometheus、Grafana)
- 云服务(AWS SageMaker、GCP Vertex AI)